1990年代,Netezza和Teradata使用MPP架构的数据库设备挑战了Oracle,IBM和Microsoft在分析数据库市场中的主导地位,并随着“大数据”和Hadoop与分布式处理的出现而受到严峻考验。
在本文中,我将总结架构随着时间的变化。从单台机器,SMP平台开始,然后是大规模并行处理(MPP)架构,然后是Hadoop / HDFS,以及来自Amazon,Google和Snowflake的基于云的新解决方案。
如果您没有数据库设计博士学位,则无需担心-这是一篇“纯英语”文章。
我们正在尝试解决什么问题?
从本质上讲,数据库只需要存储数据,以便以后可以检索。但是,对于大型分析平台,需要考虑许多非功能性要求:
- 性能和响应时间:通常是明显的需求:数据库必须足够快。这是一个故意含糊的定义,因为如果您正在构建在线金融交易系统,则五十毫秒的响应时间太慢了,而大多数用户只能梦想响应时间的1/20秒。通常,适当的解决方案由许多因素决定,包括预期的数据量,并发用户数以及预期的工作负载类型。例如,向50个并发用户交付批处理报告的系统与支持10,000个并发用户的Amazon风格的电子商务数据库具有不同的性能配置文件。
- 吞吐量:通常与性能混淆,它表示可以在设定时间内完成的总工作量。例如,需要转换和查询大量数据的系统需要快速处理非常大的数据量。这将导致另一种解决方案,其中优先考虑对单个查询的快速响应时间。通常,大化吞吐量的佳方法是分解大型任务并并行执行各个组件。
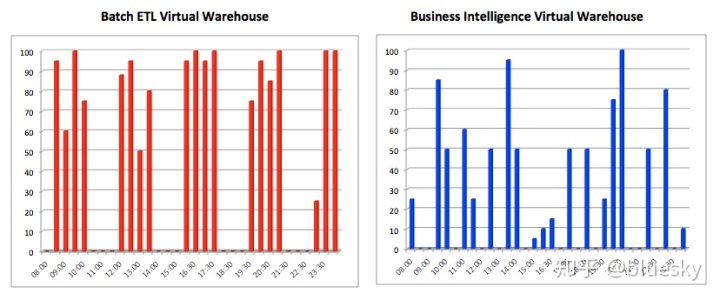
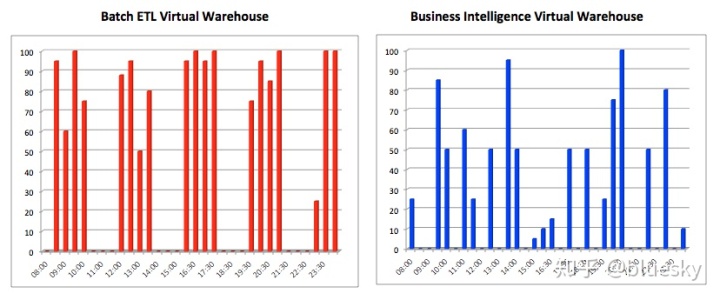
- 工作负载管理:这描述了系统在同一平台上处理混合工作负载的能力。这与性能和响应时间有关,因为大多数系统需要在两者之间找到平衡。下图说明了一种典型情况,系统必须同时处理其中吞吐量更重要的大批量批处理操作,以及对在线用户的快速响应时间。


- 可扩展性:系统必须具有增长的选项。万事俱备,如果您的应用程序成功,则数据量和用户数量都可能增长。完成后,数据库将需要处理额外的工作量。即使在这个简单的要求内,也有许多其他细节需要决定。数据量增长相对稳定还是高度不可预测?您是否可以接受停机时间以添加其他计算资源或存储,还是需要24x7全天候运行?
- 并发:描述系统可以同时支持多个用户的程度。这与可伸缩性和性能有关,因为系统必须足够快才能快速响应,而且还必须处理所需数量的并发用户,而响应时间不会显着减少。同样,如果用户数量超过预定义的限制,我们需要考虑哪些选项可用于扩展系统。这突出了可伸缩性的重要区别。随着用户数量的增加,处理不断增加的数据量所面临的挑战与维护响应时间所面临的挑战截然不同。正如我们稍后会看到的-一种尺寸无法容纳所有尺寸。
- 数据一致性:虽然以前的要求可能很明显,但是对一致性的需求是一个更加细微的要求,并且可能会假设您当然需要数据一致性。但是,实际上,对数据一致性的需求是灵活的,并且(例如)在线银行系统可能需要100%保证的一致性,而对于提供管理的报告系统,一致性和的准确性可能不那么重要。报告。数据一致性是一个重要的考虑因素,因为它可能会排除无法保证一致性的NoSQL数据库解决方案的使用。
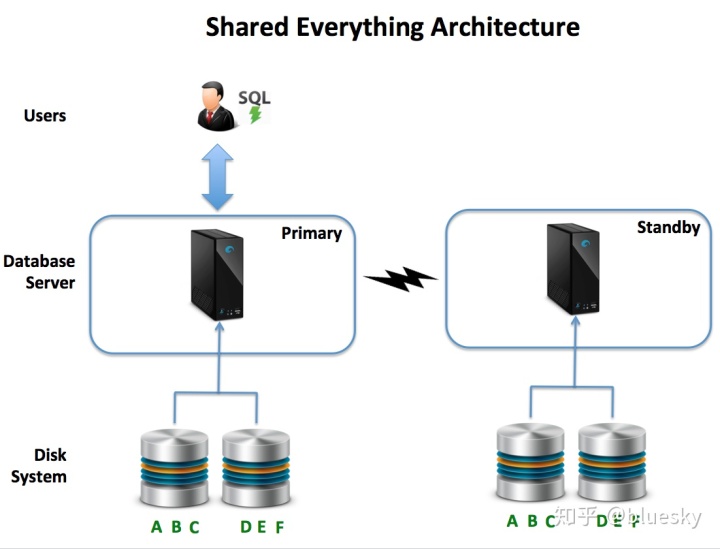
- 弹性和可用性:描述了数据库在组件,机器甚至整个数据中心发生故障时仍能够继续运行的能力,而弹性的水平则取决于对可用性的需求。例如,在线银行系统可能需要在99.999%的时间内可用,这每年可能导致超过五分钟的停机时间。这意味着解决方案具有高度的弹性(并且可能很昂贵),而允许周末停机的系统具有更多可用选项。下图说明了一种常见的解决方案,通过该解决方案,写入主系统的事务将自动复制到内置了自动故障转移功能的非现场备用系统。


- 可通过SQL进行访问:尽管不是要求,但SQL语言已经存在了40多年,并且已被数百万开发人员,分析师和业务用户使用。尽管如此,某些NoSQL数据库(例如HBase和MongoDB)本身并不支持使用SQL进行访问。尽管有几种可用的附加工具,但是这些数据库与更常见的关系数据库在根本上是不同的,并且(例如)不支持关系联接,事务或即时数据一致性。
选项1:SMP硬件上的关系数据库
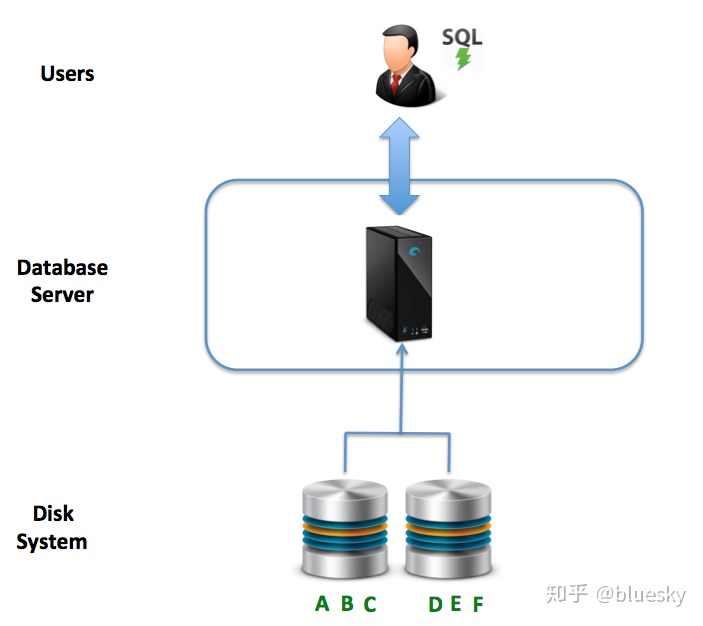
自1980年代初以来,甲骨文,微软和IBM一直在市场上占据主导地位,他们提供了旨在满足上述要求的通用解决方案。底层硬件和数据库系统体系结构早是在1970年代开发的,它基于对称多处理(SMP)硬件,其中许多物理处理器(或内核)使用共享内存和磁盘执行指令。


上面的屏幕截图显示了Windows任务管理器,其中显示了八个处理器在SMP数据库服务器上执行指令。基于SMP的数据库解决方案具有以下优点和缺点:
优点
- 它的工作原理:这是一个经过艰苦努力,久经考验的体系结构,部署成本相对较低,并且可以在从大型服务器到中型商品硬件的所有内容上运行。它在提供合理的性能和吞吐量方面有着良好的记录。
- 这是同质的:这意味着为该平台设计的数据库几乎可以在任何硬件上运行。由于它基于多个内核,因此可以是物理或逻辑的,这也是在云平台上的虚拟服务器上运行的一种选择。
- 数据一致性:下图说明了此体系结构的本质-将一台计算机连接到本地或网络连接的磁盘。实际上,数据只有一个副本,因此,数据一致性不是挑战。它在分布式系统上。与许多NoSQL解决方案相比,后者以大的响应时间来交换数据不一致的风险。
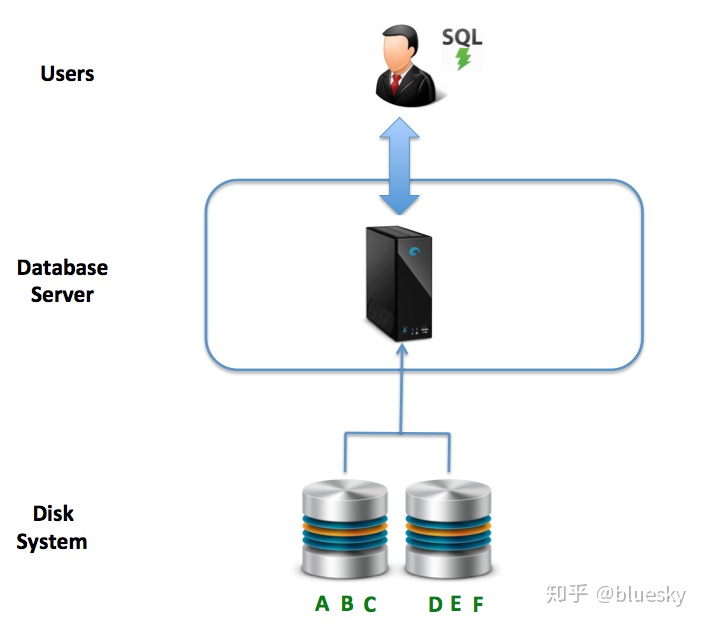
缺点
尽管这是一种流行且已广泛部署的体系结构,但它确实具有以下缺点:
- 难以扩展:虽然可以添加CPU,内存或其他磁盘,但实际上可扩展性是有限的,并且很可能在几年内需要用更大的机器来替换系统。
- 大规模化:由于难以扩展,大多数架构师将SMP平台的大小调整为大的预期工作量。这意味着要付出比初所需更多的处理能力,而随着时间的推移,随着负载的增加,性能会逐渐下降。更好的解决方案将允许随着时间的推移逐渐增加计算资源。
- 扩展效率低下:很少增加或更快地增加CPU的线性性能。例如,除非系统完全与CPU绑定,否则增加100%更快的处理器将使性能提高一倍的可能性很小。在大多数情况下,瓶颈转移到另一个组件,并且线性增加容量是不可能的。
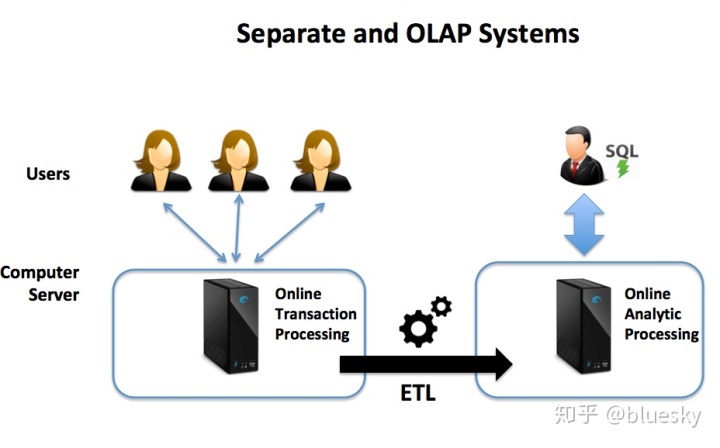
- 工作负载管理:基于数据库解决方案和硬件,基于SMP的系统可以提供合理的性能或吞吐量-很少同时出现。与MPP平台一样,许多解决方案都在努力平衡快速响应时间和高批处理吞吐量的竞争需求。下图说明了一种通用方法,通过该方法,面向客户的在线事务处理(OLTP)系统可以提供快速的响应时间,同时可以定期将数据传递到用于在线分析处理(OLAP)的单独的数据仓库平台。尽管甲骨文声称要解决使用Oracle12c在内存中组合OLTP和OLAP的难题,但实际上,这仅限于中小型应用程序。

- 弹性和可用性:由于SMP系统使用单个平台,因此需要扩展解决方案以在组件或整个数据中心发生故障时提供弹性。尽管从理论上讲,它可以部署在廉价的商用服务器上,但实际上,它通常部署在具有双冗余磁盘,网络连接和电源的企业级硬件上,这通常会使该选项变得昂贵。尽管这可以提供对组件故障的恢复能力,但该解决方案还需要一个单独的备用系统来保证高可用性。
选项2:MPP硬件上的关系数据库
1984年,Teradata交付了使用大规模并行处理(MPP)架构的个生产数据库,两年后,《福布斯》杂志将Teradata评为“年度产品”,因为它生产了个TB级的生产数据库。Netezza,Microsoft并行数据仓库(PDW)和HP Vertica等后来采用了这种体系结构。如今,Apple,Walmart和eBay 经常在MPP平台上存储和处理 PB的数据。
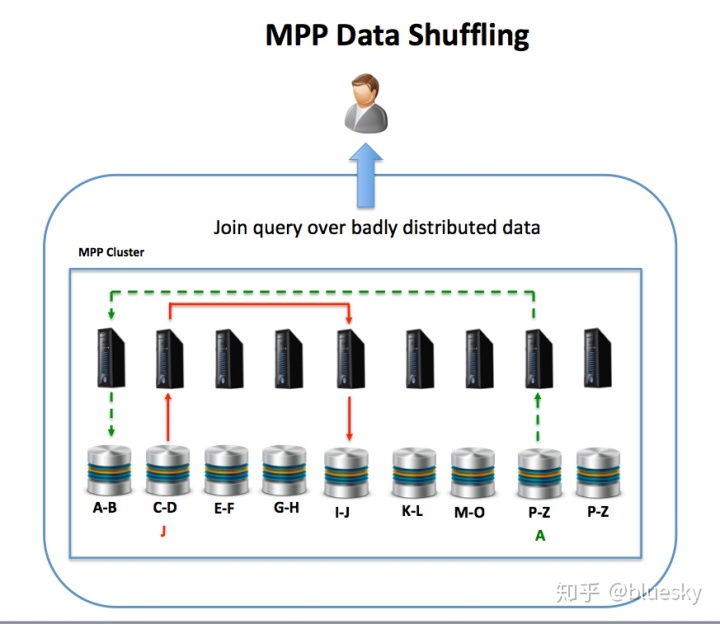
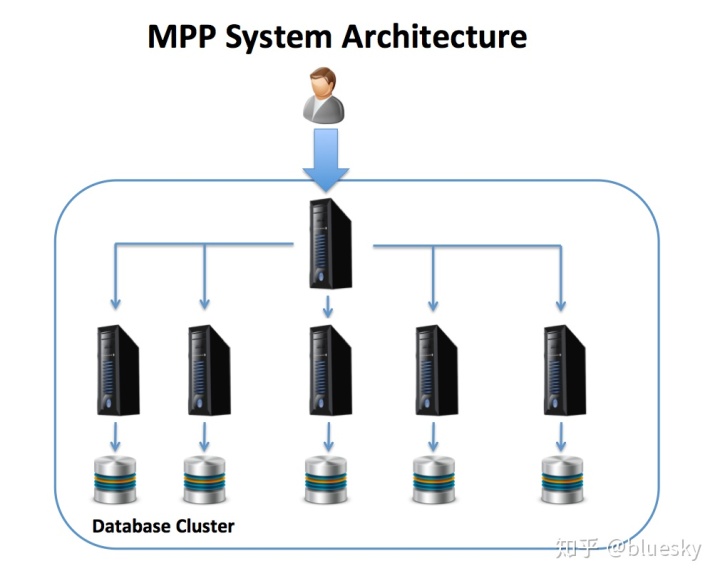
下图说明了MPP体系结构,协调SMP服务器通过该结构接受用户SQL语句,这些语句分布在许多独立运行的数据库服务器中,这些数据库服务器一起充当单个群集计算机。每个节点都是一台单独的计算机,具有自己的CPU,内存和直接连接的磁盘。
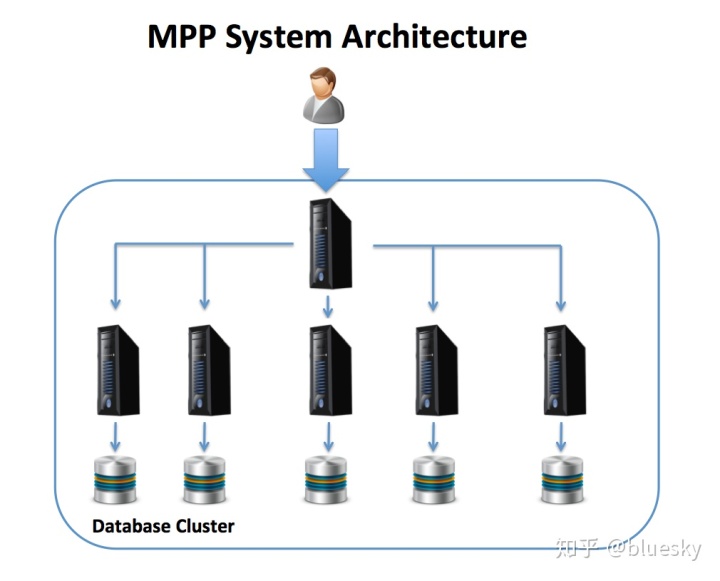

使用此解决方案,在加载数据时,可以使用一致的哈希算法来均匀地分布数据,这(如果一切顺利的话)将导致整个集群的工作平衡分配。MPP体系结构是数据仓库和分析平台的出色解决方案,因为查询可以分解为多个组成部分,并在服务器之间并行执行,从而显着提高性能。
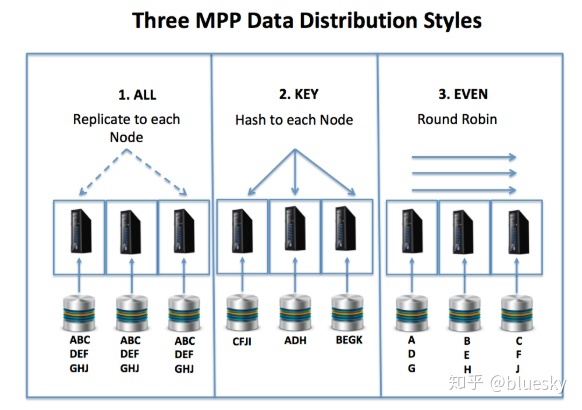
但是,与SMP系统不同,在SMP系统中,数据的放置是在磁盘级别自动进行的,正确地执行此步骤以大化吞吐量和响应时间至关重要。下图说明了三种可用的MPP数据分发方法。


选项包括:
- 复制:通常用于较小的表,使用此方法,可在集群中的每个节点上复制数据。尽管这似乎是浪费的,但我自己在数个兆兆字节的仓库中的经验表明,经常存在大量的小型参考和维表,这些表通常与非常大的事务或事实表结合在一起。此参考数据非常适合复制方法,因为它意味着可以在群集中的每个节点上本地和并行地加入它,从而避免了节点之间的数据混排。
- 一致哈希:通常用于较大的事务或事实表,并且涉及生成可复制的密钥,以将每一行分配给集群中的适当服务器。此方法可确保群集上的负载均匀,尽管错误选择群集密钥可能会导致热点,在某些情况下可能会严重限制性能。
- 循环:此方法涉及以循环方式在下一个节点上依次写入每一行,通常仅用于临时登台表,该临时登台表将仅被写入和读取一次。它的优点是保证数据均匀地分布,因此也保证了查询负载,但是除非所有相关的参考数据表都复制到每个节点,否则这是一个糟糕的解决方案。
优点
与SMP解决方案相比,MPP体系结构具有几个明显的优势,其中包括:
- 性能:这是MPP系统真正可以超越的领域。所提供的数据和处理可以在群集中的各个节点之间并行并行执行,即使在大的SMP服务器上,性能提升也非常可观。
“通过大规模并行处理(MPP)设计,查询完成通常比基于对称多处理(SMP)系统构建的传统数据仓库快50倍”。–微软公司。
- 可扩展性和并发性:与SMP解决方案不同,基于MPP的系统可以选择增量添加计算和存储资源,并且以算术速率大大提高了吞吐量。添加其他相同大小的节点可提高系统处理其他查询的能力,而不会显着降低性能。
- 成本和高可用性:一些基于MPP的数据仓库解决方案旨在在廉价的商品硬件上运行,而无需企业级的双重冗余组件,而这些组件可能会包含成本。这些解决方案通常使用自动数据复制来提高系统弹性并保证高可用性。这可以极大地提高资源的利用率,并且避免了许多基于SMP的解决方案所使用的大量未使用的热备用的成本。
- 读取和写入吞吐量:随着数据在系统中的分布,该解决方案可以实现显着水平的吞吐量,因为可以在集群中的独立节点之间并行执行读取和写入操作。
缺点
尽管MPP系统相对于传统SMP体系结构具有令人信服的优势,但它们确实具有以下缺点:
- 复杂性和成本:虽然表面上看起来体系结构很简单,但精心设计的MPP解决方案却隐藏了相当大的复杂性,而Teradata和Netezza早的商业MPP数据库系统是作为硬件设备交付的,成本很高。但是,随着这种架构在大规模分析平台上变得越来越流行,价格开始降低。
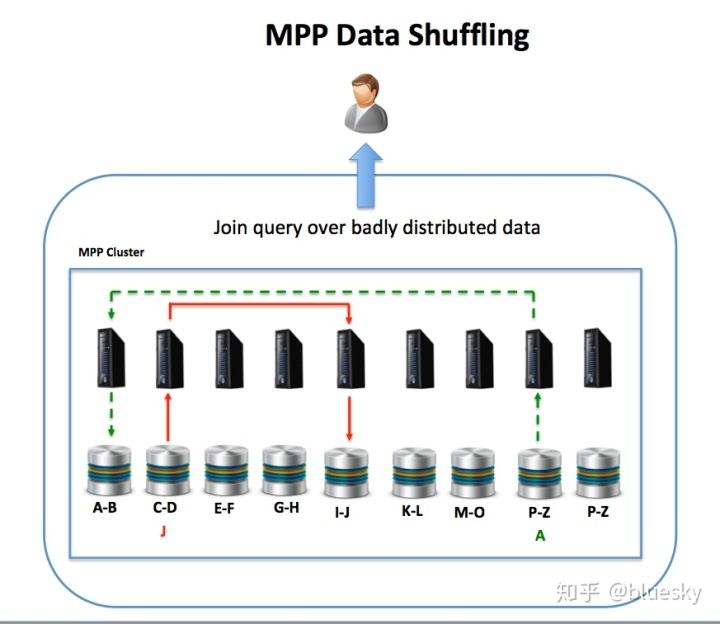
- 数据分发至关重要:不同于SMP解决方案中的磁盘级数据放置简单并且可以自动化,MPP平台需要精心设计数据分发,以避免数据偏斜导致处理热点。例如,如果选择了较差的分发密钥,则可能导致少量节点过载,而其他节点处于空闲状态,这将限制总体吞吐量和查询响应时间。同样,如果未正确将参考表与关联的事务数据放置在一起,则可能导致过多的数据改组从而在节点之间传输数据以完成联接操作,这又可能导致性能问题。如下图所示,在两个节点之间对参考数据进行了混洗。虽然可以解决问题,但通常需要进行大量的数据重组工作,并可能导致系统停机。
- 停机需求:尽管某些MPP解决方案内置了弹性和高可用性,但许多解决方案都需要停机或降低性能来支持添加新节点。在某些情况下,必须使整个群集脱机以添加其他节点,即使不需要这样做,添加节点通常也涉及跨群集重新分配数据以利用其他计算资源。对于某些客户来说,这可能不是理想的选择,甚至是不可行的选择。
- 缺乏弹性:尽管可以扩展MPP系统,但这通常涉及新硬件的调试和部署,这可能需要几天甚至几周才能完成。这些系统通常不支持弹性-可以按需扩展或减少计算资源以满足实时处理要求的能力。
- 仅横向扩展:为避免系统失衡,通常仅明智的做法是添加规格,计算能力和磁盘存储完全相同的节点。这意味着,尽管添加其他节点会增加并发性(其他用户查询数据的能力),但无法显着提高批处理吞吐量。简而言之,尽管可以扩展,但几乎没有其他选择可以将解决方案扩展到功能更强大的系统。
- 潜在的超容量:从理论上讲,MPP系统是完美平衡的,因为其他节点会向群集添加存储和计算资源。但是,由于这些关系紧密联系在一起,因此,如果存储需求超出了对计算容量的需求,那么总拥有成本可能会非常巨大,因为每TB的成本成比例地增加。这在Data Lake解决方案的普及中尤其普遍,该解决方案可能存储大量不经常访问的数据。总之,使用纯MPP解决方案,您可能需要为计算处理支付比实际需要多300倍的费用。
“在分析MPP平台上,数据量[可能]与分析工作负载成比例的增长(我们的研究表明,在某些情况下,差异高达300:1)”-CTO Clarity Insights首席技术官Tripp Smith。
选项3:带有SQL over HDFS的Hadoop
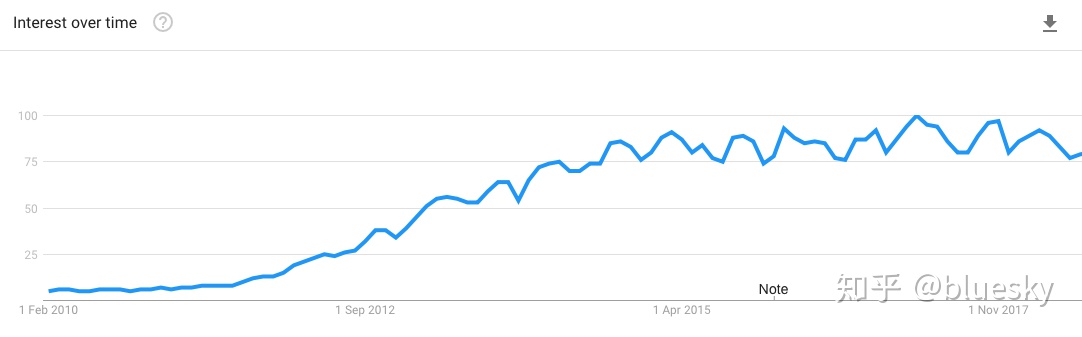
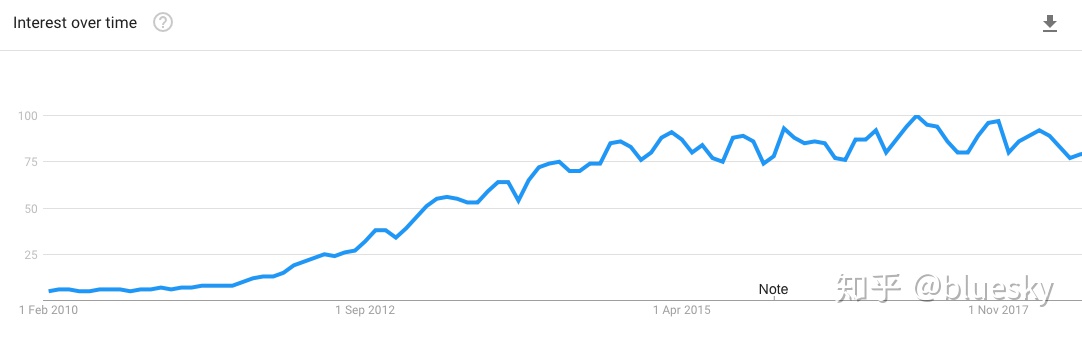
下图说明了2010-15年间对大数据的兴趣增长势不可挡。这显然与数据库供应商有关,包括成为Hadoop平台供应商的IBM 和开发大数据设备的 Oracle 。
在这段时间里,尽管普遍的共识似乎表明Hadoop充其量是数据仓库的一种补充技术,但有关数据仓库是否已失效以及Hadoop是否将取代 MPP平台的讨论很多。不能替代它。
什么是Hadoop?
与作为开源数据库的MySQL和PostgreSQL不同,Hadoop不是单个产品,而是相关项目的开源生态系统。截至2018年9月,这包括150多个项目 ,其中包含12个单独的工具用于Hadoop上的SQL和17个数据库。为了说明生态系统的规模,亚马逊英国公司出售了超过1000本有关Hadoop技术的书籍,其中许多仅涵盖一个工具,包括750多页的《 Hadoop权威指南》。
下图说明了一些关键组件和Hadoop发行商,并且每个组件都需要大量时间和专业知识才能充分利用。


主要用例
Hadoop是一个庞大的主题,很难在简短的文章中进行总结,但是它解决的主要问题空间包括:
- 大容量数据存储和批处理: Hadoop和主数据存储系统(Hadoop分布式文件系统— HDFS)通常被推广为廉价的数据存储解决方案和适用于Data Lake的平台。鉴于其能够扩展到数千个节点的能力,它可能非常适合使用基于SQL的工具Apache Hive over HDFS 进行大规模批处理数据处理。
- 实时处理:尽管HDFS适合运行数小时的大规模批处理,但其他组件(包括Kafka,Spark Streaming,Storm和Flink)经过专门设计,可提供微批处理或实时流解决方案。随着物联网(IoT)行业越来越多地提供数百万个需要实时或近实时数据分析和响应的嵌入式传感器的实时结果,这一点有望变得越来越重要。
- 文本挖掘和分析: Hadoop平台的另一个强项是能够处理包括文本在内的非结构化数据。尽管传统的数据库可以很好地处理行和列中的结构化数据,但是Hadoop包含了用于分析非结构化文本字段含义的工具,例如,在线产品评论或可用于情感分析的Twitter feed。
上面的用例通常描述为三个V:DataVolume,Velocity和Variety。
Hadoop / HDFS架构
作为本文重点介绍数据库体系结构,我将重点介绍批处理用例。我在“ 大数据:普通英语的速度”一文中单独描述了潜在的实时处理架构。
乍一看,Hadoop / HDFS架构似乎与MPP架构相似,下图说明了相似之处。
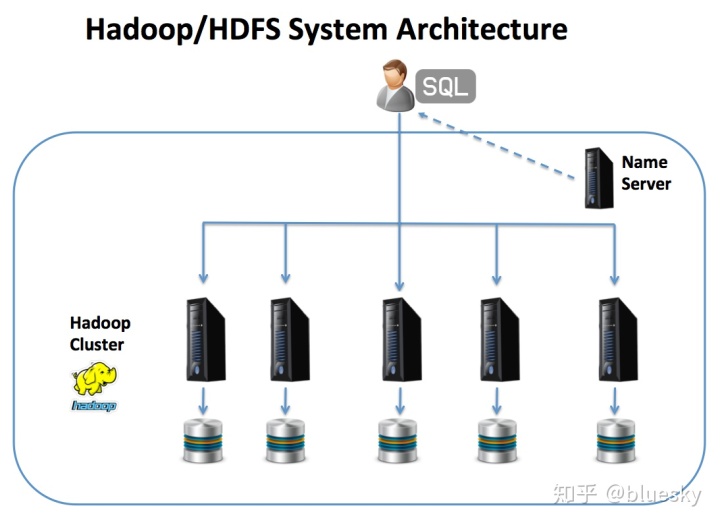
上图显示了如何正常使用SQL处理数据。的名称服务器充当目录查找服务给客户端指向时将被存储或从查询的数据的节点(S),否则,它看起来非常类似于一个MPP架构。
但是,大的单一差异是,尽管MPP平台在群集中分布了单独的行,但是Hadoop只是将数据分为任意块, Cloudera建议将其大小设为128Mb,然后将其复制到至少两个其他节点以实现弹性。如果发生节点故障。
这很重要,因为这意味着小文件(小于128Mb的文件)完全保存在单个节点上,甚至一个千兆字节的文件也将仅分布在8个节点(加上副本)上。这很重要,因为Hadoop旨在处理非常大的数据集和大型集群。但是,由于小表分布在较少的服务器上,因此它对于50-100Gb以下的数据文件不是理想的选择。
在Hadoop上处理小数据集是一个挑战,因为在更坏的情况下,在单个节点上处理数据完全按顺序运行,而没有并行运行。确实,由于许多Hadoop群集倾向于使用大量相对较慢且价格便宜的商品服务器,因此小数据的性能确实可能非常差。此外,随着小文件数量的增加,名称服务器的管理问题也越来越多。
为了说明这一点,我的经验表明,在大多数中型数据仓库平台(大约10Tb的数据)上,只有大约10%的表拥有超过100Gb的数据,而70%的表则拥有不足1Gb的数据。即使两个大的表的大小超过1Tb,这对于在Hadoop上的部署也特别不利。
“大多数希望Hadoop取代其企业数据仓库的人都感到非常失望” -James Serra-微软
优点
Hadoop / HDFS体系结构作为数据存储和处理平台具有以下优势:
- 批处理性能:尽管处理使用蛮力方法,需要跨多个节点并行执行作业,但Hadoop是处理超大型数据集时实现高吞吐量的选择。
- 可扩展性:与MPP系统类似,可以添加其他节点来扩展Hadoop集群,并且集群可以达到上限。在某些情况下为5,000个节点。
- 可用性和弹性:由于数据被自动复制(复制)到多台服务器,因此弹性和高可用性都是透明的并且是内置的。这意味着(例如)生产中可以使节点脱机以进行维护而不会中断服务。
- 成本(硬件和许可证):由于Hadoop倾向于部署在运行开源软件的廉价商品服务器上,因此硬件和许可证的成本可以大大低于传统的企业级数据仓库设备以及相关的许可证成本。
缺点
由于引人注目的成本和批处理性能优势,Hadoop经常被提倡替代数据仓库。但是,出于以下原因,我建议您谨慎:
- 管理复杂性:如上所述,Hadoop并不是一个单一的产品,而是一个庞大的软件生态系统,部署通常需要对一系列工具的熟练知识,包括HDFS,Yarn,Spark,Impala,Hive,Flume,Zookeeper和Kafka。对于整个业务都在管理数据的组织(例如Facebook或LinkedIn),Hadoop可能是一个明智的选择。但是,对于许多客户而言,好避免使用支持数据库解决方案的分析平台。甚至大型MPP解决方案的部署和维护都比Hadoop复杂得多。
- 不成熟的查询工具:关系数据库管理系统在自动查询调整方面具有数十年的经验,可以有效地执行复杂的SQL查询。但是,大多数基于Hadoop的SQL工具无法达到所需的复杂程度,并且通常依靠蛮力来执行查询。这导致机器资源的使用效率极低,而基于云的资源(即付即用)很快会变得昂贵。
- 小文件问题:虽然在完全并行执行时非常大的数据处理的吞吐量可以提高效率,但是处理相对较小的文件可能会导致非常差的查询响应时间。
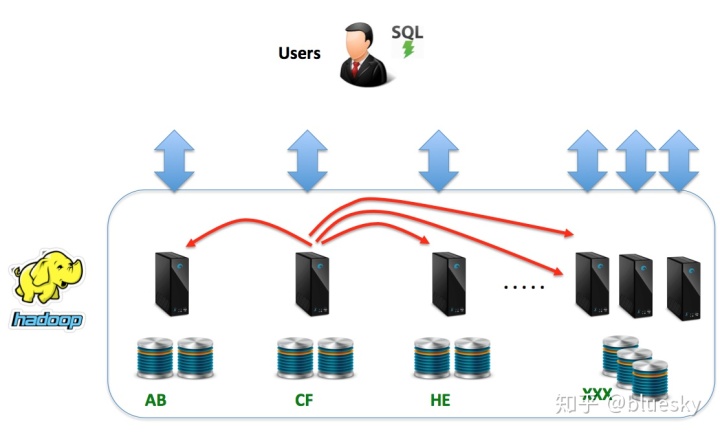
- 数据改组:与MPP解决方案不同,在该解决方案中,可以通过一致的哈希键或数据复制将数据放置在同一位置,因此没有选择将数据放置在Hadoop节点上。这意味着跨多个表(通过设计)随机分布在整个集群中的联接操作可能导致大量的数据改组工作,并可能导致严重的性能问题。如下图所示。
- 低延迟查询性能较差:尽管数据缓存解决方案可能会有所帮助,但是Hadoop / HDFS对于低延迟查询(例如,将数据提供给仪表板)来说是非常差的解决方案。同样,这与该体系结构初设计为使用蛮力批处理处理非常大的数据集有关。
- 其他缺点:与在MPP平台下描述的缺点类似,此解决方案还缺乏弹性,无法扩展,并且潜在地存在计算资源的极端过剩的潜力,尤其是在用作数据湖时。
要获得关于Hadoop为什么不适用于市场的出色解决方案的精彩演讲,请观看图灵奖获得者Michael Stonebraker博士的演讲- 大数据(至少)是四个不同的问题。
选项4:EPP:弹性并行处理
与MPP解决方案相似,在该解决方案中,许多独立运行的无共享节点并行存储和处理查询,EPP(弹性并行处理)体系结构提供了令人印象深刻的可伸缩性。
但是,与将数据存储直接附加到每个节点的MPP群集不同,EPP体系结构将计算和存储分开,这意味着每个节点都可以独立扩展或弹性缩减。
如下图所示:
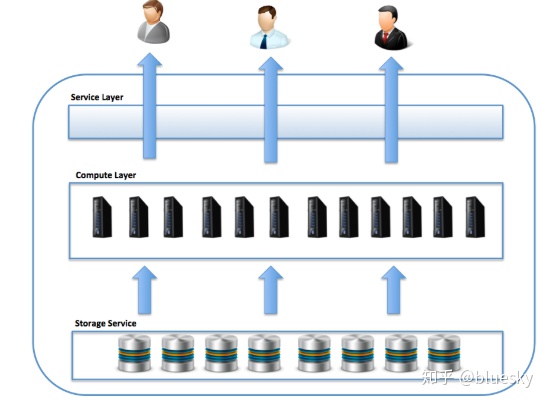
在上图中,长期存储由存储服务提供, 从群集中的每个节点都可以看到。查询将提交给服务层,该服务层 负责总体查询协调,查询调优和事务管理,并且实际工作在计算层上 有效执行,即有效的MPP集群。
尽管计算层通常具有直接连接的磁盘或快速SSD用于本地存储,但是使用独立的存储服务层意味着可以独立于计算容量来扩展数据存储。这意味着可以弹性调整计算群集的大小,在提供MPP体系结构所有优点的同时,还可以消除许多缺点。
截至2018年,有几种分析平台(在不同程度上)可以描述为支持弹性并行处理,其中包括Snowflake Computing,Microsoft,HP,Amazon和Google的解决方案。
“新的云架构和基础架构挑战了有关大数据以及并置存储和计算的传统思维”。-Tripp Smith – CTO Clarity Insights。
snowflake:弹性数据仓库
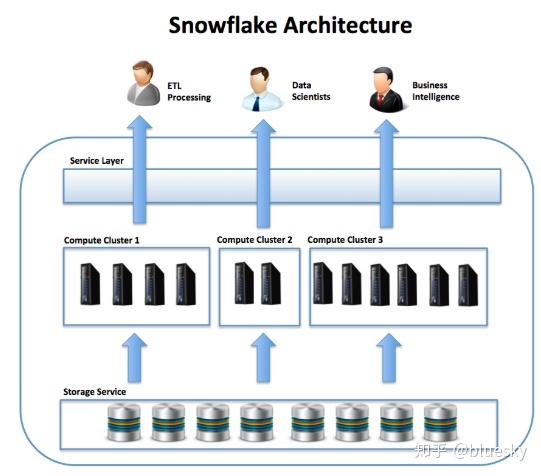
在雪花弹性数据仓库是目前真正的弹性EPP分析平台的目前好的例子,本节将介绍该解决方案的好处。
下图说明了Snowflake数据仓库即服务解决方案的独特优势之一。代替在共享存储服务上支持单个MPP群集,可以启动多个独立的计算资源群集,每个群集的大小和操作均独立进行,但可以从公用数据存储中加载和查询数据。
它提供的巨大优势之一是非凡的敏捷性,其中包括可以选择按需立即启动,暂停或调整任何集群的大小,而停机时间为零或对当前执行的工作负荷没有影响。根据需要,在调整大小(较大或较小)的群集上会自动启动新查询。
下图说明了另一个关键优势,即可以在同一个共享数据存储上独立执行潜在竞争的工作负载,而大吞吐量工作负载与低延迟,针对相同数据的快速响应时间查询并行运行。只有通过在单个共享数据存储上运行多个计算资源的独特能力,才有可能这样做。
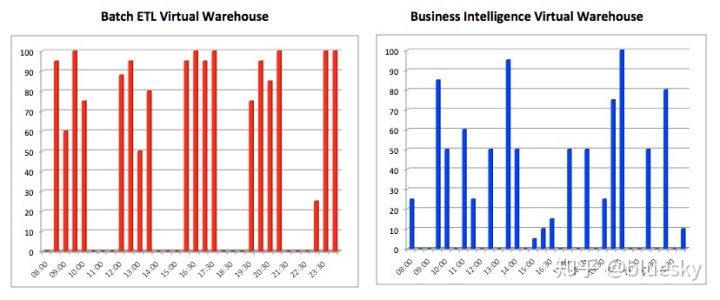
由于Snowflake可以部署多个独立的计算资源集群,因此您几乎可以在其他所有SMP,MPP或EPP系统上找到的低延迟和高吞吐量工作负载之间无需费力。这意味着您可以在与批量ETL加载完全相同的数据上,通过密集的数据科学操作来运行真正混合的工作负载,同时还可以将不到一秒的响应时间传递给业务用户仪表板。如下图所示:

后,由于存在多个集群,因此可以即时扩展和扩展解决方案,而不会造成任何停机时间或对性能的影响。与某些EPP解决方案不同,Snowflake具有真正的弹性,可以从双节点群集增长到128节点群集,然后再返回,而不会中断服务。
优点
EPP解决方案具有与上述MPP体系结构类似的优点,但没有许多缺点。这些包括:
- 可扩展性和并发性:除了具有扩展能力之外,EPP系统还可以通过添加其他计算节点进行扩展,以执行要求越来越高的工作负载,或者添加其他相同大小的节点来维护并发性,同时增加用户数量。
- 成本和高可用性:某些EPP解决方案可以部署在本地,混合或云环境中。无论哪种方式,都可以将解决方案配置为在需要时通过自动故障转移来提供高可用性。如果部署到云环境中,还可以选择关闭或暂停数据库以控制成本,并在需要时重新启动。
- 读取和写入吞吐量:由于EPP系统实际上是具有单独的计算和存储的MPP解决方案,因此在吞吐量方面,它们具有与MPP相同的优点,但还具有可伸缩性和弹性的其他优点。
- 数据分发的重要性不那么严格:在某些情况下(例如Snowflake),在处理非常大的数据集(超过TB数据集)时,可以选择数据分发以大化吞吐量,而在其他平台(例如Microsoft或Amazon Redshift)上,数据分发则更为重要设置正确的分发密钥以避免数据改组很重要。
- 潜在的零停机时间:与通常需要停机以调整群集大小的MPP解决方案不同,EPP解决方案可以(例如使用Snowflake)在停机时间为零的情况下即时扩展或缩减群集的大小。除了自动添加或删除节点以自动调整所需的并发级别外,还可以根据需要增加或缩小计算资源。在其他解决方案(例如Redshift)上,系统需要在调整大小操作期间重新引导至只读模式。
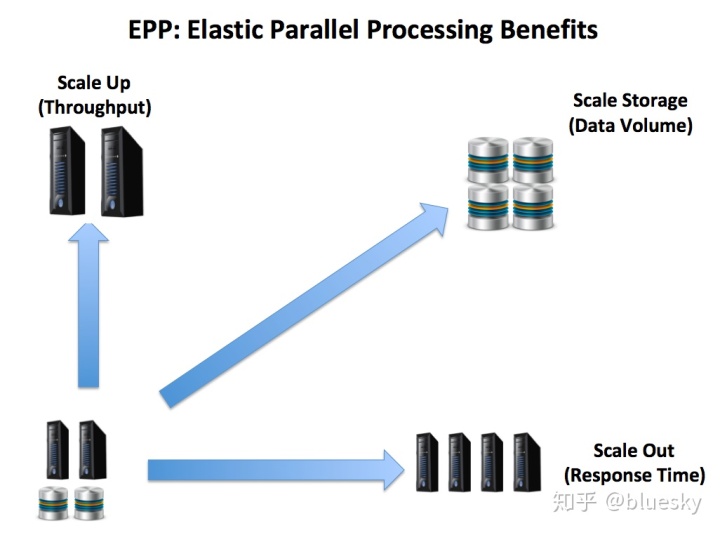
- 扩展所有三个维度:与MPP解决方案通常仅支持横向扩展(添加相同大小的节点)不同,EPP解决方案可以独立扩展计算和存储。此外,可以扩展到更大(更强大)的群集,或者从群集中添加或删除节点。下图说明了此体系结构在三个维度上扩展的独特能力。这表明可以扩展群集以大程度地提高吞吐量,可以扩展群集以在添加其他用户(并发)时保持一致的响应时间,或者通过添加数据存储来扩展群集。
- 合适大小的硬件和存储:与SMP系统(大小通常不灵活)以及Hadoop和MPP解决方案(都有可能过度配置计算资源)不同,EPP平台可以进行调整以适应问题的大小。这意味着可以将小型群集安装在PB的数据上,也可以将大型功能强大的系统根据需要在较小的数据集上运行。
总结与结论
本文总结了用于支持大型分析或商业智能平台的主要硬件体系结构,包括SMP(具有多个处理器的单节点),MPP(具有并行数据加载和分布式查询处理的多个节点)以及EPP(弹性并行处理)解决了MPP平台的许多缺点,并支持真正的弹性和敏捷性。
许多数据库供应商已经部署或开发了EPP架构的解决方案,包括Amazon Redshift,Google BigQuery,HP Vertica和Teradata,尽管到目前为止,只有一个解决方案Snowflake具有零停机时间解决方案,可提供完全的弹性和按需的灵活性。使用多个独立的集群。
尽管Hadoop可能声称对传统数据库提出了挑战,但实际上,系统复杂性和计算过量配置的缺点使它对于分析平台来说是一个糟糕的解决方案。但是,Hadoop确实提供了一个出色的框架来提供实时处理和文本分析。
无论哪种方式,我都坚信敏捷性和成本控制的显着优势将意味着越来越多的所有分析,实际上所有计算处理终都将在云中执行。我还认为,EPP体系结构是支持分析工作负载的佳方法,尤其是在基于云的情况下。
