为什么使用SpringBoot整合kafka和storm
一般而言,使用kafka整合storm可以应付大多数需求。但是在扩展性上来说,可能就不太好。目前主流的微服务框架SpringCloud是基于SpringBoot的,所以使用SpringBoot对kafka和storm进行整合,可以进行统一配置,扩展性会更好。
使用SpringBoot整合kafka和storm做什么
一般来说,kafka和storm的整合,使用kafka进行数据的传输,然后使用storm实时的处理kafka中的数据。了解springcloud架构可以加求求:三五三六二四七二五九
在这里我们加入SpringBoot之后,也是做这些,只不过是由SpringBoot对kafka和storm进行统一的管理。
如果还是不好理解的话,可以通过下面这个简单的业务场景了解下:
在数据库中有一批大量的用户数据,其中这些用户数据中有很多是不需要的,也就是脏数据,我们需要对这些用户数据进行清洗,然后重新存入数据库中,但是要求实时、延时低,并且便于管理。
所以这里我们就可以使用SpringBoot+kafka+storm来进行相应的开发。
开发准备
在进行代码开发前,我们要明确开发什么。 在上述的业务场景中,需要大量的数据,但是我们这里只是简单的进行开发,也就是写个简单的demo出来,能够简单的实现这些功能,所以我们只需满足如下条件就可以了:
提供一个将用户数据写入kafka的接口;
使用storm的spout获取kafka的数据并发送给bolt;
在bolt移除年龄小于10岁的用户的数据,并写入mysql;
那么根据上述要求我们进行SpringBoot、kafka和storm的整合。 首先需要相应jar包,所以maven的依赖如下:
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<java.version>1.8</java.version>
<springboot.version>1.5.9.RELEASE</springboot.version>
<mybatis-spring-boot>1.2.0</mybatis-spring-boot>
<mysql-connector>5.1.44</mysql-connector>
<slf4j.version>1.7.25</slf4j.version>
<logback.version>1.2.3</logback.version>
<kafka.version>1.0.0</kafka.version>
<storm.version>1.2.1</storm.version>
<fastjson.version>1.2.41</fastjson.version>
<druid>1.1.8</druid>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>${springboot.version}</version>
</dependency>
<!-- Spring Boot Mybatis 依赖 -->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>${mybatis-spring-boot}</version>
</dependency>
<!-- MySQL 连接驱动依赖 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql-connector}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>${logback.version}</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-core</artifactId>
<version>${logback.version}</version>
</dependency>
<!-- kafka -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.12</artifactId>
<version>${kafka.version}</version>
<exclusions>
<exclusion>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
</exclusion>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
<exclusion>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
</exclusion>
</exclusions>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>${kafka.version}</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>${kafka.version}</version>
</dependency>
<!--storm相关jar -->
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>${storm.version}</version>
<!--排除相关依赖 -->
<exclusions>
<exclusion>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
</exclusion>
<exclusion>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-1.2-api</artifactId>
</exclusion>
<exclusion>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-web</artifactId>
</exclusion>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
<exclusion>
<artifactId>ring-cors</artifactId>
<groupId>ring-cors</groupId>
</exclusion>
</exclusions>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-kafka</artifactId>
<version>${storm.version}</version>
</dependency>
<!--fastjson 相关jar -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>${fastjson.version}</version>
</dependency>
<!-- Druid 数据连接池依赖 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>${druid}</version>
</dependency>
</dependencies>成功添加了相关依赖之后,这里我们再来添加相应的配置。 在application.properties中添加如下配置:
# log
logging.config=classpath:logback.xml
## mysql
spring.datasource.url=jdbc:mysql://localhost:3306/springBoot2?useUnicode=true&characterEncoding=utf8&allowMultiQueries=true
spring.datasource.username=root
spring.datasource.password=123456
spring.datasource.driverClassName=com.mysql.jdbc.Driver
## kafka
kafka.servers = 192.169.0.23\:9092,192.169.0.24\:9092,192.169.0.25\:9092
kafka.topicName = USER_TOPIC
kafka.autoCommit = false
kafka.maxPollRecords = 100
kafka.groupId = groupA
kafka.commitRule = earliest注:上述的配置只是一部分,完整的配置可以在我的github中找到。
数据库脚本:
- springBoot2库的脚本
CREATE TABLE `t_user` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '自增id',
`name` varchar(10) DEFAULT NULL COMMENT '姓名',
`age` int(2) DEFAULT NULL COMMENT '年龄',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=15 DEFAULT CHARSET=utf8注:因为这里我们只是简单的模拟一下业务场景,所以只是建立一张简单的表。
代码编写
说明:这里我只对几个关键的类进行说明,完整的项目工程链接可以在博客底部找到。
在使用SpringBoot整合kafka和storm之前,我们可以先对kfaka和storm的相关代码编写,然后在进行整合。
首先是数据源的获取,也就是使用storm中的spout从kafka中拉取数据。
在之前的storm入门中,讲过storm的运行流程,其中spout是storm获取数据的一个组件,其中我们主要实现nextTuple方法,编写从kafka中获取数据的代码就可以在storm启动后进行数据的获取。
spout类的主要代码如下:
# log
logging.config=classpath:logback.xml
## mysql
spring.datasource.url=jdbc:mysql://localhost:3306/springBoot2?useUnicode=true&characterEncoding=utf8&allowMultiQueries=true
spring.datasource.username=root
spring.datasource.password=123456
spring.datasource.driverClassName=com.mysql.jdbc.Driver
## kafka
kafka.servers = 192.169.0.23\:9092,192.169.0.24\:9092,192.169.0.25\:9092
kafka.topicName = USER_TOPIC
kafka.autoCommit = false
kafka.maxPollRecords = 100
kafka.groupId = groupA
kafka.commitRule = earliest注:上述的配置只是一部分,完整的配置可以在我的github中找到。
数据库脚本:
- springBoot2库的脚本
CREATE TABLE `t_user` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '自增id',
`name` varchar(10) DEFAULT NULL COMMENT '姓名',
`age` int(2) DEFAULT NULL COMMENT '年龄',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=15 DEFAULT CHARSET=utf8注:因为这里我们只是简单的模拟一下业务场景,所以只是建立一张简单的表。
代码编写
说明:这里我只对几个关键的类进行说明,完整的项目工程链接可以在博客底部找到。
在使用SpringBoot整合kafka和storm之前,我们可以先对kfaka和storm的相关代码编写,然后在进行整合。
首先是数据源的获取,也就是使用storm中的spout从kafka中拉取数据。
在之前的storm入门中,讲过storm的运行流程,其中spout是storm获取数据的一个组件,其中我们主要实现nextTuple方法,编写从kafka中获取数据的代码就可以在storm启动后进行数据的获取。
spout类的主要代码如下:
[@Override](https://my.oschina.net/u/1162528)
public void nextTuple() {
for (;;) {
try {
msgList = consumer.poll(100);
if (null != msgList && !msgList.isEmpty()) {
String msg = "";
List<User> list=new ArrayList<User>();
for (ConsumerRecord<String, String> record : msgList) {
// 原始数据
msg = record.value();
if (null == msg || "".equals(msg.trim())) {
continue;
}
try{
list.add(JSON.parseObject(msg, User.class));
}catch(Exception e){
logger.error("数据格式不符!数据:{}",msg);
continue;
}
}
logger.info("Spout发射的数据:"+list);
//发送到bolt中
this.collector.emit(new Values(JSON.toJSONString(list)));
consumer.commitAsync();
}else{
TimeUnit.SECONDS.sleep(3);
logger.info("未拉取到数据...");
}
} catch (Exception e) {
logger.error("消息队列处理异常!", e);
try {
TimeUnit.SECONDS.sleep(10);
} catch (InterruptedException e1) {
logger.error("暂停失败!",e1);
}
}
}
}注:如果spout在发送数据的时候发送失败,是会重发的!
上述spout类中主要是将从kafka获取的数据传输传输到bolt中,然后再由bolt类处理该数据,处理成功之后,写入数据库,然后给与sqout响应,避免重发。
bolt类主要处理业务逻辑的方法是execute,我们主要实现的方法也是写在这里。需要注意的是这里只用了一个bolt,因此也不用定义Field进行再次的转发。 代码的实现类如下:
[@Override](https://my.oschina.net/u/1162528)
public void execute(Tuple tuple) {
String msg=tuple.getStringByField(Constants.FIELD);
try{
List<User> listUser =JSON.parseArray(msg,User.class);
//移除age小于10的数据
if(listUser!=null&&listUser.size()>){
Iterator<User> iterator = listUser.iterator();
while (iterator.hasNext()) {
User user = iterator.next();
if (user.getAge()<10) {
logger.warn("Bolt移除的数据:{}",user);
iterator.remove();
}
}
if(listUser!=null&&listUser.size()>){
userService.insertBatch(listUser);
}
}
}catch(Exception e){
logger.error("Bolt的数据处理失败!数据:{}",msg,e);
}
}编写完了spout和bolt之后,我们再来编写storm的主类。
storm的主类主要是对Topology(拓步)进行提交,提交Topology的时候,需要对spout和bolt进行相应的设置。Topology的运行的模式有两种:
一种是本地模式,利用本地storm的jar模拟环境进行运行。
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("TopologyApp", conf,builder.createTopology());另一种是远程模式,也就是在storm集群进行运行。
StormSubmitter.submitTopology(args[0], conf, builder.createTopology());这里为了方便,两种方法都编写了,通过主方法的args参数来进行控制。 Topology相关的配置说明在代码中的注释写的很详细了,这里我就不再多说了。 代码如下:
public void runStorm(String[] args) {
// 定义一个拓扑
TopologyBuilder builder = new TopologyBuilder();
// 设置1个Executeor(线程),默认一个
builder.setSpout(Constants.KAFKA_SPOUT, new KafkaInsertDataSpout(), 1);
// shuffleGrouping:表示是随机分组
// 设置1个Executeor(线程),和两个task
builder.setBolt(Constants.INSERT_BOLT, new InsertBolt(), 1).setNumTasks(1).shuffleGrouping(Constants.KAFKA_SPOUT);
Config conf = new Config();
//设置一个应答者
conf.setNumAckers(1);
//设置一个work
conf.setNumWorkers(1);
try {
// 有参数时,表示向集群提交作业,并把个参数当做topology名称
// 没有参数时,本地提交
if (args != null && args.length > ) {
logger.info("运行远程模式");
StormSubmitter.submitTopology(args[], conf, builder.createTopology());
} else {
// 启动本地模式
logger.info("运行本地模式");
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("TopologyApp", conf, builder.createTopology());
}
} catch (Exception e) {
logger.error("storm启动失败!程序退出!",e);
System.exit(1);
}
logger.info("storm启动成功...");
} 好了,编写完了kafka和storm相关的代码之后,我们再来进行和SpringBoot的整合!
在进行和SpringBoot整合前,我们先要解决下一下几个问题。
1 在SpringBoot程序中如何提交storm的Topolgy?
storm是通过提交Topolgy来确定如何启动的,一般使用过运行main方法来启动,但是SpringBoot启动方式一般也是通过main方法启动的。所以应该怎么样解决呢?解决思路:将storm的Topology写在SpringBoot启动的主类中,随着SpringBoot启动而启动。
实验结果:可以一起启动(按理来说也是可以的)。但是随之而来的是下一个问题,bolt和spout类无法使用spring注解。
2 如何让bolt和spout类使用spring注解?
解决思路:在了解到spout和bolt类是由nimbus端实例化,然后通过序列化传输到supervisor,再反向序列化,因此无法使用注解,所以这里可以换个思路,既然不能使用注解,那么就动态获取Spring的bean就好了。
实验结果:使用动态获取bean的方法之后,可以成功启动storm了。
3.有时启动正常,有时无法启动,动态的bean也无法获取?
解决思路:在解决了1、2的问题之后,有时出现问题3,找了很久才找到,是因为之前加入了SpringBoot的热部署,去掉之后就没出现了…。
上面的三个问题是我在整合的时候遇到的,其中解决办法在目前看来是可行的,或许其中的问题可能是因为其他的原因导致的,不过目前就这样整合之后,就没出现过其他的问题了。若上述问题和解决办法有不妥之后,欢迎批评指正!
解决了上面的问题之后,我们回到代码这块。 其中,程序的入口,也就是主类的代码在进行整合后如下:
@SpringBootApplication
public class Application{
public static void main(String[] args) {
// 启动嵌入式的 Tomcat 并初始化 Spring 环境及其各 Spring 组件
ConfigurableApplicationContext context = SpringApplication.run(Application.class, args);
GetSpringBean springBean=new GetSpringBean();
springBean.setApplicationContext(context);
TopologyApp app = context.getBean(TopologyApp.class);
app.runStorm(args);
}
}动态获取bean的代码如下:
public class GetSpringBean implements ApplicationContextAware{
private static ApplicationContext context;
public static Object getBean(String name) {
return context.getBean(name);
}
public static <T> T getBean(Class<T> c) {
return context.getBean(c);
}
[@Override](https://my.oschina.net/u/1162528)
public void setApplicationContext(ApplicationContext applicationContext)
throws BeansException {
if(applicationContext!=null){
context = applicationContext;
}
}
} 主要的代码的介绍就到这里了,至于其它的,基本就和以前的一样了。
测试结果
成功启动程序之后,我们先调用接口新增几条数据到kafka
新增请求:
POST http://localhost:8087/api/user
{"name":"张三","age":20}
{"name":"李四","age":10}
{"name":"王五","age":5}新增成功之后,我们可以使用xshell工具在kafka集群中查看数据。 输入:`kafka-console-consumer.sh --zookeeper master:2181 --topic USER_TOPIC --from-beginning
然后可以看到以下输出结果。
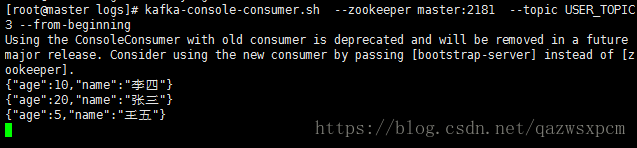
上述也表示了数据成功的写入了kafka。 因为是实时的从kafka那数据,我们也可以从控制台查看打印的语句。
控制台输出:
INFO com.pancm.storm.spout.KafkaInsertDataSpout - Spout发射的数据:[{"age":5,"name":"王五"}, {"age":10,"name":"李四"}, {"age":20,"name":"张三"}]
WARN com.pancm.storm.bolt.InsertBolt - Bolt移除的数据:{"age":5,"name":"王五"}
INFO com.alibaba.druid.pool.DruidDataSource - {dataSource-1} inited
DEBUG com.pancm.dao.UserDao.insertBatch - ==> Preparing: insert into t_user (name,age) values (?,?) , (?,?)
DEBUG com.pancm.dao.UserDao.insertBatch - ==> Parameters: 李四(String), 10(Integer), 张三(String), 20(Integer)
DEBUG com.pancm.dao.UserDao.insertBatch - <== Updates: 2
INFO com.pancm.service.impl.UserServiceImpl - 批量新增2条数据成功!可以在控制台成功的看到处理的过程和结果。 然后我们也可以通过接口进行数据库所有的数据查询。
查询请求:
GET http://localhost:8087/api/user返回结果:
[{"id":1,"name":"李四","age":10},{"id":2,"name":"张三","age":20}] 上述代码中测试返回的结果显然是符合我们预期的。
