在Yellowbrick数据仓库中,丰富的工作负载管理(WLM)功能对于实现可靠的、接近实时的规模性能至关重要。无论您的公司是拥有关键业务数据仓库的企业,还是拥有依赖可靠的大规模数据处理的产品的SaaS供应商,为了获得良好的用户体验,确保数百甚至数千次并发查询的近实时响应是不容商量的。
在这篇文章中,我们将概述什么是Yellowbrick WLM,它的用途是什么,它是如何工作的,以及了解查询执行如何有助于告知一个好的WLM策略。
什么是工作负载管理?
在Yellowbrick数据仓库,资源可以通过各种方式共享,以优化WLM。可以分配给数据库查询和其他操作的主要资源是CPU、内存和临时溢出空间。例如,在一个具有高度并发性的系统中,你可以通过提高查询的优先级来为特定的查询分配更多的CPU。对于需要更多内存或溢出空间的复杂查询,你可以在执行过程中的不同点请求更多的这些资源。长时间运行的查询可以排在非常快的查询后面,以避免使短时间运行的查询得不到足够的资源。
工作量是一组查询或其他数据库请求,在某种程度上是一个已知数量。例如,如果一组用户每天针对同一组表运行特别的查询,那么这组查询虽然有些随意,但可以被认为是一个已知的和预期的工作量。一个用户每天早上在同一时间运行的资源密集型报告也可以被看作是一个单独的(而且可能是高优先级的)工作量。第三个例子是数据库管理工作,如批量加载和备份,这可能发生在终端用户对系统访问少的维护窗口。
工作负载可以在许多不同的维度上进行定义:在运行时间、运行的应用程序或用户、工作类型、预期持续时间、是否为资源密集型等方面。这些变量是MPP数据库系统的典型特征,这些系统很少用于一种类型的查询或由一种类型的用户使用。
来源 https://zhuanlan.zhihu.com/p/409961402
工作负载管理可以解决的一些熟悉的用例包括。
失控查询:识别并停止长期运行的查询,例如,从一个非常大的表中选择所有的行(不管是天真地发出,还是错误地发出,或者是在一个 "错误时间 "发出)。
短期查询的偏见:优先考虑运行速度非常快的查询(亚秒级的速度),防止它们被排在既不期望也不需要即时响应的长期运行的查询后面。
临时查询:将 "浏览 "或 "发现 "查询放在队列中的较低优先级,而不是运行业务所需的更关键的查询。
时间敏感的查询:在一天或一周的不同时间应用不同的规则。例如,每周的业务滚动有高的优先级,直到它们完成。所有其他的查询有较低的优先级。
管理员查询:分配资源,立即运行超级用户查询,特别是内部生成的维护数据库的查询(例如,冲洗和分析新表行的操作)。
加载和更新:进行批量加载、删除和更新的写入查询,不能使读取查询处于饥饿状态。
记录、审计和报告:记录用户定义的信息,并在执行时对查询进行标记;了解系统使用情况,以便调整未来的工作量管理行为;为单独的应用程序和用户组创建审计跟踪。
为了根据工作负载优化资源分配,运营商创建了称为规则、资源池和配置文件的WLM对象。这些对象定义了一套灵活的启发式方法,将典型的WLM用例转化为资源分配和调度的佳策略。你可以在Yellowbrick控制台或使用SQL命令来设置WLM对象
查询的执行
对系统资源分配进行决策的一个重要方面是了解查询的执行情况。Yellowbrick查询从提交到完成会经历几个有限的状态。对这个过程的基本了解将帮助你制定有效的WLM策略,特别是在创建WLM规则方面。
当查询通过其生命周期中的每个状态时,运行时的统计数据会被捕获并记录下来。这些统计数据提供了一个衡量查询执行的每个阶段所花费的时间,为管理员提供了一个监控和分析查询性能的手段。每个阶段的等待时间和实际处理时间都被测量。
下图显示了一个查询的生命周期。每个查询在管理器节点上经过几个状态,同时它正在准备执行,然后它开始在工作节点上运行(执行)。
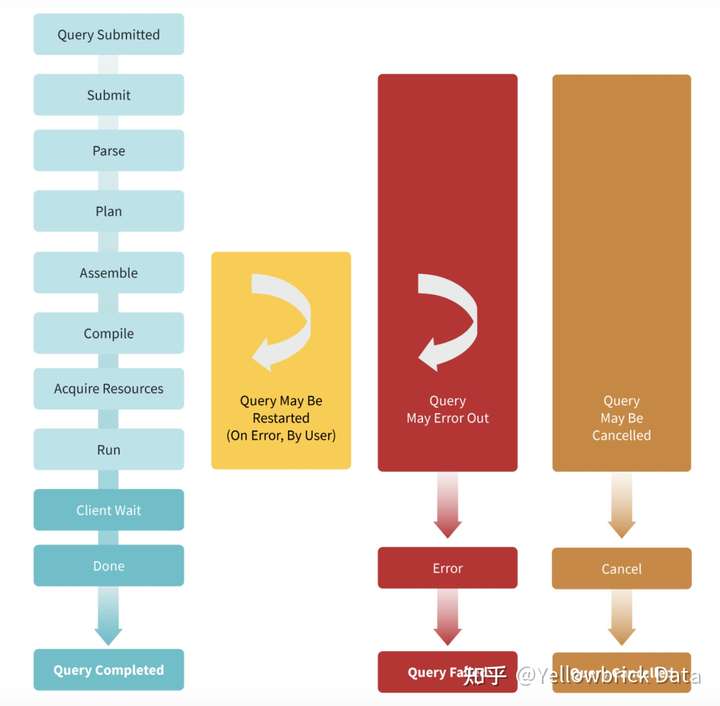
该图还确定了何时可以取消或重新启动查询。一旦提交,查询就会运行到完成,或被取消,或出错失败(DONE、CANCEL和ERROR状态)。如果一个查询被重新启动或返回一个错误,它可以在ASSEMBLE状态下重新进入循环,但终,所有的查询都在三个完成状态中的一个结束。(如果一个查询被取消了,它就不能被重新启动)。
