选自GitHub,机器之心编译。
Yellowbrick 是一套名为「Visualizers」的视觉诊断工具,它扩展了 Scikit-Learn API 以允许我们监督模型的选择过程。简而言之,Yellowbrick 将 Scikit-Learn 与 Matplotlib 结合在一起,并以传统 Scikit-Learn 的方式对模型进行可视化。
项目地址:https://github.com/DistrictDataLabs/yellowbrick
可视化器
可视化器(Visualizers)是一种从数据中学习的估计器,其主要目标是创建可理解模型选择过程的可视化。在 Scikit-Learn 的术语中,它们类似于转换器(transformer),其在可视化数据空间或包装模型估计器上类似「ModelCV」(例如 RidgeCV 和 LassoCV)方法的过程。Yellowbrick 的主要目标是创建一个类似于 Scikit-Learn 的 API,其中一些流行的可视化器包括:
特征可视化
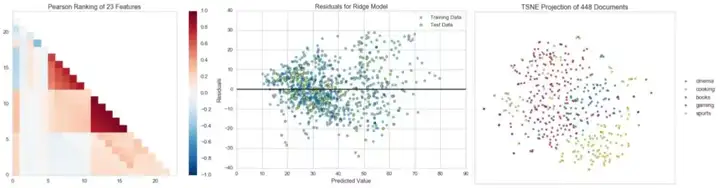
- Rank Features:单个或成对特征排序以检测关系
- Parallel Coordinates:实例的水平可视化
- Radial Visualization:围绕圆形图分离实例
- PCA Projection:基于主成分分析映射实例
- Manifold Visualization:通过流形学习实现高维可视化
- Feature Importances:基于模型性能对特征进行排序
- Recursive Feature Elimination:按重要性搜索佳特征子集
- Scatter and Joint Plots:通过特征选择直接进行数据可视化
分类可视化
- Class Balance:了解类别分布如何影响模型
- Class Prediction Error:展示分类的误差与主要来源
- Classification Report:可视化精度、召回率和 F1 分数的表征
- ROC/AUC Curves:受试者工作曲线和曲线下面积
- Confusion Matrices:类别决策制定的视觉描述
- Discrimination Threshold:搜索佳分离二元类别的阈值
回归可视化
- Prediction Error Plots:沿着目标域寻找模型崩溃的原因
- Residuals Plot:以残差的方式展示训练和测试数据中的差异
- Alpha Selection:展示 alpha 的选择如何影响正则化
聚类可视化
- K-Elbow Plot:使用肘法(elbow method)和多个指标来选择 k
- Silhouette Plot:通过可视化轮廓系数值来选择 k
模型选择可视化
- Validation Curve:对模型的单个超参数进行调整
- Learning Curve:展示模型是否能从更多的数据或更低的复杂性中受益
文本可视化
- Term Frequency:可视化语料库中词项的频率分布
- t-SNE Corpus Visualization:使用随机近邻嵌入来投影文档
还有更多的可视化器!我们随时会添加更多的可视化器,因此请确保查看示例(或甚至开发分支),并欢迎随时为我们提供建议!
安装 Yellowbrick
Yellowbrick 与 Python2.7 以及之后的版本兼容,但使用 Python3.5 或之后的版本会更合适并能利用其所有功能优势。Yellowbrick 还依赖于 Scikit-Learn 0.18 或之后的版本,以及 Matplotlib1.5 或之后的版本。简单的安装 Yellowbrick 的方法是从 PyPI 使用 pip 安装。
$ pip install yellowbrick注意 Yellowbrick 是一个活跃项目,将定期发布更多新的可视化器和更新。为了将 Yellowbrick 升级到新的版本,按以下方式使用 pip 命令:
$ pip install -U yellowbrick你也可以使用-U flag 来更新 Scikit-Learn、Matplotlib 或任何其它和 Yellowbrick 兼容的第三方新版本应用。
如果你使用 Anaconda(推荐 Windows 用户使用),你可以使用 conda 命令来安装 Yellowbrick:
conda install -c districtdatalabs yellowbrick然而请注意,在 Linux 上用 Anaconda 安装 Yellowbrick 有一个已知的 bug:https://github.com/DistrictDataLabs/yellowbrick/issues/205
使用 Yellowbrick
Yellowbrick API 是特别为更好地使用 Scikit-Learn 而设计的。这里有一个使用 Scikit-Learn 和 Yellowbrick 的典型工作流序列的例子:
特征可视化
在这个例子中,我们将看到 Rank2D 如何使用特定指标对数据集中的每个特征进行两两对比,然后返回展示排序的左下三角图。
from yellowbrick.features import Rank2D
visualizer = Rank2D(features=features, algorithm='covariance')
visualizer.fit(X, y) # Fit the data to the visualizer
visualizer.transform(X) # Transform the data
visualizer.poof() # Draw/show/poof the data模型可视化
在这个例子中,我们用具体例子来说明一个 Scikit-Learn 分类器,然后使用 Yellowbrick 的 ROCAUC 类来可视化分类器的敏感性和特异性的权衡过程。
from sklearn.svm import LinearSVCfrom yellowbrick.classifier import ROCAUC
model = LinearSVC()
model.fit(X,y)
visualizer = ROCAUC(model)
visualizer.score(X,y)
visualizer.poof()