环保减排应该是今年热话题之一,江苏、湖南、浙江、广东、云南、山东等10余省份的“停电限产”到全民关注碳中保卫我们的地球。
互联网行业,服务器就是生产力。今天看到汽车之家的案例, 2013年他们的广告离线数据分析已经用到50台服务器,到2021年集群3050台,日均作业35万,处理数据7PB. 现在数据分析集群标配2路服务器,每台功耗750瓦/小时,那么3050台机器每小时2287.5千瓦就是2287.5度电/小时,算他们一天运行8小时,那就是18300度电/天,而他们会占用305个标准机柜。
Yellowbrick Data的技术创新和进步是跨时代的
Yellowbrick Data数据仓库是一个先进的、大规模并行处理(MPP)的SQL数据库,为苛刻的批处理、实时、临时和混合工作负载而设计。它可以在众多节点上以高达PB级的规模运行复杂的查询,并保证亚秒级的响应时间。
今天的大数据分析硬件通常都有几十G到几百G的内存和几十个CPU核心。随着intel的产品更替,市面主流的AMD服务器节点可以支持2TB的内存和128个CPU核心(256个vCPU),我们设想到2023年,192个核心(384个vCPU)将普遍可用。在这些服务器节点上运行通用软件的效果并不理想。操作系统调度器是为等待事件和 "连接交换 "而建立的:" 线程等待事件,如按键、网络数据包到达、存储I/O完成或同步基元可用--并在竞争的线程和进程之间进行切换,以尽量做到公平并有效地使用缓冲区。因此,现代数据库每秒钟在每个CPU核上进行数以万计的上下文切换并不罕见,总的来说,每秒钟有数百万次。
传统观点认为,如果你花在上下文切换上的CPU时间不多--低于10%--你的情况就很好;上下文切换在一个好的操作系统中是很便宜的。然而,这个假设已经过时了。现代CPU的性能来自于对其缓存数据的处理,通常称为L1、L2和L3。L1包含与近的处理有关的数据,L2缓存较大,但访问速度较慢,同样,L3缓存也是如此。每个CPU核心的L1缓存以几十KB为单位,L2缓存以几百KB为单位,而L3缓存则为个位数兆字节。
当这种上下文切换和进出复杂的Linux内核子系统的情况在几十个内核之间不断发生时,任何现代的CPU都将难以高效工作。DBA们不会知道,认为CPU的利用率是,但是,数据库只达到了理论上的大效率的一小部分。
介绍一下Yellowbrick Data内核
为了避免这些Linux固有的问题,我们从头开始建立了一个新的操作系统内核。它实现了一个新的执行模型,以消除可衡量的连接交互开销,并消除了与访问存储、网络和其他硬件设备有关的多余开销。我们通过为整个数据路径建立一个新的、反应式的编程模型来做到这一点。
Yellowbrick Data内核被实现为一个 "用户空间旁路内核"--一个控制大部分机器和附加I/O设备的Linux进程。作为一个Linux进程,它可以在容器环境(如Kubernetes)、虚拟机或裸机上舒适地运行。它评估每个环境中可能有多少 "旁路 "能力,然后适应使用尽可能多的能力,因此它在十年前的笔记本电脑上的虚拟机、亚马逊EKS中的容器、私有云中的OpenShift或定制设计的刀片服务器中的裸机上表现佳。当Yellowbrick Data启动时,Linux被降格为收集日志和统计数据的监督员代理,所有的核心数据路径功能完全绕过它。
这种新的编程模型的一些原则包括。
内存管理。Yellowbrick Data本质上理解NUMA(非统一内存架构)机器。在数据库启动时,系统中几乎所有的内存都被移交给Yellowbrick并被锁住(以确保Linux永远不会换入/换出我们的进程)。物理到虚拟的映射被注意到,所以硬件设备可以绕过内核直接安全地访问数据库内存。
线程和进程。Yellowbrick Data有一个基于反应式概念的现代线程模型,如期货和联合程序。被称为任务的小型独立工作单元被安排并运行到完成,没有抢占式的交换开销。
设备驱动程序。传统的设备驱动程序在Linux内核中运行,每当有事情发生时就中断执行。相比之下,Yellowbrick Data的设备驱动是异步的和轮询性质的。对驱动程序的访问总是通过具有明确定义的接口的队列。一般的PCIe设备、NVMe SSD、各种网络适配器等都有驱动,所有这些都是在没有Linux参与的情况下工作。在Yellowbrick Data运行而没有旁路的情况下,每一类(网络、存储等)的仿真驱动都是存在的,这些驱动都依赖于Linux内核或软件仿真。
网络。像许多现代的、基于微服务的软件堆栈一样,Yellowbrick Data是用各种不同的语言实现的。我们主要使用C、C++和Java,必要时也会使用Go和Python,而这些服务需要相互交流。使用抽象的、高性能的、带有标准接口的零拷贝网络给Yellowbrick数据库带来了传统数据库无法比拟的好处。我们已经在MPP快速路径中的网络上为单个CPU核心发送和接收16GB/秒的数据计时,而且时间很充裕。当使用Linux内核时,大约1.5GB/秒的速度是极限,CPU核心已经满负荷,没有时间进行数据处理。我们的网络技术允许数据库查询中昂贵的部分--例如为连接、聚合(GROUP BY)和排序重新分配数据--比竞争对手的数据库运行效率高10倍,只需使用一小部分资源。
性能提升后,硬件的资源需求也大幅度降低。
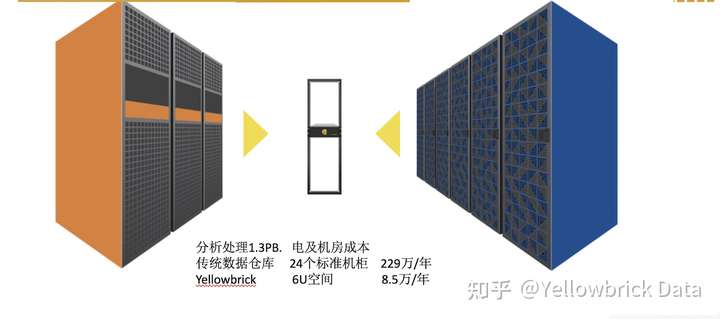
1.3PB的数据仓库 Yellowbrick只需要一个6U的机柜空间 而传统的数据仓库产品需要24个机柜。按日运行8小时计算,传统数据仓库平均年用电56万度电,YBD 年用电1.2万度
来源 https://zhuanlan.zhihu.com/p/415831423
