AnalyticDB 是阿里云自研的 OLAP 数据库,广泛应用于行为分析、数据报表、金融风控等应用场景,可支持 100 trillion 行记录、10PB 量级的数据规模,亚秒级完成交互式分析查询。本文是对 《 AnalyticDB: Real-time OLAP Database System at Alibaba Cloud 》的学习总结。
数据模型
AnalyticDB 采用标准的关系数据模型,支持标准的 SQL 访问(兼容 MySQL 协议)。为了实现系统扩展,AnalyticDB 支持量两级分区能力。如下图所示,数据根据 id 列分到50个 partition,称为 primary partition;在 primary partition 内部可以根据,再根据 dob 列来再进行分区(subpartition),并设置保留12个分区。subpartition 通用采用时间列进行分区,用于高效的支持时间范围查询以及数据生命周期管理(TTL)。


架构总览
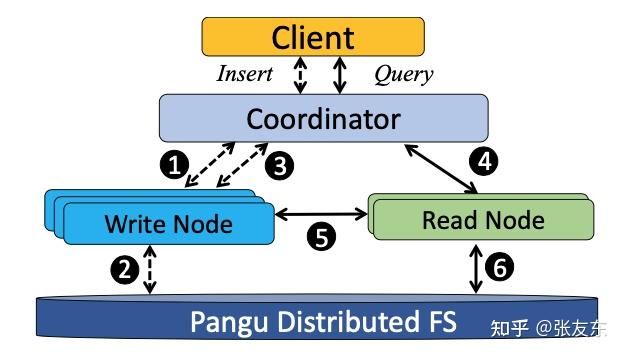
AnalyticDB 主要包含 Coordinator、Write Node、Read Node 三种类型的节点。Coordinator 通过 JDBC/ODBC 连接的方式接受客户端的读写访问请求,根据请求类型分派到 Write Node、Read Node。Write Node 主要负责处理写请求,包括 INSERT、DELETE、UPDATE、FLUSH(强制数据持久化);Read Node 则主要负责 SELECT 查询请求。
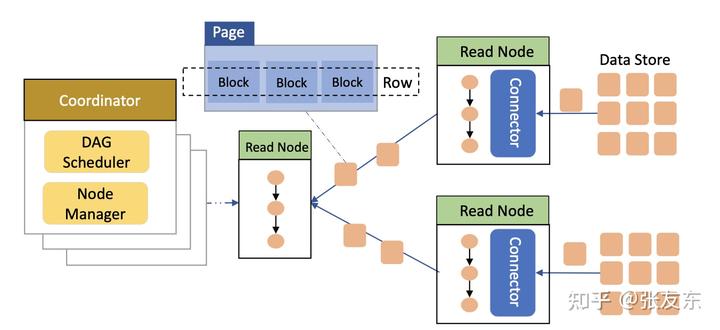
AnalyticDB 内置通用的流式执行引擎,数据以 Column Blocks 的形式在执行引擎中流转,所有的数据处理均在内存中完成,不同的处理阶段管道化执行,保证系统的高吞吐与低延时。
读写分离
AnalyticDB 读写节点物理隔离,大化读写处理能力,且尽量相互不影响。
高写入吞吐
Write Node 中一个主节点会被选为 Master(通过 Zookeeper ),集群的写入协调分配由 Master 负责。Write Node 接受到写入的 SQL 语句后,将其缓存在内存 Buffer,并周期性的以 Log 形式存储到 Pangu 分布式共享存储;当盘古上的 Log 文件达到一定数量时,AnalyticDB 会发起 MapReduce 任务将其转为数据文件,并构建全量索引。
实时读
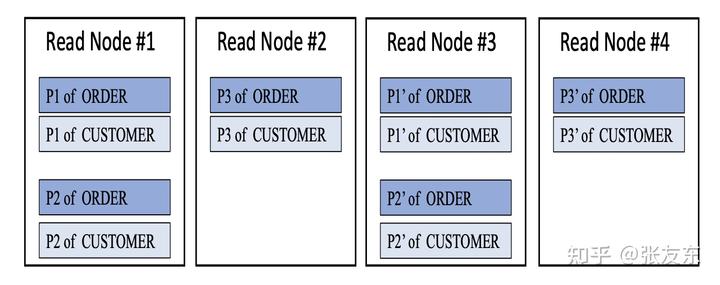
每个 Read Node 负责部分 Partition 的读,由 Coordinator 来协调分配,通过副本机制保证读取的高并发和可靠性。Read Node 根据分配的 Partition 进行初始化,并周期性从 Write Node 拉取新的数据更新,Write Node 相当于同时作为读缓存节点。
由于新的写入需要从 Write Node 远程获取,AnalyticDB 提供 realtime和 staleness两种读模式;前者保证能读到新的写入,而后者则有一定范围的延迟但性能更高,AnalyticDB 默认采用 staleness策略。
可靠性与扩展性
读写节点均具备高可靠机制,Write Node 故障时,Coordinator 会讲其负责的 Partition 分到其他的 Write Node;Read Node 采用副本机制(默认2)来保证可靠性,当 Read Node 节点故障时,可以直接访问其副本来读取数据。
读写节点均可在线扩展,增加 Wrtite Node 时,Master 会重新分配 Partition 到各个 Write Node 均衡负载;增加 Read Node 时,有类似的重分配机制,但整个过程由 Coordinator 负责完成。
存储引擎
OLAP 查询通常访问宽表中的小部分列,按列存储能很好的适应这类查询,但导致 Point Query 的性能很差。AnalyticDB 采用行列混存的方式进行数据存储,同时满足 OLAP 类以及 Point Query 类查询。
行列混存
每个表的数据被分为多个 Partiion 存储,每个 Partition 对应一个数据文件,称为 Detail File,文件内部分成多个 Row Group 进行存储,每个 Row Group 包含多行数据(固定数量);Row Gruop 内数据按列组织连续存储,压缩率高,同时利于大块读写访问。对于 Point Query,快速定位到 Row Group 之后,根据索引在 Row Group 内进行读取即可。AnalyticDB 对每一列都建立索引,用于加速多维分析查询 (参考索引管理章节)。

对于数值、定长短字符串类型,Row Group 通常包含固定数量(如30000)的行,但对于复杂的类型,比如 JSON、Vectors 等,如果按固定数量行数存储,则会导致一个 Block 非常大。
AnalyticDB 通过引入一级 FBlock 来解决复杂类型数据存储,每个 FBlock 固定 32KB,固定行数的 Row Group 数据会被存储到多个 FBlock(独立的文件)。如下图所示,0-99行存储在 FBlock1,99-200行存储在 FBlock2,其中 Row-99 分散存储在两个 Block。

元数据
Detail File 里的每一列都包含元数据,用于加速数据访问,快速过滤不满足条件的数据。 元数据存储在独立的文件,称为 Detail Meta File,通常较小(比如小于1MB),但访问频率高,会缓存在内存里加速访问。
元数据包含四个部分,Header 包含版本号,及文件总大小等信息;Summary 包含优化器需要的重要统计信息,例如行数、NULL 行数、取值分布、sum/min/max 的等;Dictionary 对于 low cardinality 的列自动启用,用于降低存储空间;Block Map 对于每个 Row Group 维护一项,存储其在 Detail File 里的 offset/length。
数据操作
AnalyticDB 存储层采用 Lamda 架构,包含基线数据(Baseline Data) 和 增量数据(Incremental Data)。基线数据包含历史数据及索引,而增量数据包含近写入的数据,并没有建里全字段的索引,只包含简单的 Sorted Index 来加速查询。
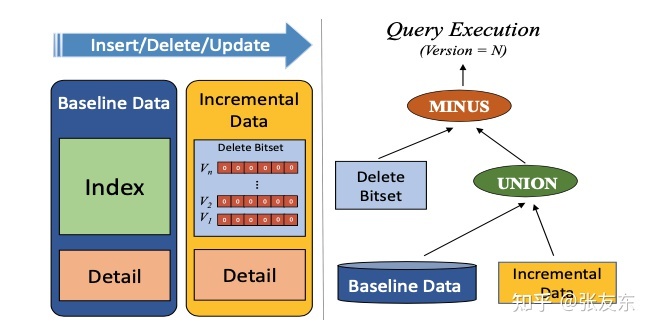
为了支持 UPDATE 操作,AnalyticDB 采用 bit-set 来记录删除的行,借助 Copy-on-Write 技术实现 MVCC,当行被更新或删除时,系统产生新的版本,删除的 bit-set 与该版本关联。当执行查询请求时,会根据指定的版本决定查询哪些数据。

随着增量数据不断增加,查询的性能会逐步下降,后台会不断将基线数据和增量数据进行合并,合并过程中会对 增量数据建立索引,合并为新的基线数据。
索引管理
多维索引
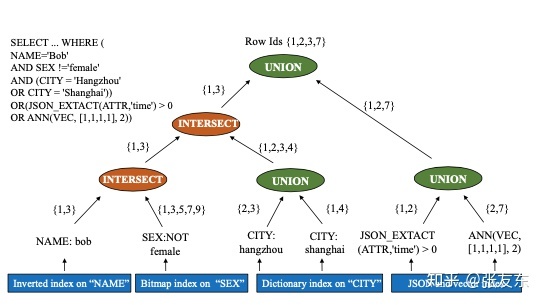
AnalyticDB 针对每一列都建立倒排索引,用于高效的支持多维度 ad-hoc 查询,索引的 Key 是列对应的取值,Value 时匹配该取值的行号列表,由于 AnalyticDB 每个 RowGroup 都包含固定数量的行,可以高效的根据行号定位到对应的数据。如下图所示,SELECT 查询包含6个维度的条件查询,AnalyticDB 会根据每个列的倒排快速找出满足查询条件的行号,然后多个结果之间做合并(Union 或 Intersect)。
索引选择
在索引选择上,AnalyticDB 采用 fiter ratio 来决定是否使用索引;例如 A、B 两个查询条件做交集,如果 A 条件的匹配结果远小于 B 条件的匹配结果,此时基于 A 条件的结果对 B 条件进行过滤会更加高效。
查询条件的 fiter ratio 为匹配该条件的行数(根据倒排索引获取)与总行数(元数据获取)的比例,越低说明条件的过滤性越好,如果高于一定比例,则 AnalyticDB 不会利用该条件的索引,而只将其作为终的过滤条件。
复杂类型索引
对于 JSON 类型数据,AnalyticDB 会将 JSON 结构扁平化,然后针对每个字段建立索引,如下的 JSON 文档,系统则会对 id、product_name、properties.color、properties.size 分别建立倒排索引。
{
id: xxxx
product_name: yyyy
properties:
{
color: zzzz
size: wwww
}
}对于文本数据,AnalyticDB 在倒排索引的基础上进行扩展,会存储 Term Frequency、Inverse Document Frenquency 等信息用于计算文本数据与查询条件的相似度。
对于向量数据,AnalyticDB 支持按照欧式距离或余弦距离来计算向量间的距离,从而找出接近/相似的向量。为了减少扫描,AnalyticDB 实现了 Production Quantization 以及 Proximity Graph,并自适应的选择采用何种策略。
索引空间优化
为了优化倒排索引存储空间,AnalyticDB 自动决定采用 bitmap 还是 integer array。例如行号列表 [1,2,8, 12] 采用 2bytes 的 bitmap 存储更加节省空间。而 [1,12,35,67] 则采用 4bytes 的 integer array 更加节省空间。
异步索引构建
在写入链路上针对所有列构建索引会极大的影响写入性能,AnalyticDB 采用异步构建索引的方式。后台会周期性的针对盘古里的增量数据构建倒排索引,索引构建过程会记住 Map-Reduce 任务高并发的完成。

增量数据索引
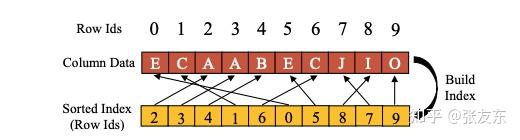
对于增量数据,AnalyticDB 不会立即构建所有列的倒排索引,这对增量数据的查询会有影响;AnalyticDB 针对增量数据建立更低开销的 Sorted Index,可以利用二分查找来加速查询。
索引缓存
AnalyticDB 除了对索引进行缓存,还会对索引查询条件的结果进行缓存,例如 id < 123 作为查询条件,其对应的结果集可以缓存在内存,接下来重复的查询条件可以直接从缓存获取结果。
由于用户的查询条件在持续发生变化,有可能导致频繁的 cache eviciton,但从实际来看,查询结果集较大的查询条件例如(city="beijing") 很少发生变化,缓存通常非常有效;而查询结果集较小的查询例如(user_id=xxx) 会频繁发生变化,缓存作用不打,但这类查询能低成本的重新获取查询结果。
优化器与执行器
AnalyticDB 优化器同时支持 CBO(cost-based optimization) 和 RBO(rule-based optimization)。除了支持 cropping、pushdown、constant folding 等一系列的优化规则支持。AnalyticDB 提供了2个关键的特性,Storage-Aware Optimization 和 Efficient Real-time Sampling。
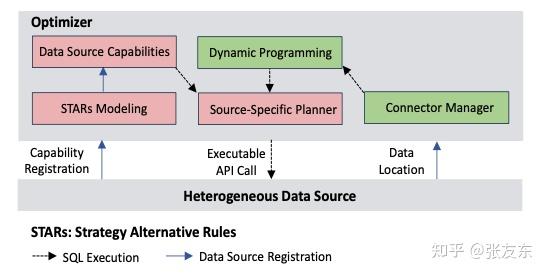
很多分布式数据库也支持将计算 Push down 到存储层,但通常只限于 AND 条件,针对单个列的的匹配条件才能下推。AnalyticDB 定义了一个 STAR(STrategy Alternative Rules) Framework 用于实现复杂查询的 push down。STAR 定义了一系列高层次的接口抽象,存储数据源可以注册接口来实现扩展能力的下推支持。AnalyticDB 存储引擎支持高效的数据访问,优化器在优化时,会向存储引擎请求对数据进行采样预测,从而选择更优的执行计划。
AnalyticDB 提供一个通用的流式执行引擎,以及基于 DAG(Directed Acyclic Graph)的执行框架,能很好的处理好各种查询负载,包括要求低延时的小规模数据查询,以及要求高吞吐的大规模数据查询。AnalyticDB 执行引擎面向列存,能充分利用底层行列混存的存储特性,相比面向行的执行引擎,其对缓存更加有好,并能大程度避免加载不必要的数据到内存。
总结
- AnalyticDB 是阿里自研的 OLAP 数据库,在内部服务多年,经过很多大规模生产场景的考验。
- AnalyticDB 采用行列混存的机制来同时满足 OLAP 类,以及 Point Query 的查询需求;AnalyticDB 针对所有字段(包括复杂数据类型,如JSON、Text、Vectors)建立索引,来支持高效的多维查询,同时通过异步索引的机制来降低索引对写入的影响;通过增量数据构建轻量的 Sorted Index 提升增量数据的查询效率;AnalyticDB 优化器充分利用存储层的能力来加速查询,尽可能将查询下推到存储层。
- AnalyticDB 的架构(论文发表于 VLDB 2019)涉及对盘古、伏羲等云基础组件的依赖,同时支持读写分离、异步构建索引等,整体架构有一定的复杂度,新版本(公共云上的AnalyticDB for MySQL 3.0) 已经做了很多改进,架构更加简洁清晰,充分利用云原生的能力,也能很好的适应不同规模场景的弹性需求。
