ClickHouse 是一款非常的 OLAP 数据库,而 MergeTree 则是 ClickHouse 里核心、常用的存储引擎,本文主要解析 MergeTree 的数据存储逻辑,OLAP 数据库的数据通常是批量写入,MergeTree 引擎将每个批量写入存储成不同的文件,然后后台根据一定策略对文件进行合并,跟 LSM Tree 引擎的 Compaciton 逻辑比较类似。
创建 MergeTree 引擎表
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],
...
INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1,
INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2,
) ENGINE = MergeTree()
ORDER BY expr
[PARTITION BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[TTL expr
[DELETE|TO DISK 'xxx'|TO VOLUME 'xxx' [, ...] ]
[WHERE conditions]
[GROUP BY key_expr [SET v1 = aggr_func(v1) [, v2 = aggr_func(v2) ...]] ] ]
[SETTINGS name=value, ...]本文主要讨论存储相关的部分,核心包括
- ORDER BY
- PRIMARY KEY
- Skip INDEX
- PARTITION KEY
- TTL
CREATE TABLE stuedents (
id INT,
name VARCHAR(64),
score INT,
INDEX idx_score score TYPE minmax GRANULARITY 2
) Engine = MergeTree()
ODDER BY id,
SETTINGS index_granularity=3;例如:一次 BATCH INSERT 插入的示例数据如下
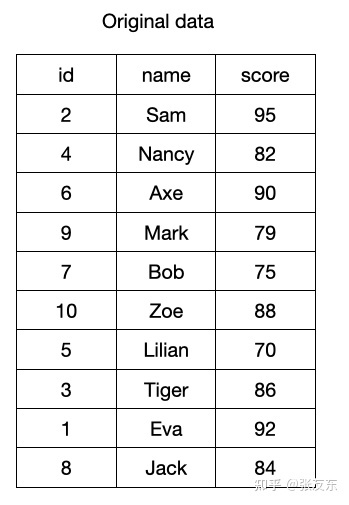
Sorting Key (ORDER BY)
数据在批量插入时,通常是按原始产生的顺序组织,对于每个列的维度,都无法保证记录确定的存储顺序;而实际的场景中,比如上述的 students 表,数据经常需要按 id 顺序进行组织或分析,ClickHouse 支持数据在存储时,指定按某个/些列排序存储,在数据写入到文件之前,ClickHouse 会对数据先进行排序,然后按列进行存储。 stduents 表 ORDER BY id 之后,实际存储顺序如下。
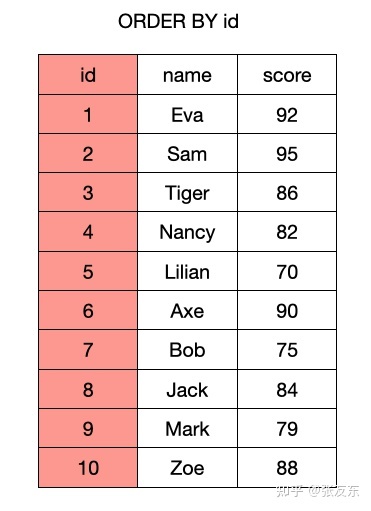
列式存储与mrk文件
数据按 ORDER BY 指定的顺序排序后,ClickHouse 采用列式存储来加速分析型查询,主要优势包括
- 分析场景通常涉及大量数据扫描,但可能只访问部分列,采用列存可以极大的降低扫描数据量,提升扫描效率。
- 数据列式存储时,可以根据不同的数据类型定制压缩算法,且通常压缩率会非常高,进一步减少扫描数据量
ClickHouse 针对每个列,会单独存储一份列存数据,同时为了根据列存快速定位数据,针对每个列都存储了一个 mrk 索引文件,可以简单理解为一个行号索引,可以根据行号快速定位到对应列的数据。
mrk 索引与传统关系型数据库二级索引不同,并不是针对每一行都建立一个索引条目,这样开销太大,而且点查效率并不是 OLAP 的优化的目标。ClickHouse 通过 index_granularity参数来控制多少行作为一个索引单元(也可以通过字节数来控制,建表时在 setting 里指定)。
上述表格里,指定了 index_granularity=3,即代表3行作为小的索引单元 granule(默认为8192,本文选取较小的值方便说明问题,真实场景不建议设置太小)。score 列的存储结构如下,其他列的存储类似(实际存储时,列存数据会进行压缩编码)。
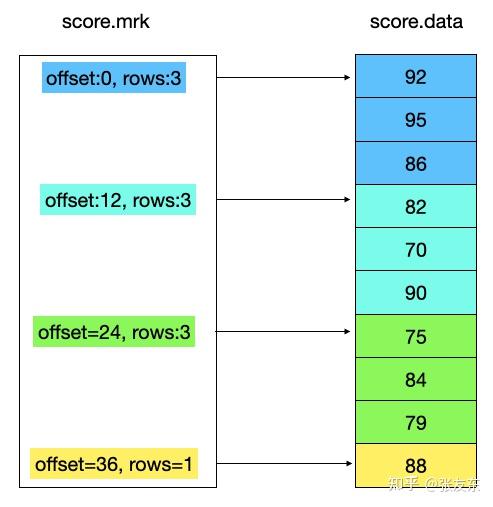
mrk 里对应的 offset 为列存数据对应的物理文件 offset ,rows 即为一个 index_granularity 对应的一个索引单元。 有了 mrk 索引信息,就可以快速的根据索引信息,根据行号定位到列对应的行数据。
Primary Key
ClickHouse 里的 Primary Key 没有性约束,通常情况下,用户无需显式指定 Primary Key;Sorting Key 即为 Primary Key。两者也可以不同,但 Primary Key 必须为 Sorting Key 的前缀。
ClickHouse 针对 Primary 建立了单独索引,同样是以 index_granularity行为一个索引单元 ,因为数据是按 Primary Key 顺序组织的,这个索引能快速的根据 Primary Key 的值来定位对应的数据。students表中 Primary Key 没有指定,则 id 列即为 Primary Key,其索引如下所示。

当查询指定 Primary 的范围时,就可以快速根据 primary.idx 索引信息定位到对应的 granule,从而确定 data 文件的扫描范围。
Skip index
对于 Primary Key,ClickHouse 可以通过索引加速查询,如果查询条件是非 Primary Key,则默认需要扫描数据列的所有数据进行条件过滤;为了加速其他列的查询,ClickHouse 支持 Skip Index ,用于快速过滤数据块里是否包含满足条件的数据,Skip Index 主要包括。
-
minmax,针对列存数据块,记录块内大,小值用于过滤。 -
set(max_rows),为该列的数据存储不重复的取值集合,用于过滤,适用于列数据有取值较少,但每个取值数量较多的场景(即 cardinality 比较低的列) -
bloomfilter,对数据列的取值建立 bloomfilter 索引数据用于快速过滤。 -
ngram、token,为列数据的分词建立 bloomfilter 索引用于快速过滤。
以 minmax 为例,针对 score 列建立 minmax index, GRANULARITY 为2,也就是针对每2个索引单元(index_granularity行)对应一个索引信息。比如要查询分数小于 80 的所有学生的信息,则可以快速过滤掉前面两个索引单元。

Partition Key
ClickHouse 支持对数据分 Partition 存储,不同 Partition 之间的数据物理隔离,用户可以根据 Partition Key 快速过滤 Parition 是否有满足条件的数据,比如将数据按时间进行分区,不同月份的数据存储到不同的 Partition,与传统关系型数据库的分区类似。
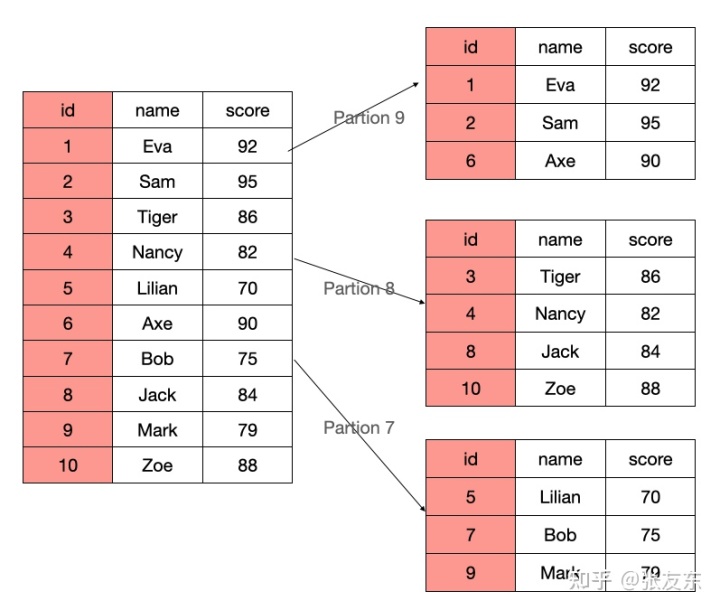
例如 PARTIION BY score/10 相当于按 score 进行分区,每10分一档为一个 Partion,当查询一档内的分数区间时,就可以快速过滤掉不相关的 Partition。
TTL
ClickHouse 支持对对整个表或者指定的列定义 TTL 规则,数据过期时,可以指定不同的处理规则,比如删除数据或者归档到其他存储实现冷热分层存储的能力,数据 TTL 到达时支持的处理规则包括
-
DELETE: 删除过期的行(默认行为) -
RECOMPRESS codec_name:对过期的的数据采用新的压缩编码存储(比如压缩率更高的压缩算法以节省成本) -
TO DISK 'xxx':过期的数据移动到对应的 DISK,用户可以配置不同的 DISK 名字对应到不同的数据目录或存储介质,实现冷热分离。 -
TO VOLUME 'yyy': VOLUME 可以理解为多个逻辑的 DISK,ClickHouse 支持按一定的规则在将数据在 DISK 间进行移动。 -
GROUP BY: 对过期的数据进行聚合计算。
查询加速
- 如果表指定了 Partition Key,并且查询条件包含 Partition Key,则根据查询条件快速过滤满足条件的 Partition。
- 在 Partition 内部,如果查询条件指定了 Primary Key 或 Sort Key,则根据 Primary Index 来过滤满足条件的索引单元。
- 如果查询条件的列有 Skip Index,则根据对应 Index 过滤满足条件的索引单元。
总结
ClickHouse 支持在建表时指定存储引擎,以支持不同场景的分析需求,其中 MergeTree 系列的引擎为常用。MergeTree 通过列式数据存储、Primary Index、Skip Index 能很好的支持分析型的查询场景。
除了支持标准的 MergeTree,Clickhouse 还支持各种 MergeTree 的变种,但核心存储逻辑类似;包括 ReplacingMergeTree 支持数据更新去重、CollapsingMergeTree 支持数据删除、Aggregating MergeTree 支持数据预聚合、ReplicatedMergeTree 支持数据复制等,以满足不同场景的分析需求。
ClickHouse 通过插件式引擎的方式做到 One Engine for Most ,通过一套数据库,尽可能满足更多的分析型场景。
