Amazon Redshift 是一款高性能、全托管的PB级云数仓,2013 年上线后,曾是AWS 增长快的云服务:Redishift 与主流的数仓类似,基于 MPP、columnar、scale-out 的架构,但其目标不是跟市场上现有数仓竞争,而是充分简化数仓的使用(easy to buy、easy to tune、easy to manage),开拓零消费市场。
背景介绍
数据仓库的市场规模约为关系型数据库的1/3($14B vs $45B,2015年数据),年复合增长 8-11%,而过去10年,数据量则每年有 30-40% 的增长,说明有很大一部分数据是 Dark Data,即数据被收集了但并没有被分析处理,如果用户不能发现数据的价值,也将不会保留这些数据。
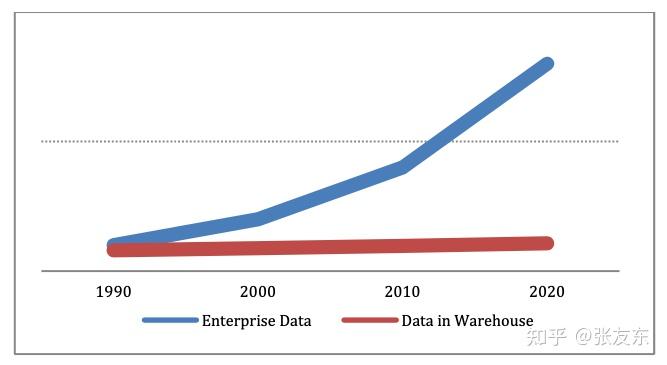
数据产生,但没有被分析处理(analysis gap),主要的原因包括
- 成本(Cost):商业的数仓解决方案非常昂贵,对于价值不确定的数据,用户尝试的成本很高。
- 复杂度(Complexity):数据库实例的生产、维护、备份、调优等对领域技能要求交够,需要很大的 IT运维 投入,数据库分析师/科学家无法独立完成。
- 性能(Performance):要做到扩容不影响数仓现有查询难度很高,而为了保证稳定性 SLA,IT 团队扩容的积极性并不高。
- 模式僵硬(Rigidity):数据库对于结构化数据处理很高效,但对非结构化数据,类似运行日志、音视频的处理能力较差,而这部分数据增长量快。
业界的数据仓库普遍采取列存数据布局、列式数据压缩、近数据计算/Join、代码生成、MPP 等技术来提升性能,但这些技术并没有突破上述的 analysis gap,让尽可能多的数据都能分析并产生价值。除了应用这些普适技术,Redshift 重点在易用性上进行提升,让数据分析唾手可得。易用性方面的核心设计目标包括
- Minimize cost of experimentation:数据的价值在被分析之前很难评估,Redshift 提供 free trial 的版本,用户可以0成本试用60天(160GB 存储),试用之后可以转成按量付费的实例。
- Minimize time to first report:优化用户从创建集群到得到条分析查询结果的时间,PB 级的数据仓库也能在15分钟完成生产及初次使用。
- Minimize adminstration:Redshift 将备份恢复、实例升级、故障修复等动作都自动化,简化用户的集群管理。
- Minimize scaling concerns:数据仓库通常会提供并行加载数据、并行查询的能力,而 Redshift 将集群管理动作也进行并行化,做到更高效的扩展,包括集群创建、备份回复、扩缩容等,用户所付出的成本与数据规模基本是线性关系。
- Minimize tuning:Redshift 的默认配置及自动调优策略能满足绝大部分用户的需求,深度用户也可以自行定制部分参数;比如 Redshift 会自动对数据进行采样选择优的压缩算法,通过 z-curve 数据组织来自动优化查询。
系统架构
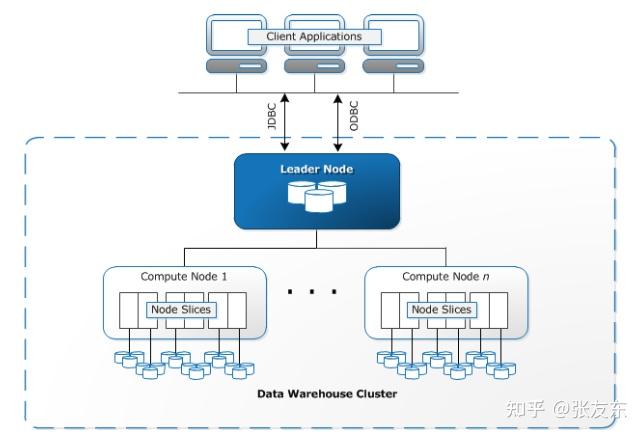
数据面(Data Plane)
Amazon Redshift 集群由一个 Leader Node 和 多个 Compute Node 组成,主要服务分析性的负载,包括大量数据的全量、增量导入,以及对数据的扫描、连接、过滤、聚合等操作。
Leader Node 接受客户端的连接,解析请求并生成查询计划分到多个 Compute Node 上并行执行,并按需对 Compute Node 返回的结果进行聚合。
表的数据在 Compute Node 之间以及内部都会进行分散存储,以充分利用多节点并行的能力,同时发挥多核处理的能力,降低多线程之间的访问竞争。
Compute Node 资源会被切分为 Slice,每个 Slice 管理部分的内存和磁盘空间,并负责响应的数据存储与查询。用户可以指定表的分片策略,包括 Round Robin、指定 Key Hash 等,多表针对相同的 Key 进行 Hash,可以将 Join 操作尽量本地化提高效率。每个 Slice 存储的数据采用列存方式以 Data Block 为单位进行压缩编码存储,不同列之间通过行号来形成逻辑的关系数据视图。
Data Block 会在数据库实例内复制多副本进行存储,减小节点故障对查询的影响,同时 Block 会异步方式将数据存储到 Amazon S3 保证数据的高可靠。
Redshift 通过类似 PostgreSQL 里的 COPY 命令来支持数据的便捷加载,可以方便的从 Amazon S3、Amazon DynamoDB、Amzone EMR 等数据源加载数据,COPY 命令实现 Slice 级别的并行,每个 Slice 并行的从源端读取数据并重新分布排序。
管控面(Control Plane)
Amazon Redshift 的管控由单独的集群来负责,支持包括集群的监控告警、扩容/缩容、备份恢复、版本升级等一系列能力。
核心理念:简化数仓使用
简化购买决策
Amazon Redshift 将用户开始关注产品主页到开通数据库实例发出个请求并获得结果的时间作为用户决策的衡量指标,通过多种手段来缩短这个路径时间。
- 【愿意尝试】Redshift 支持免费试用版,提供 160GB 数据存储免费使用60天,让用户开通试用没有障碍。
- 【开通服务】Redshift 将实例的创建并行化,并通过预创建等手段,将实例创建的时间优化到3分钟以内。
- 【连接系统】Redshift 兼容 PostgreSQL 的协议,实例开通后,用户可直接使用 PostgreSQL 客户端工具来访问,降低用户连接数据库并使用数据库的时间。
- 【读写数据】Redshift 支持从一系列的数据源自动导入数据,降低用户使用现有数据验证查询效果的时间。
简化数据库管理
Amazon Redshift 利用一系列其他云产品来完善自身的产品能力,以降低 Redshift 的管理成本,包括
- Compute Node 依赖 EC2 弹性计算服务,实现计算节点的快速弹性
- 使用 Amazon S3 来进行存储数据备份
- 使用 Amazon Simple Workflow 来支持控制面的任务流实现
- 使用 Amazon CloudWatch、Siimple Notification Services 做监控告警
- 采用 Amazon VPC 做网络隔离、Amazon Route53 做 DNS 查找
- 采用 AWS CloudTrail 支持审计日志的存储与检索
- 采用 AWS Key Management Service 和 AWS CloudHSM 做密钥管理
简化数据库调优
- Amazon Redshit 调优参数相比其他数据库少很多,尽量将用户从性能调优解放出来。
- 系统自动优化产生比较优的解法,比如采用 z-curve index ,即使索引列没有指定也能获得比较好的查询性能。
用户案例
企业级数仓
部分用户将 Amazon Redshift 作为传统企业级数仓来使用,从其他数据源周期性(如小时级、天级别)导入数据,并通过 BI 工具来访问数据,这部分用户主要看重系统使用简单、透明,并能使用现有的 BI、ETL 工具。
大数据分析
部分用户使用 Amazon Redishift 分析日志、交易数据,这些用户原来可能采用 HIVE on Hadoop 来进行数据分析,迁移到 Redshift 能以更低的成本获得更好的性能表现。通过 SQL 用户就能将现有的系统与 Redshift 连接起来,并通过 SQL 或 BI 工具进行分析。
数据转换
越来越多的用户将 Redshift 当成数据处理 Pipeline 的一部分,将原始数据 LOAD 到 Redshift,通过 SQL 进行分析处理,将结果输出到结果表提供在线服务。
小数据(在离线配合)
大量 Redshift 的客户之前并没有使用数据仓库,而是直接基于 OLTP 系统做提供分析,通过将分析负载从 OLTP 系统移除,能获得更稳定的在线服务和更高的分析性能,数据从 OLTP 系统自动实时的写到 Redshift 的能力对用户应用该场景非常关键。
经验教训
- 设计扶梯而非电梯,当系统故障时能提供降级服务而不是彻底不能服务。
- 持续交付新特性,系统自动对系统进行版本升级,对用户透明,用户能持续获取到系统的新特性。
- 采用帕累托分析性( Pareto Analysis)法规划工作优先级,持续解决应用用户的 Top 问题。
