
作者介绍:
王坤,2020年加入去哪儿网,系统运维工程师、去哪儿云原生SIG、基础设施SIG成员,目前主要负责Kubernetes、容器指标监控等系统的运维和云原生相关工作。
一、概述
数据采集量大存在瓶颈,目前 Qunar 单集群容器指标量级每分钟将近 1 亿;
不支持水平扩容;
只支持 All in One 单机部署,不支持集群拆分部署;
其本身不适用于作为长期数据存储;
占用资源高;
查询效率低,Prometheus 加载数据是从磁盘到内存的,不合理查询或大范围查询都会加剧内存占用问题,范围较大的数据查询尤其明显,甚至触发 OOM 。

兼容 PromQL 并提供改进增强的 MetricsQL ;
可以直接使用 Grafana 的 Prometheus DataSource 进行配置,因为兼容 Prometheus API ;
高性能 - 查询效率优于 Prometheus ;
低内存 - 相较 Prometheus 低 5 倍,相较 Promscale 低 28 倍;
高压缩 - 磁盘空间相较 Prometheus 低 7 倍,相较 Promscale 低 92 倍,详情可参见 Promscale VS VictoriaMetrics ;
集群版可水平扩展、可数据多副本、支持多租户
VM - Single server - All in One 单点方式,提供 Docker image ,单点 VM 可以支撑 100 万 Data Points/s。
VM - Cluster - 集群版,拆分为了 vmselect、vminsert、vmstorage 3个服务,提供 Operate ,支持水平扩展;低于百万指标/s建议用单点方式,更易于安装使用和维护。
Qunar 单集群 Total Data points 17万亿,采用的是 VMCluster 方案。另外对于指标采集和告警,需要单独以下组件
可选,可按自身需求选择是否使用如下组件替代现有方案。如果只是将 VM 作为 Prometheus 的远程存储来使用的话,这两个组件可忽略,仅部署 VM - Single 或 VM - Cluster ,并在 Prometheus 配置 remoteWrite 指向 VM 地址即可。
VMagent VMalert
vmstorage 负责提供数据存储服务;
vminsert 是数据存储 vmstorage 的代理,使用一致性hash算法将数据写入分片;
vmselect 负责数据查询,根据输入的查询条件从vmstorage 中查询数据。vmselece、vminsert为无状态服务,vmstorage是有状态的,每个服务都可以独立扩展。

可以直接替代 prometheus 从各种 exporter 进行指标抓取
相较 prometheus 更少的资源占用
当抓目标数量较大时,可以分布到多个 vmagent 实例中并设置多份抓取提供采集高可用性
支持不可靠远端存储,数据恢复方面相比 Prometheus 的 Wal ,VM 通过可配置 -remoteWrite.tmpDataPath 参数在远程存储不可用时将数据写入到磁盘,在远程存储恢复后,再将写入磁盘的指标发送到远程存储,在大规模指标采集场景下,该方式更友好。 支持基于 prometheus relabeling 的模式添加、移除、修改 labels,可以在数据发送到远端存储之前进行数据的过滤
支持从 Kafka 读写数据
与 VictoriaMetrics TSDB 集成
VictoriaMetrics MetricsQL 支持和表达式验证
Prometheus 告警规则格式支持
自 Alertmanager v0.16.0 开始与 Alertmanager 集成
在重启时可以保持报警状态
支持记录和报警规则重放
轻量级,且没有额外的依赖
Qunar 的 VictoriaMetrics 架构

采集方面使用 vmagent 并按照服务维度划分采集目标分为多组,且每组双副本部署以保障高可用。各集群互不相关和影响,通过添加env、Cluster labels进行环境和集群标识
数据存储使用 VMcluster,每个集群部署一套,并通过 label 和 tolerations 与 podAntiAffinity 控制 VMcluster 的节点独立、vmstorage 同节点互斥。同一集群的 vmagent 均将数据 remoteWrite 到同集群 VM 中,并将 VM 配置为多副本存储,保障存储高可用。
部署 Promxy 添加所有集群,查询入口均通过 Promxy 进行查询
Watcher 中的 Prometheus 数据源配置为 Promxy 地址,将 Promxy 作为数据源
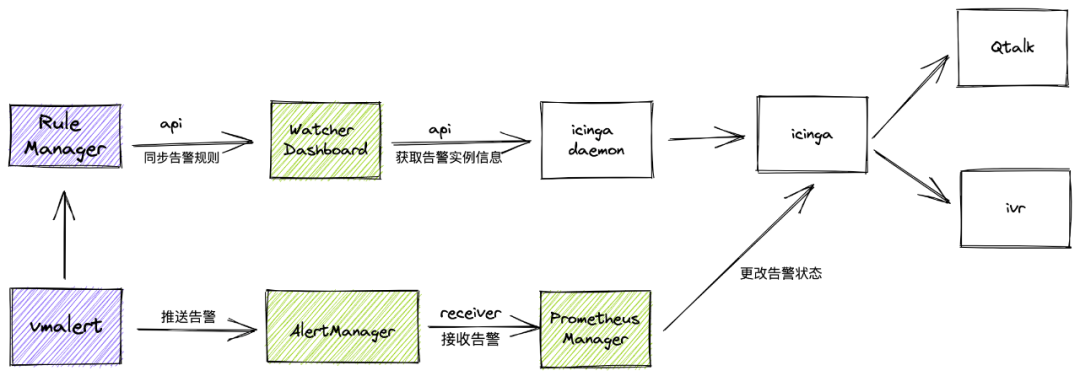
告警方面使用了 vmalert,并在 Qunar 告警中心架构上,Watcher 团队自研添加了 Rule Manager、Prometheus Manager 两个模块。
· Rule Manager 表示的是 rule 同步模块,将规则同步至我们 Watcher Dashboard ,用于用户查看和自定义修改,便于一站式管理。同时也继续沿用原有告警实例信息同步 icinga daemon 逻辑。
· Prometheus Manager 模块主要是实现了 reciever 接口,接收 alertmanager 的 hook ,然后更改 icinga 的报警状态。
· 后对于 vmalert 本身状态,则是采用拨测监控实现。于此以小改动代价融入至 Qunar 现有告警中心。
VMCluster:定义 VM 集群
VMAgent:定义 vmagent 实例
VMServiceScrape:定义从 Service 支持的 Pod 中抓取指标配置
VMPodScrape:定义从 Pod 中抓取指标配置
VMRule:定义报警和记录规则
VMProbe:使用 blackbox exporter 为目标定义探测配置
完全替换后的表现
Qunar 容器化已将全环境集群的原 Prometheus 方案全部使用 VM 解决方案进行替换,所有的应用都是使用 VM-Operate 完成部署和管理的。
替换后其中某集群的数据表现如下:
| Active time series | ~28 Million |
| Datapoints | ~17 Trillion |
| Ingestion rate | ~1.6 Million/s |
| Disk usage | ~8 TB |
| Average query rate | ~450/s |
| Query duration | median is ~300ms, p99 ~200ms |
后续准备做的几个优化
VM 开源版本不支持 downsampling ,仅企业版中有。对于时间范围较大的查询,时序结果会特别多处理较慢,后续计划尝试使用 vmalert 通过 recordRule 来进行稀释,达到 downsampling 的效果。
其实很多应用如 Etcd、Node-exporter 暴露出来的指标里有些是我们并不关注的,后续也计划进行指标治理,排除无用指标来降低监控资源开销
总结
本文介绍了 Victoriametrics 的优势以及 Prometheus 不足之处,在 Qunar 替换掉的原因以及替换后的效果展示。也分享了 Qunar 对 VM 的使用方式和架构。
使用 VM 替代 Prometheus 是个很好的选择,其它有类似需求的场景或组织也可以尝试 VM 。如果要用直接的话来形容 VM ,可以称其为 Prometheus 企业版,Prometheus Plus 。
后,任何系统、架构都并非一劳永逸,都要随着场景、需求变化而变化;也并没有哪种系统、架构可以完全契合所有场景需求,都需要根据自身场景实际情况,本着实用至上的原则进行设计规划。
