本期作者

陆志君
数仓平台数据开发工程师
01 从BitMap到RoaringBitMap
在海量数据背景下,需要快速对数据进行评估、计算和中间存储,一系列专门为大数据准备的数据结构应运而生。比如HyperLogLog、BloomFilter等,可以快速利用小存储预估出指定的数据量。这些都是基于概率的算法,虽然运行速度快但并不能获得准确数据量。
BitMap可以解决这类问题,是数据领域和搜索引擎中很早就出现的的数据结构,例如在Java中BitSet可以用来替代HashSet做数字去重,在Redis中也有setbit和getbit直接操作BitMap,其底层实现都是直接翻译成0|1二进制结构。但其存在以下两个很明显的问题:
1. BitSet 内部的 long[ ] 数组是基于向量的,即随着 Set 内存放的大数字而动态扩展。数组的大长度计算公式:(maxValue−1)>>6+1 ,也就是说当存储一个较大值进去,就直接可以让内存占用M级别以上,过大的值域将会导致 OOM(比如指定 Long.MAX_VALUE)。
2. 以一个 BitMap存储40亿个数据为例,基于32位的Unsigned Int,大概消耗232bit=229B=29MB=512MB内存,但当数据稀疏的时候,也需要要开辟这么大的内存空间,就发挥不出其存储效率。
为了解决位图不适应稀疏存储的问题,很多研究者提出了各种算法对稀疏位图进行压缩,减少内存占用并提高效率。比较有代表性的有WAH[1]、EWAH[2]、Concise[3],以及RoaringBitmap[4]。前三种算法都是基于行程长度编码(Run-length encoding, RLE)做压缩的,而RoaringBitmap算是它们的改进版,更加,因此本文重点探讨它。
RBM当前有两个版本,分别用来存储32位和64位整数。以32位为例,RBM首先会对其划分为16+16,前16位用来存储Container位置编号,后16位用来存具体Container内容。例如数字31,被存储在第31/216=0个位置的Container中。值得注意的是Container是在需要创建的时候才会开辟,而不是直接初始化所有位置的Container。
Container分几种类型,BitmapContainer[4]和ArrayContainer在早提出RBM的时候就出现了。BitmapContainer类型顾名思义,就是存储16位的BitMap,大可存储65536个数,空间开销固定为8KB,时间开销为O(log(1));ArrayContainer是用来满足稀疏存储而存在的,可以用以存储双字节类型的数字,大支持216/(2×8)=4096个数,空间开销为(2+2×c)B,c为基数,时间开销为O(log(n));RunContainer在18年提出[5],对连续序列采用RLE编码压缩,例如序列11,12,13,14,15会被压缩为(11,4),4表示11后面有连续4个数字,极端情况下如果序列都是连续的,那么终只需要4B,但如果序列是奇数或者偶数列,那不仅不会压缩,甚至还会膨胀两倍。类似ArrayContainer,RunContainer由可变长度的Unsigned Short数组存储RLE压缩后的数据,空间开销与它存储的连续序列数runs有关(简称r),为(2+4×r)B,时间开销为O(log(n))。后一种是SharedContainer,在进行RBM之间的拷贝的时候,有时并不需要将一个Container拷贝多份,可以使用SharedContainer来指向实际的Container,这样可以满足多个RBM共享同一个Container存储空间。
在指定位置编号的新Container上插入一个元素时,默认用ArrayContainer来存储;如果是插入连续序列元素时,例如API自带的addRange方法,会生成RunContainer;如果是一串不规则序列,RBM的Optimaze会根据插入后ArrayContainer和RunContainer的空间占用大小来选择。当插入ArrayContainer的容量超过4096(超出8KB),RBM自动将其转成BitmapContainer来存储;反之,如果BitmapContainer被删除后的元素个数小于4096,RBM根据Optimaze来决定转为ArrayContainer或者RunContainer。
基于其出色的存储和计算表现,RBM在各类大数据开源项目中均有一席之地,如下图所示,Kylin和Doris中用RBM来存储跨周期的全局字典,Iceberg中基于RBM用来做字段索引,Clickhouse专门设计了RBM的数据类型等等。下面介绍RBM在B站中的数据应用。

02 应用1:用户访问标记模型建设
用户/设备访问相关指标使用非常频繁,其历史新增、留存、访问频次、MAU等计算较为复杂而且多变,从通用建设角度来看资源耗费巨大,不同时间跨度的访问指标散乱,对使用方来说也不是很友好,需要有一套统一的用户访问标记方案,快速产出任意访问统计指标。
以留存计算为例,业界常见几种方案。
2.1 常见的访问标记方案
方案1:常见的操作就是直接对访问表进行join连接,如下图所示,日周月留存计算各需要维护三套重复逻辑。

优点:灵活,简单
缺点:开发成本较大,例如计算次月留存需要分别对本月和上月的访问用户去重连接计算。
方案2:利用外部引擎实现留存计算,例如ClickHouse自带的Retention函数
优点:适用于面向应用的场景快速产出留存指标
缺点:需要额外从Hive同步到ClickHouse,且没法和其他常用Hive表关联计算,不适用于通用基础模型
方案3:将访问记录转化为0、1通用bitmap访问标记,物理上以Array来存储。以每个日志分区记录用户90天的访问快照的话,数组中的两个元素可以分别存储30天和60天的访问记录,其中个数组元素实际存放昨天到前30天的访问情况,第二个数组元素实际存放前31天到前90天访问情况。分区每隔60天存放一次,近60天每天都存放一个日期分区。近90天内查询直接通过查近一个日志分区即可,若要查历史所有记录,只需把历史日志分区中存放60天的第二个数组元素做拼接,就可以完整保留历史所有访问记录。以3599天共计十年数据存储为例,只需要59+59个日期分区既可(59*60+59),而3600天只需60个日期分区即可。
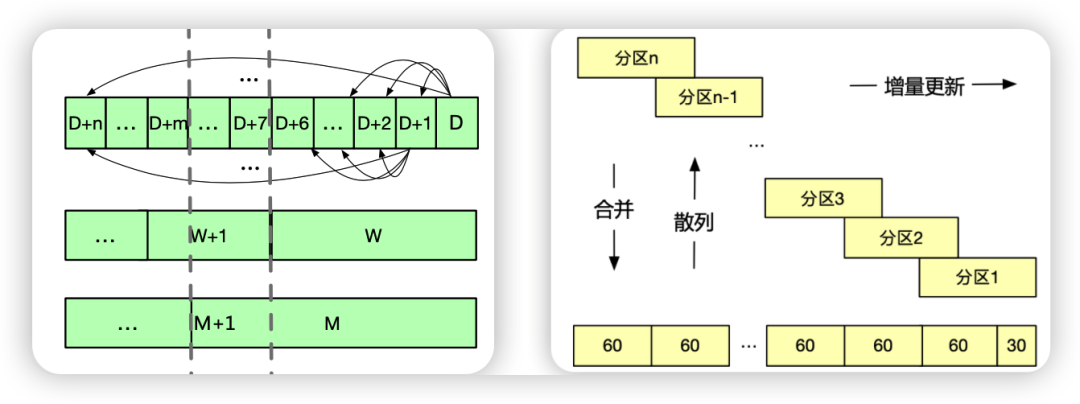
针对此存储可以做一系列定制化的UDF来算对应的访问指标。如下图所示:
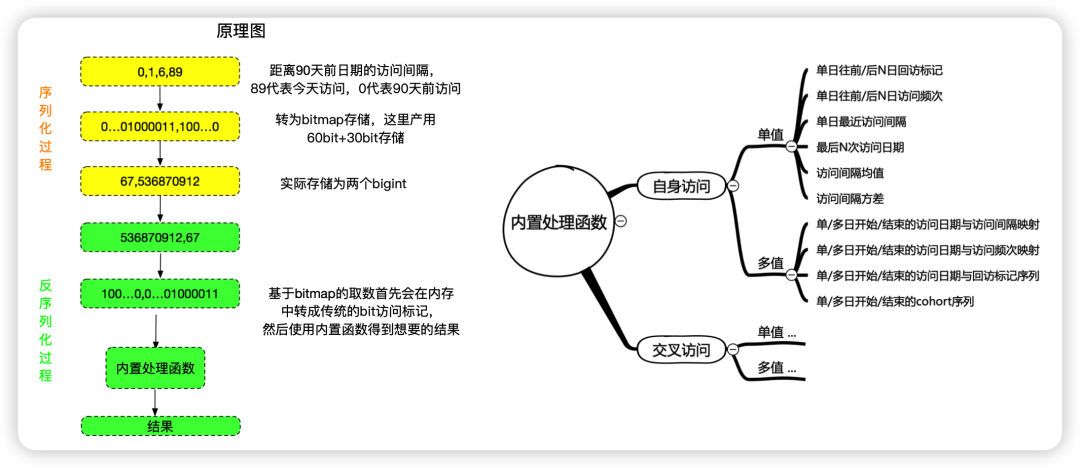
优点:查询速度极快,例如查询近30天是否有访问直接判断个数组元素大于0即可,判断90天某一天是否有访问,只需要对这天所在数组元素进行与运算即可。
缺点:通用bitmap还存在很大的压缩空间,另外查超过90天的访问情况,不同分区快照做拼接比较复杂。
2.2 基于RBM结构的访问标记方案
通用留存方案在设计留存表的时候需要提前预计算(先算)好对应留存指标,如果需要增改对应指标的话则需额外操作。可以直接将历史所有访问记录打包成RBM结构存储下来,利用提前封装好的UDF随取随用(现算)。相对于前面方案3,因为可以存放历史所有访问情况,不存在拼接问题,所以不光可以计算历史任意一天的留存,还能用来计算历史任意一天的新增、DAU、MAU、留存、访问频次等。
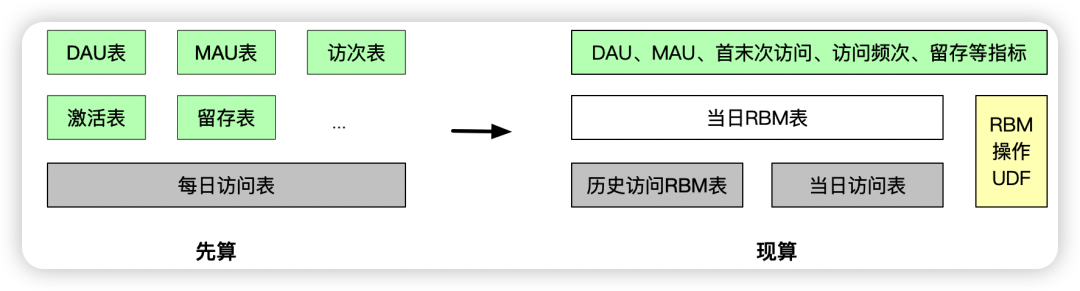
一个通用的访问标记范模型可以定义如下:
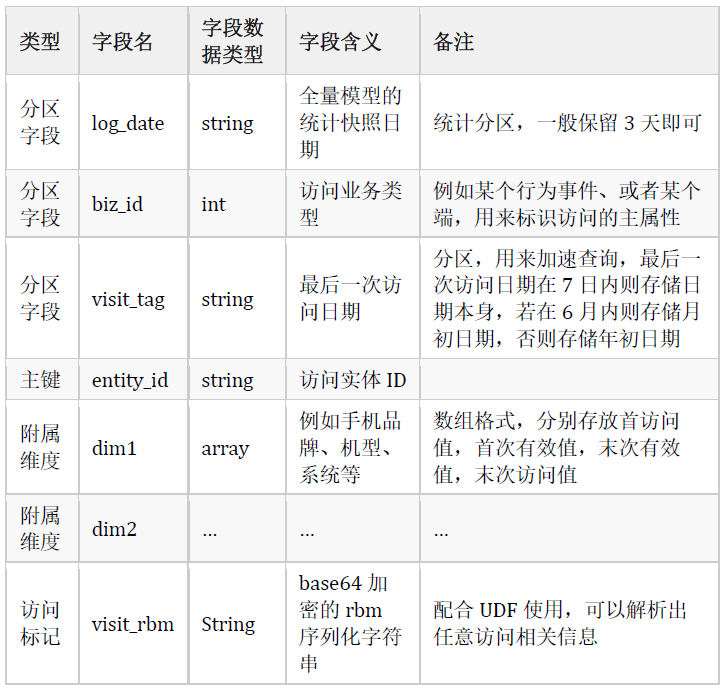
这个范模型的具体实现可以多种多样,在Hive层面需要使用T-2的分区数据和T-1的增量数据full join运算,如果是Iceberg、Hudi引擎可以直接增量更新,速度更快。
以下为开发好的操作RBM的一系列UDF,方便现算。
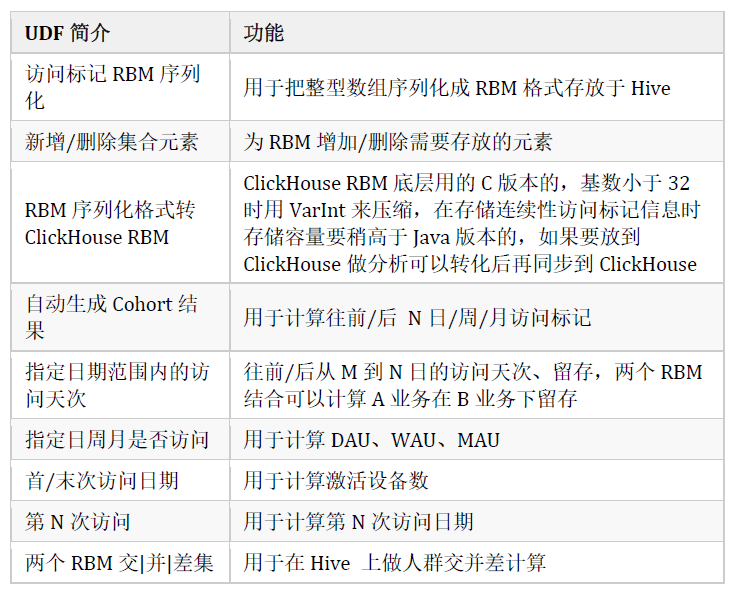
利用RBM构建统一的访问标记模型,数据上快速收敛了访问相关表重复读写逻辑,保证计算口径一致,缩短了整体数据链路,大大加速了取数效率。总计收敛7张下游核心表,下线30多张相关衍生模型,节约不必要的存储和计算开销。
03 应用2:人群包快速同步
Titan是B站用来创建和管理用户标签画像以及生成人群用来分析和应用的平台,RBM在其中有多项应用,比如用来存储枚举型标签、加速标签的交并差计算、存放业务圈选生成的人群包用以后续分析等。下图主要展示RBM人群包在事件分析中的应用:

一个RBM人群包的生成,从原始Hive表开始,正常链路如下图所示。先把hive标签表(用户ID+标签ID粒度)同步到ClickHouse集群上,针对可枚举类型标签会为每个枚举值在CK上创建对应的人群数组,然后通过CK物化视图创建对应的RBM表(RBM值在CK中是二进制,图中转为base64展示)。由于原始S0数据量往往非常大,单个标签值对应用户多的有十几亿,这不仅给数据同步造成很大的资源损耗,也对ClickHouse的集群资源要求非常高。

如果可以实现离线直接创建RBM人群包,就可以大大缩短链路,节约中间计算资源。新方案要求可以直接在离线引擎生成Hive版的RBM人群,然后通过同步任务直接从S0–>S3。当前离线引擎上支持的UDF主要是用Java实现,而ClickHouse完全是Cpp开发,这就要求离线创建的RBM能够在CK上实现兼容。
以64位为例,21.1版本之后的CK利用CRoaring[6]中的roaring64map[7]实现RBM,其核心存储结构的格式是 类型标记位(Byte),数据长度(VarInt),高32位基数大小(Long),实际数据的ByteArray(RoaringBitmap) 部分用1个字节是用来区分底层存储是采用SmallSet还是RBM实现的(SmallSet多存储32个),当基数小于32时标记位0,用SmallSet来存储,标记为1则继续用RBM;第二部分用来存储ByteArray的长度,而ByteArray用来存储实际数据,放在第四部分;第三部分用来标识高32位基数大小。
Java中RBM的常用实现库是RoaringBitmap[8],已经在Spark、Kylin和Druid等系统中得到了应用,Roaring64NavigableMap主要用来操作64位RBM,采用TreeMap多级存储来快速定位,其结构如下:

分析其代码可知,Roaring64NavigableMap序列化存储由是否long的标记位(Byte)+高32位基数大小(Integer)+实际数据的ByteArray(RoaringBitmap) 构成,实际数据的序列化部分与ClickHouse一致。知道两者的异同点后通过结构加减法很容易实现结构转换,配合Spark序列化工具kyro5可以很快实现hive明细人群转成兼容ClickHouse RBM的UDAF,然后创建出离线数据仓库中的RBM人群包。
特别提醒,获取高32位基数在Roaring64NavigableMap中是属于私有方法,不能被外部调用直接使用,可以使用Java反射来获取,例如:
Method method = rbClass.getDeclaredMethod("getHighToBitmap", null);method.setAccessible(true);(NavigableMap<Integer, BitmapDataProvider>) method.invoke(rb, null);
ClickHouse本地人群表创建代码示例:
-- 创建CK人群测试表CREATE TABLE new_titan.ads_titan_abtest_crowd_rbm_local on cluster bdp_tag_cluster(log_date Date COMMENT '日期',crowd_id UInt64 COMMENT '人群ID',type Int8 COMMENT '人群类型,ABTest:3',encode String COMMENT 'hive序列化存储',idx_bitmap AggregateFunction(groupBitmap, UInt64)MATERIALIZED base64Decode(encode),ctime DEFAULT now())Engine = ReplicatedAggregatingMergeTree()PARTITION BY toYYYYMMDD(log_date)PRIMARY KEY(crowd_id)ORDER BY (crowd_id,log_date)TTL log_date + INTERVAL 7 DaySETTINGS index_granularity = 5;
其中idx_bitmap利用了ClickHouse的物化列功能,由同步到CK的hive序列化存储字段自动生成。以10亿人群包为例,通过新的方案整条链路时间缩短85%(50min->8min),而整体开销较大部分是UDAF将明细标签记录转成兼容CK的RBM过程,数据同步部分实际不到半分钟,大量资源得以释放。
04 总结
本文阐述了RBM的基础原理和性能分析,比较了与原BitMap的异同点,与B站的一些大数据应用场景相结合来做方案改造,来达到降本增效、方便下游使用的目的。大数据方面还有很多方向可以做,比如通过RBM优化Redis中的bitmap,通过RBM来提高Flink存储和计算去重状态的性能,通过RBM用来做实时特征人群的存在判定等等,希望本文为大家提供解决类似问题的一种新思路,欢迎随时探讨。
以上是今天的分享内容,如果你有什么想法或疑问,欢迎大家在留言区告诉我们哦,如果喜欢本期内容的话,请给我们点个赞吧!
参考文章:
[1] Wu K, Stockinger K, Shoshani A. Breaking the curse of cardinality on bitmap indexes. SSDBM’08, Springer: Berlin, Heidelberg, 2008; 348–365.
[2] Lemire D, Kaser O, Aouiche K. Sorting improves word-aligned bitmap indexes. Data & Knowledge Engineering 2010; 69(1):3–28, doi:10.1016/j.datak.2009.08.006.
[3] Colantonio A, Di Pietro R. Concise: Compressed ’n’ Composable Integer Set. Information Processing Letters 2010; 110(16):644–650, doi:10.1016/j.ipl.2010.05.018.
[4] Chambi S , Lemire D , Kaser O , et al. Better bitmap performance with Roaring bitmaps[J]. Software—practice & Experience, 2016, 46(5):709-719.
[5] Lemire D , Ssi-Yan-Kai G , Kaser O . Consistently faster and smaller compressed bitmaps with Roaring[J]. Software Practice and Experience, 2016, 46(11):1547-1569.
[6] https://github.com/RoaringBitmap/CRoaring
[7] https://github.com/RoaringBitmap/CRoaring/blob/af9fafb72edcfb88f7adc781eaea4e7e95f68d01/cpp/roaring64map.hh6
[8] https://github.com/RoaringBitmap/RoaringBitmap
