简介
费了半天劲,今天终于装好SQL Server2012了。按照MSDN中的新特性资料(Columnstore Indexes for Fast DW QP SQL Server 11)。尝试了下ColumnStore Index。ColumnStore Index按照其字面意思所示。是基于列存储的索引。这个概念如图1所示。
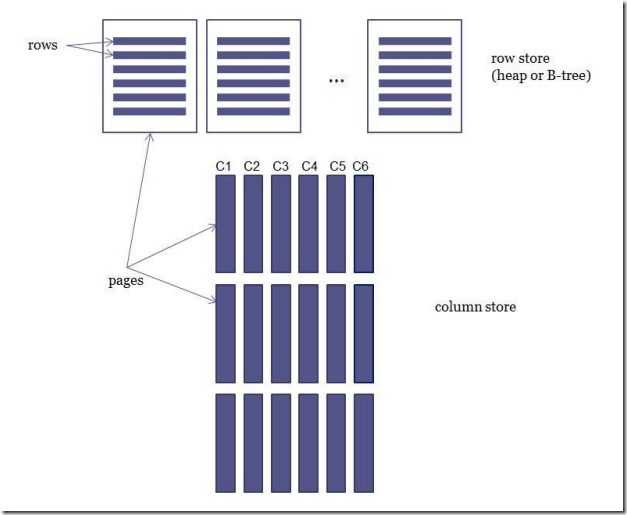
图1.ColumnStoreIndex和基于行的Index比较
ColumnStoreIndex是按照列存入页当中,而不是按照传统的以行为单位存入页。因此带来的好处可以归结如下:
- 以往的数据按照行存储,select哪怕只有一列,也会将整个行所在的页提取出来,而使用基于列的索引,仅仅需要提取select后面的列。提高了性能。
- 压缩更容易
- 缓存命中率大大提高,因为以列为存储单位,缓存中可以存储更多的页(缓存常用的列,而不是整个行)
微软号称自己是个支持“纯”列存储的主流数据库。其他数据库我不甚了解,有知道的同学可以反驳下……
使用ColumnStore Index不能像使用其它非聚集索引那样没有限制,使用ColumnStoreIndex的限制如下:
1.一个表只能有一个ColumnStore Index
2.不能使用过滤索引
3.索引必须是partition-aligned
4.被索引的表变成只读表
5.被索引的列不能是计算列
6.不能使用Include关键字
因此可以看出,中小型的OLTP环境基本和这个功能无缘。ColumnStore Index貌似适用于OLAP和读写分离用。
下面我们来看一些使用ColumnStore Index的实例
建立ColumnStore Index和对ColumnStore Index所在表数据进行更改
建立ColumnStore Index和建立普通的非聚集索引看起来基本没有区别,仅仅是多加了一个ColumnStore关键字,如图2所示。
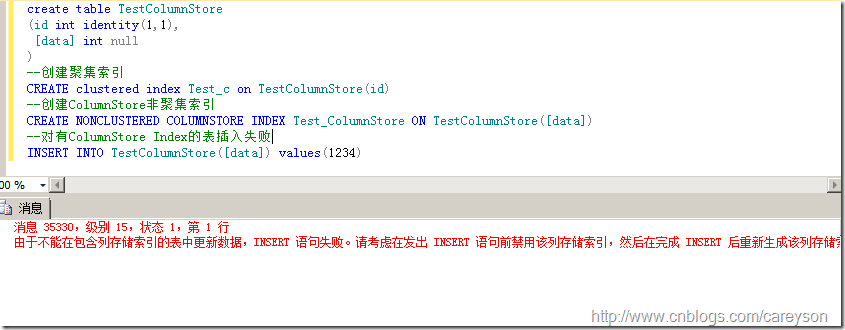
图2.建立ColumnStore Index的表后对其插入数据失败
如果要对有ColumnStore Index的表进行数据更改,则需要在停用ColumnStore Index后,插入数据,完成后,重建ColumnStore Index,如图3所示。

图3.对有ColumnStore Index的表进行数据插入
ColumnStore Index查询性能测试
ColumnStore Index带来的大好处是查询性能的增加。下面来进行测试。在刚才图1中所建的表中插入100万条从1到1000的随机数,如图4所示。

图4.插入100万条测试数据
然后在Data列上分别建立ColumnStore Index和普通的非聚集索引,如图5所示。
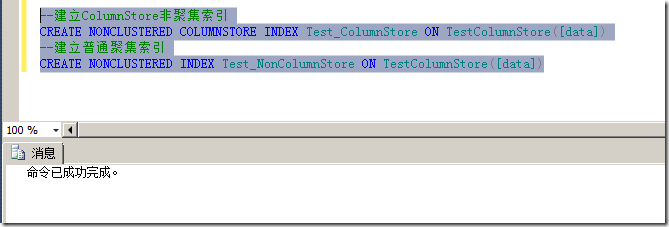
图5.分别建立两个索引
然后分别利用这两个索引做一次聚合查询,测试结果发现使用ColumnStore Index对IO的占用大大的减少了。如图6所示。
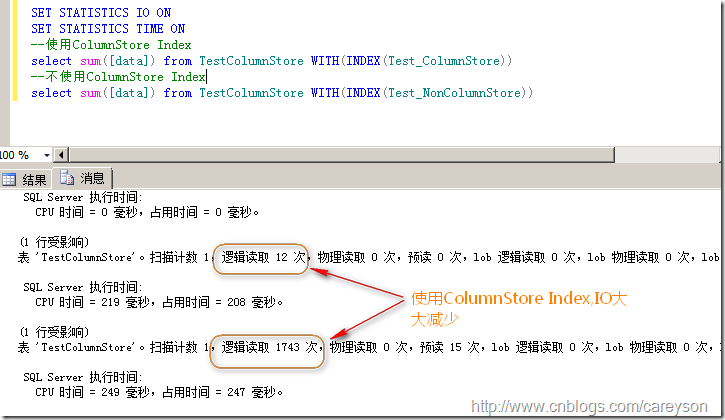
图6.使用两种索引的性能对比
所对应的执行计划如图7所示。

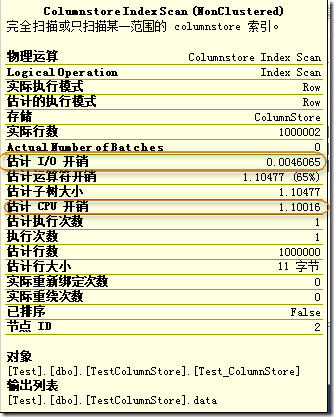
图7.两种索引的执行计划
可以看出,使用ColumnStore Index对性能的提升是巨大的。
总结
本文通过对ColumnStore Index做了简单的介绍后,做了简单的测试得出,使用ColumnStore Index对性能的提升是巨大的,但由于ColumnStore Index的使用受到诸多限制。目前只能在OLAP环境中使用。更多的使用场景未来再看吧。
本文来源https://www.cnblogs.com/CareySon/archive/2012/03/09/2387475.html
