背景
在互联网时代,大家都或多或少参与过"秒杀"一些热门商品,面对瞬时大量用户的秒杀请求,需要在应用的全链路做比较细致的优化,以此来应对高并发的请求。
比如秒杀场景下,应用端优化的核心思路一般分为如下几步:
动静分离。使尽可能多的页面主体能在用户端或者CDN上被cache住,只向服务端请求极少的数据,减少网络带宽 流量削峰。引入一些问答交互,或者是应用端的有界队列进行限流控制,保证落到后端计算的并发是可控的 数据校验。检查非法请求的判断,以及基于数据库终来保证库存扣减的一致性,避免超卖。
从上面的流程来看,数据库是承载了核心的数据一致性保障。虽然在业务端会做比较多的流控,但为了公平起见还是会有超过现有库存的并发请求瞬间流入到数据库中,需要数据库在满足在高并发下也能保证库存扣减不出现负数(出现超卖)。针对单一商品的秒杀促销,快速、频繁更新此商品的库存值,这件商品的数据行我们就称为热点行。
由于数据库在操作数据行时会加锁,大并发的更新操作导致行锁争抢,造成线程堆积,无法处理新的请求,数据库成为业务链路中的瓶颈点后,会导致整个业务发生雪崩,数据库崩溃等严重问题。
PolarDB-X 结合了阿里集团多年的双十一经验,设计了针对热点行更新的优化方案,以解决此类促锁场景下的热点行更新问题,本文主要介绍下PolarDB-X中支持热点行的优化思路和基本使用。
问题分析和方案设计
数据库中的库存问题
当我们购买商品时,一种可能的下单逻辑如下,开启事务后,首先在订单表中插入一条购买记录,随后在库存表中对该商品进行更新操作,后检查更新后的结果,如果一切正常,则进行提交,否则进行回滚。
商品按照更新的频率不同,整体可以分为两类:热门商品和非热门商品,对于热门商品的下单即为热点库存更新问题。
典型的库存扣减模型如下:
set autocommit=0;
insert 交易流水表;
update row from 库存表;
select row from 库存表; // 返回库存扣减的结果
commit;
显而易见,大量更新热门商品库存的线程会阻塞在update row,因为update的本质为lock-update-unlock,同一时间只能有一个线程对热门商品库存行进行更新。
这样就会带来两个问题,是同一个MySQL实例下非热门商品的QPS下降,因为整体数据库的连接数和资源有限;二是热门商品的QPS几乎归零,因为当大量请求(线程)会落到MySQL的同一条记录上减库存时,其需要争夺InnoDB的行锁,当一个线程获得了行锁,其他并发线程就只能等待(InnoDB内部还有死锁检测等机制会严重影响性能),因此当并发度越高时,等待的线程就越多,此时tps会急剧下降,rt会飙升。
那么,在热点库存更新这样一个场景中,我们看下 PolarDB-X 中是如何设计和优化类似热点更新问题。
优化网络交互减少锁时间
基于热点更新这一特殊场景,我们步可以想到对SQL进行优化,减少网络交互次数以及持有锁的时间,从而提高TPS。下单过程的网络交互如下所示:
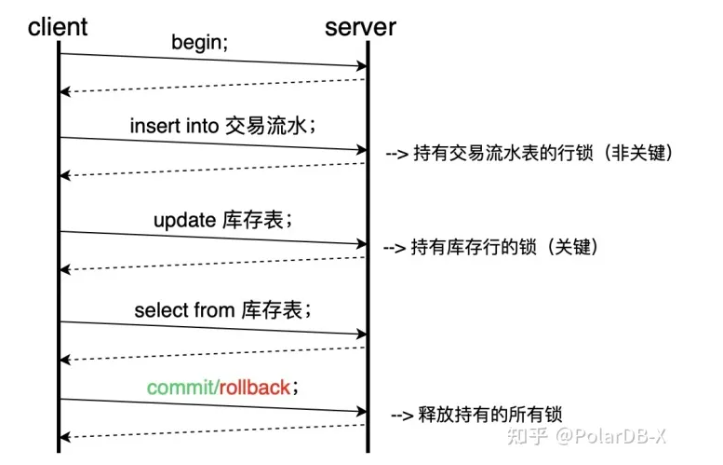
观察上述的交互流程,我们可以进行如下的优化:
select 总是紧随update之后,因此可以将其合并为select * from update 或者 returning语法获取库存表,如果update成功则返回update后的结果,如果update失败则返回错误。
commit信息可以被包含在sql中,update操作不报错且返回的影响行数符合预期时即进行commit操作,因此为了消除commit信息的交互,可在该sql中携带两个hint,即
select * /* +commit_on_success,target_affect_row x */ from update 库存表
其中x为预期的影响行数。
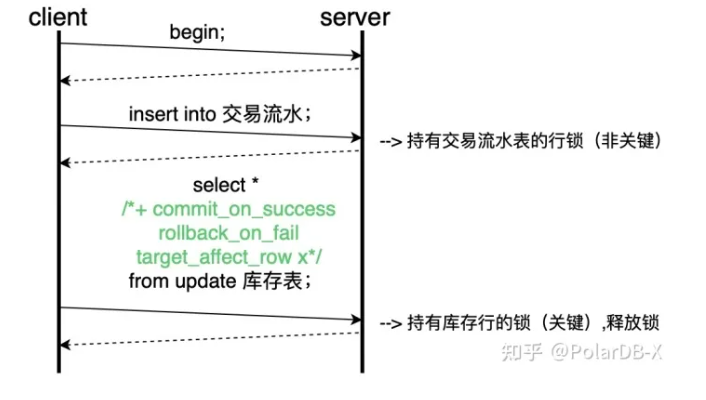
如果有任何异常或update的影响行数不符合预期时,则需要进行回滚操作,因此终的sql为
select * /* +commit_on_success rollback_on_fail target_affect_row x */ from update 库存表
优化后的网络交互如下所示,对比优化前的交互流程,我们发现网络交互次可以有减少,后update操作的持有锁的时间就可以缩短,单位时间内能支持的并发度就可以得到了提升。
基于组提交合并热点更新
由于在热点行的更新场景中,通过前面的业务模型分析,对热点行的操作均为该事务的后一条sql,且执行成功时必定会提交,因此PolarDB-X采用批处理(组提交)的方式以提高吞吐量,即采用lock-update-update-...-update-unlock的形式。
整体设计如下图所示:
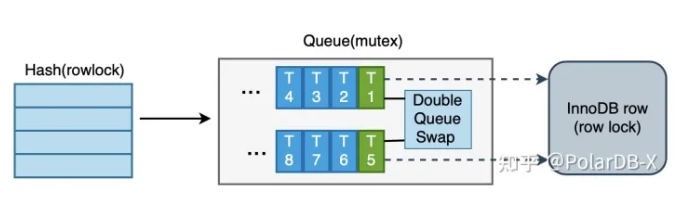
热点链路从上到下共有三层结构,每张物理表对应一个哈希表, 作为索引热点队列的入口,通过一把读写锁来保护 Queue是对某一行记录的队列维护,用于合并更新请求,通过一把mutex保护队列内容的更新 InnoDB Row 是存储引擎记录,通过数据库行锁机制进行保护,具有锁等待超时的能力,是热点以及非热点更新都必须要持有的锁。
为了更进一步提高对于热点更新行的处理,进行了两段流水线的设计,其中个阶段为打包收集热点更新sql并进行内存更新,第二个阶段为进行组提交。为了使用流水线方式处理这些更新操作,需要使用两个执行单元对它们进行分组。当个分组收集完毕准备提交时,第二个分组立即开始收集更新操作;当第二个分组收集完毕准备提交时,个分组已经提交完毕并开始收集新一批的更新操作,两个分组不断切换,并行执行。
其原理图如下所示:
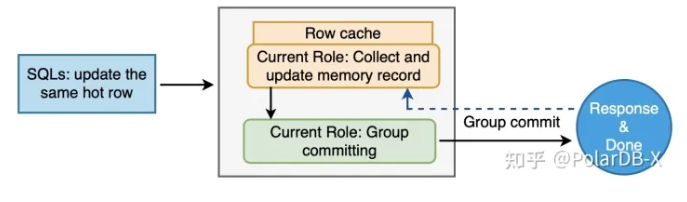
具体的执行流程为:
从Hash中获取Queue,a) 符合热点路径条件的Update(有commit_on_success标记),在更新执行前,先持有哈希表读写锁(先乐观探测),然后去哈希表中查找对应的Queue(找不到就分配新的Queue并插入),b) 找到或分配新的Queue以后,加Queue锁,并释放哈希表读写锁
Queue中的Leader加行锁,a) 个进到Queue的Update为Leader(此时持有上一阶段的Queue锁),去加存储引擎的行锁,此时有行锁超时回滚机制,b) 持有行锁以后,释放Queue锁
更新和提交,a) 在Leader持有行锁的情况下,Queue中的Leader和Follower分别更新内存记录,b) Queue中的Leader和Follower合成单次组提交,Queue在提交开始后就清空并进行下一次收集,c) 提交结束后释放行锁,并乐观的把没有再使用的Queue从哈希表中删除。
整个过程,通过引入了Queue的队列机制,将一批update热点行更新只进行了一次行锁获取 + 内存计算,实现了组提交的效果,从而提升了热点行更新的效率。
PolarDB-X中如何启用
基本使用说明 开启hotspot相关功能。在控制台的参数设置页面打开以下两个开关项,或者使用set global命令(非必须情况不建议使用set global指令)。
set global hotspot=on;
set global hotspot_lock_type=on
切换事务类型为XA,并在业务的update语句中添加hint。
set drds_transaction_policy=xa;
UPDATE /*+ commit_on_success rollback_on_fail target_affect_row(number)*/ table_reference
SET assignment_list
[WHERE where_condition];
注意事项
where条件应为主键或键的等值条件,且不支持带有全局索引的表(可包含本地索引)。 热点更新hint的使用场景为单分片事务,需要在单机事务中做优化,无法在跨多分片的场景中使用。
hint参数解读
commit_on_success(必选) 如果该语句成功,则进行提交,连同该语句之前的未提交语句一并提交。
rollback_on_fail 如果该语句失败,则进行回滚,连同该语句之前的未提交语句一并回滚。
target_affect_row(number) 校验更新的行数是否符合预期,若不符合则更新失败。
典型示例:添加commit_on_success以使用组提交等针对热点更新场景的优化(id为主键,使用如下语句对id=1的记录进行更新,需要满足有足够库存扣减并更新成功时,则实现自动提交)
例子:
set autocommit=0;
set drds_transaction_policy=xa;
UPDATE /*+ commit_on_success rollback_on_fail target_affect_row(1) */ table_test
SET c = c - 1 WHERE id = 1 and c > 0;
commit/rollback;
注意点:在update commit_on_success之后,如果紧跟一条其他dml语句,因为上一条的update sql已经会自动提交或回滚,这里会重新开启一个新的事务,无法满足事务保证。
具体的使用例子,可参考 如何支持热点更新场景
查看优化是否生效
使用命令show global status like "%Group_update%"查看组提交状态,Group_update_leader_count 一直增加则说明触发了热点组提交的优化逻辑。
mysql> show global status like "%Group_update%";
+---------------------------------------+--------+
| Variable_name | Value |
+---------------------------------------+--------+
| Group_update_fail_count | 54 |
| Group_update_follower_count | 962869 |
| Group_update_free_count | 2 |
| Group_update_group_same_count | 0 |
| Group_update_gu_leak_count | 0 |
| Group_update_ignore_count | 0 |
| Group_update_insert_dup | 0 |
| Group_update_leader_count | 168292 |
| Group_update_lock_fail_count | 0 |
| Group_update_mgr_recycle_queue_length | 0 |
| Group_update_recycle_queue_length | 0 |
| Group_update_reuse_count | 23329 |
| Group_update_total_count | 2 |
+---------------------------------------+--------+
13 rows in set (0.01 sec)
使用show physical full processlist查看update的状态,是否出现hotspot字样
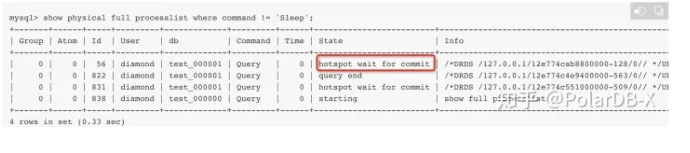
热点行更新测试
测试表定义
CREATE TABLE sbtest(id INT UNSIGNED NOT NULL PRIMARY KEY, c BIGINT UNSIGNED NOT NULL);
测试语句 (一条简单的cas原子更新模拟热点行操作,添加hint来触发PolarDB-X的热点行优化)
UPDATE /*+ COMMIT_ON_SUCCESS ROLLBACK_ON_FAIL TARGET_AFFECT_ROW(1) */ sbtest SET c=c+1 WHERE id = 1;
测试工具:sysbench
测试实例:4C16G×2 (两节点)
测试结果:
| 线程数 | 普通更新 | 热点更新 |
|---|---|---|
| 1线程 | 318 | 298 |
| 4线程 | 423 | 986 |
| 8线程 409 | 1872 | |
| 16线程 | 409 | 3472 |
| 32线程 | 412 | 6315 |
| 64线程 | 428 | 10138 |
| 128线程 | 448 | 13714 |
| 256线程 | 497 | 15803 |
| 512线程 | 615 | 23262 |
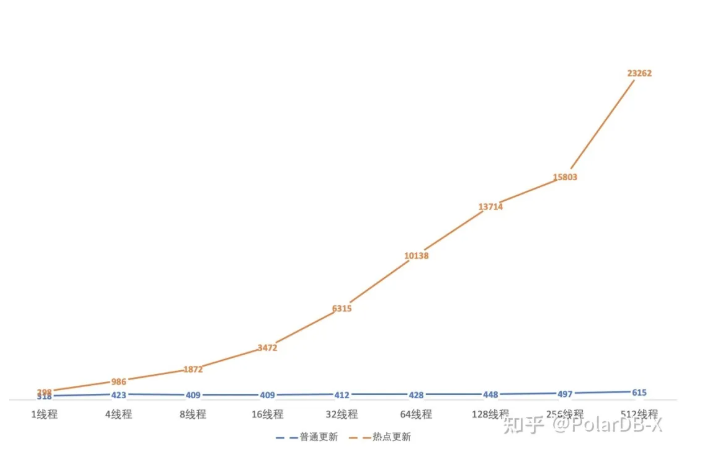
从测试的结果来看,因为引入了网络优化去除了多余的commit等待,以及基于组提交的合并更新,随着并发度越高带来的update吞吐会更明显,普通的小规格节点的峰值就可以达到2万+的吞吐量 (可支撑阿里双十一的秒杀峰值)
总结
PolarDB-X 作为一款分布式数据库,需要帮助用户解决海量存储+高并发的场景,分布式架构本身也会因为数据分布不均带来一些分区热点(存储空间、读写流量等),通过分区级别的分裂和负载均衡是可以有效消除这部分热点。但是热点行无法通过分布式的扩展和调度来解决,必须依赖于分布式数据库的内核特性,PolarDB-X 结合了阿里集团多年的双十一库存高并发的经验,在数据库内核级别提供了热点行的优化能力。
同时,PolarDB-X的姊妹产品PolarDB同样支持热点行的优化能力,详见:
https://help.aliyun.com/document_detail/178149.html
回顾热点行的更新场景,常见于库存、秒杀等场景,常见的业务基于redis做为前端缓存、或者基于MQ消息做异步化合并扣减等操作,之后再对数据库进行维护,也是一个比较行之有效的方案。
但是对于业务来说,要处理redis、MQ消息和数据库之间的数据一致性,可能会给业务带来一定的库存超卖等风险。PolarDB-X在数据库级别提供了热点行的优化能力,可以在保证数据一致性的前提下满足用户对高并发热点行的诉求,会是一种更好的技术选择。
来源:https://zhuanlan.zhihu.com/p/432580272
