TPC-H可以说是世界上为流行的OLAP workload的benchmark程序,无论你看什么样的论文或技术文章,只要是和查询处理过程相关的,大多会在evaluation时使用TPC-H作为评估工具。而如果你从事查询优化和执行的工作,则怎么都会和TPC-H打上交道,即使是OLTP(在线交易)型的数据库系统。
TPC-H是用来评估在线分析处理的基准程序,主要模拟了一个供应商和采购商之间的交易行为,其中包含针对8张表的22条分析型查询。
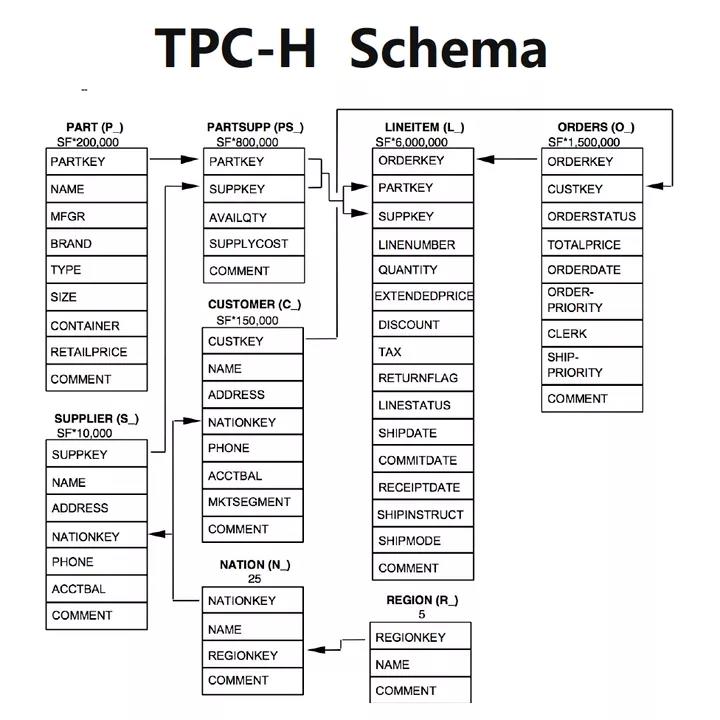
针对查询的处理性能方面,TPCH的测试中主要关注两个指标:
Power 单并发测试,单线程执行22条查询+ RF(INSERT + DELETE);
Throughput多并发测试,N个查询线程+ 1个INSERT/DELETE 线程。
而综合的打分是:
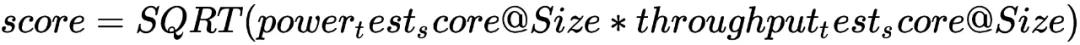
本文章是基于论文《TPC-H Analyzed: Hidden Messages and Lessons Learned from an Influential Benchmark》,这篇论文很有趣也很有帮助,它并不详尽的描述某个技术,而且深入的分析了TPC-H的查询中,可能存在的性能优化点和对应的优化思路。
它的基本思想是,作为一种流行且的benchmark工具,它不仅可以用来作为对查询处理系统的横向比较工具,更应该在benchmark中隐含一些具有技术挑战的点,为了具有更好的性能成绩,各路厂商会使用不同的解决方案去攻克这些点,而这也从侧面引领了技术发展的潮流。TPC-H在这方面起到了很好的表率作用。
瓶颈点(Choke points简称CP)
论文中把这种技术挑战点很形象的称为choke point,并对它们进行了分类,对每个CP都提供了一定的解决思路,除了论文中提到的,我也会简要描述下PolarDB继承于MySQL的现状以及SQL团队针对其中一些作出的改进。
CP一共分为6大类,共48个,如下图汇总:

上图中不同颜色的方框代表不同瓶颈点对于每条查询的影响程度,越深影响越大。
聚合性能(Aggregation Performance)
TPCH中有大量的group by + aggregation运算,如Q1, Q13这些查询,直接就是挑战聚集的计算性能。
CP 1.1 Ordered Aggregation
一般的聚集实现是通过hash aggregation,但如果group key数量较多时,hash table可能会比较大,超过各个level的cpu cache,这样cache + TLB(页表cache)的频繁miss,会比较大的影响查找性能。如果group key进一步增多,无法放入内存中,这时就需要spill to disk, spilling hash aggregation和hash join类似,也是先用一个hash func,拆分到若干file中,在每个file内各自做聚集计算。
这样的效果可能不如做ordered aggregation好,而且如果输入到分组的数据已经按group key有序(更一般的,只要具有相同的group key的tuple相邻即可),则ordered aggregation效果则会更好。
具体选择哪种方式,和可用的硬件资源 + 查询本身特性相关,而且为了准确评估优劣,group by的cardinality + cost需要较为准确的估算。
CP 1.2 Interesting Order
为了能够使用Ordered Aggregation,可以利用查询中的有序性,这种有序性可能来自两种:
1.通过clustered index扫描产生的元组有序性,被后续的算子保留从而传递到上层;
2.算子执行产生的新的顺序 (比如hash join的probe侧的顺序,nested loop join的外表顺序)。
针对以上两点,MySQL是支持hash/ordered 两种方式的aggregation计算的,但很可惜,这并不是由代价决定的,而是一系列硬编码的复杂判断逻辑。概略来说,如果group by列能够简单计算且仅依赖于join序列上个table,则可以尝试利用join table的有序索引(如果存在)或对其输出做filesort排序,来实现ordered aggregation,否则使用hash aggregation。这是由于MySQL重度依赖nested loop join且没有sort merge join的天然特性,因此其对顺序的利用都是始于个table。
CP 1.3 Small Group-By Keys
在做hash aggregation时,如果group by key的NDV(值个数)很小,可以用一个较小范围的整数值来覆盖,这样可以使用一个连续数组来计算aggregaion而不是hash table,连续数组cache locality要好很多,可以大幅提升性能,但这有一个基本前提:需要能较为准确的估算group key NDV。
相信除了SQL Server/DB2这种成熟的商业数据库(尤其是SQL Server,其Cardinality Estimation无疑是业界的),能对各类group by的值个数做较为精准估计的应该很少,但我们可以在满足特定条件时作出准确估计,从而利于应用这种优化。
例如MySQL,在group by key上有index时,是可以针对key prefix有较为准确的NDV估计的(density vector),此外8.0 histogram的引入也提升了cardinality估计的准确性,但社区版本中,histogram并不支持自动更新,严重限制了其实用性。
PolarDB在这方面已经做了很多工作,不仅对histogram进行了增强,也支持了自动更新,此外增加了算法支持利用index + histogram + filter进行单表group by NDV的估计,能够给出较为的结果,基于此去改造group by keys的数组实现,是较为简单的。
CP1.4 Dependent Group-By Keys
利用functional dependency,可以消除冗余group by key,例如Q10中,原始存在大量的group by列,基于c_custkey是主键这个条件,可以消减掉customer表其它列(主键决定了其他customer其他列),减少分组时做比较的cpu开销也节省了内存。类似的推导还有:

以上#xx 表示xx表的主键。
MySQL自身对group by/order by已经做了一定的优化,例如去掉常量的key,以及基于MySQL const table + 等值连接条件推导出的常量group key,以及基于主键的冗余key消除。但自身缺乏一套系统的推导functional dependency并基于其做优化的框架,这是很值得扩展的一个基础框架。
连接性能(Join Performance)
连接(JOIN)无疑是SQL查询中对性能为重要的运算,对于join order的选择,可以说是失之毫厘谬以千里。因此有很多可以优化的点,相关的论文也数不胜数,这里提到了几点。
CP 2.1 Large Joins
这里是指数据量较大的join,常见的join算法有hash-based/index-based, index-based可能会有二次回表的开销,引发较多随机IO,但如果数据都在内存就还好。
TPCH中大的两个表Order + Lineitem表的join,可以通过两种方式来调优:
1.通过cluster index,在nested loop join时,增加一些数据的Locality
2.通过table partitioning,并发做local join,在MPP系统中尽量减少网络数据发送。
由于历史原因,MySQL对于join的处理是重度依赖nest loop的,8.0之前甚至没有hash join,直至现在也没有sort merge join,它专为nest loop join实现了2种优化:
1.block nest loop join (BNL) ,为了减少内表的重复扫描次数,在外表获取一个block数据(缓存在内存buffer)时,才扫一次内表完成一批join;
2.batch key access (BKA) ,原理与BNL相同,但内表上是index lookup,因此除了外表缓存一批,还会在与内表join后,把内表的primary key再缓存下来进行排序,从而把内表回表的random IO转变sequential IO,提升性能。
基于以上2个优化,可以看到对于TPCH这种star schema,如果有外键索引,MySQL速度还是相对不错的,否则就非常糟糕。
8.0后,MySQL引入了hash join,但社区版本存在很多的局限性:
1.hash join的选用完全是基于规则,将优化器选择的BNL硬替换为hash join,因此如果有index,则完全不考虑hash join,即使其执行更优;
2.无index时,由于join ordering的选择不准确,导致在build侧存在大量中间结果数据,出现很多磁盘交换;
3.单线程执行。
为此PolarDB针对性做了很多工作,例如:
1.为hash join建立代价模型,可以基于代价更加准确的在index nested loop join和hash join之间选择;
2.利用有效的histogram提升join cardinality估计的准确度,选择更优join order;
3.基于共享build hash table的形态,实现了non-partitioned parallel hash join。
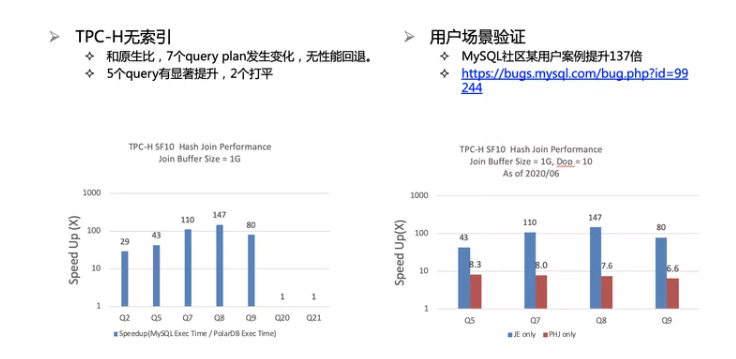
上图给出了前两项优化后对社区版本在TPC-H SF10上一些查询的性能对比,由于社区不支持并行处理,就没再比较parallel hash join的提升了。
CP 2.2 Sparse Foreign Key Joins
在TPC-H中,大量的join都是主外键join,而且在主表上,对主键都有一定的过滤条件,这样就导致在外键去match时,一般是join不上。因此可以利用bloom filter,在build hash table时建立bloom filter并传递给probe侧。Bloom filter一般较小,可以保持在CPU cache中,因此过滤效率比hash table要好很多。
此外,Bloom filter应该尽可能下推到probe侧,好能推到存储层,在scan时尽早避免后续的CPU计算,在MPP系统中,可以在传输probe数据前,先传递bloom filter来减少数据传输。
针对这个优化,MySQL不存在这个问题,因为如果有主外键,它是一定是要nest loop join的,但值得一提的是,PolarDB的hash join实现了基于bloom filter的预过滤功能。
CP 2.3 Rich Join Order Optimization
在多表join时,应该尽可能枚举所有可能的join方式,来选取优order,例如利用DPccp/DPhyp这种基于join graph的高效enumeration算法,关于DPccp/DPhyp可以参考以下2篇论文:
Analysis of Two Existing and One New Dynamic Programming Algorithm for the Generation of Optimal Bushy Join Trees without Cross Products
Dynamic Programming Strikes Back
MySQL基于greedy search的join ordering算法搜索空间是受限的,只能支持线性的left-deep tree,所能支持的表数量也较少,而且一旦大于一定阈值就引入greedy策略,因此社区在8.0.2x版本中开始引入新的hypergraph优化器,目前还是开发中,估计在9.0才能General Available。
针对这方面,PolarDB也在做一些工作,例如在一定情况下引入bush join的选项并基于cost与left-deep tree做比较,目前也是开发中。
CP 2.4 Late Projection
这是针对列存特有的优化,可以在table scan时,对于早期算子不使用的列不去scan出来,但这里会有个trade-off,因为随着plan tree的上升,tuple的数据倾向于越来越稀疏,因此scan会越来越离散,无法利用顺序IO/Prefetch IO的优势。
因此晚物化比较理想的场景是,当需要后获取时,所涉及的tuple数量较少,比如有聚集,或者有Top-N的场景。或者是在join时只获取join key列,当match上时才把其余的column读取出来,由于列数据本身是按照row group来拆分的,每个row group内的一批数据形成一个block,因此可能跳过很多block,避免做IO/decompression的开销。
数据访问位置(Data Access Locality)
CP 3.1 Columnar Locality
这是列存的天然优势,紧凑的数据布局有益于cache locality,并且可以做压缩来减少IO开销,利用向量化技术以及基于SIMD指令集的计算原语,实现高效的算子内并行,提升算子执行效率。
Oracle近也推出了其云上的Heatwave service(RAPID),本质就是一个分布式的in-memory column store,利用了Oracle一些特殊的硬件优化技术配合列存的向量化+压缩态计算来实现高性能计算,以及利用in-memory的binlog快速同步来支持一致性读取,不过这方面的资料还比较少。
CP 3.2 Physical Locality by Key
通过聚簇索引提供数据访问的局部性,尤其对于datetime这类的列,在TPCH中,很多datetime的列都是具有相关性的。
可以利用这种相关性,把基于某个日期列的range条件,传递到其他相关的日期列。
1.clustered index,如果数据是按照日期组织的,那么两表的join 大体上会比较有序的(两个join key,有一定时序上的语义的关联性,比如发货 -> 收货),但是优化器必须可以识别这种相关性。
2.table partitioning,通过range partition,可以比较好的做partition pruning,在做主外键join时,可以在外键表上,对每个partition,针对每个对应的主键表,维护一个pruning bitmap,从而加速join过程,这些pruning bitmap可以在做主外键约束检查时进行更新。
CP 3.3 Detecting Correlation
这是cardinality estimation的老大难问题了,这里包含2个子问题:
1.如何捕获2列之间的相关性 -> 目标列是什么?
2.如何量化衡量2列间的相关性 -> 如何描述相关性?
针对个问题,一般会采用查询反馈的方案,也就是在初始时,并不假定其相关性,然后在查询实际执行中,利用feedback机制获取实时的准确统计信息来发现原始的假设并不成立。类似的方案有很多,例如Oracle的adaptive statistics ,DB2的LEO ,HANA的Statisticum···不过基本前提都一样,就是要有完备的实时采集和feedback机制。
针对第二个问题,商业数据库系统处理的比较完善,例如Oracle的多维histogram/column group zone map,SQL Server的expression statistics等,不过多维histogram的维护成本是很高的,因此针对多列的简单组合统计信息是更常见的方案,MySQL只有基于index prefix的density vector这种机制来记录多列组合的NDV。
查询反馈循环是非常重要的,PolarDB已经实现了部分基础设施和框架,不过目前主要还是用于histogram的自动更新和plan management的演进,后续会不断扩展来与更多功能组件结合。
表达式计算(Expression Calculation)
CP 4.1a Arithmetic Operator Performance
对于decimal类型的存储,如果转换为double,会损失精度,如果转为字符串则效率太低。常见的方式是通过 * 10xx倍后,将小数转换为整数,在TPCH的规则中,大的decimal整数也只需要42-bit,用64bit整数可以保存+计算,但这样对于256bit SIMD寄存器效率太低了,因此可以考虑根据不同数据列的取值范围,采用不同的bit位数来存储,从而尽可能提升SIMD的利用率。
当然,这是一种针对TPC-H数据特性的特殊优化,并不具有普适性。
MySQL使用一个数据结构my_decimal来表示decimal数据,其中包含一个9字节的buffer和3个int数值,分别描述整数部分长度/小数部分长度/buffer有效长度。其计算涉及到精度变换,类型cast等,效率很低。我们在PolarDB中也实验性的测试了使用64bit整数来简化其计算的方案,在纯数值计算上产生了很大的性能提升,但由于没有通用性,终没有采用。
CP 4.1b Overflow Handling
对数值的计算结果做溢出检查成本是比较高的,因为会使用if - else分支,破坏CPU流水线。一种乐观方案是可以根据数据的类型,range的范围和可能的计算方式,提前预测其不会overflow,就可以避免这种检查了,至少TPC-H中可以利用这种优化。
CP 4.1c Compressed Execution
列存一般都具有压缩机制,比如可以利用RLE(Run Length Encoding)编码,直接在压缩态计算全量的聚集函数(不能带group by key),再针对结果进行解码。或者利用dictionary编码,基于dict index做谓词过滤,这时只涉及整数的比较,可以更高效的利用SIMD。
CP 4.1d Interpreter Overhead
对于expression tree,由于其复杂的分支递归结构,做解析执行的成本很高,可以通过JIT / Vectorize 来提升效率。
向量化或编译执行是2个非常大的话题,无论学术界还是产业界都有广泛的应用,各自适用于不同的场景 。
不过大体来看,TP(事务)型的系统更偏向于编译执行(如Postgres / OceanBase / SQL Server...),因为行存的格式应用向量化或批量计算一般无法产生显著效果(cache locality不好),但TP workload经常具有高度类似性的查询,使得高昂的compilation成本可以被均摊掉。而AP(分析)型系统则由于是列存,更适合于使用向量化的计算(Vectorwise/HANA/ClickHouse ...)。当然还有像CMU Peleton这样的系统,尝试将二者结合起来 。
在这方面,PolarDB列存已经支持了向量化的数据列计算,并有了完备的基于SIMD instruction的计算原语,不过编译执行目前还没有尝试。
CP 4.2a Common Subexpression Elimination
比如投影列中的AVG -> SUM / COUNT ,那么可以把重复的聚集操作去掉。
这是MySQL比较薄弱的一方面,在其优化逻辑中,经常会插入更多的用于终结果计算的额外表达式,但这些表达式可能与已有表达式重叠,但它没有精细的区分与处理,PolarDB中之前还修复过一个bug:对于已计算完成的标量子查询,会在后续执行中再次反复计算。
CP 4.2b Join-Dependent Expression Filter Pushdown
对于比较复杂的逻辑表达式condition,可以尽量拆分成和单表相关的多个条件的AND组合,从而各自推到单表上执行。
相对来说,这算是MySQL的一个强项。在make_join_select()函数中完成了对where condition的拆分和下推到尽可能底层的算子中,由于MySQL对于表达式的优化还算全面,支持多轮的常量折叠/等值传递/等价性推导,也包括针对二级索引列下推到存储层的index condition pushdown等。
CP 4.2c Large IN Clause
在TPC-H中有一些IN表达式,但涉及的值并不多,这时可以转换为 (xx or xx … )的形式。此外在很多分析场景中,自动生成的IN-list会有大量的value,这时可以将list构造为一个hash table,通过semi-join probe的方式来提升过滤效率。
MySQL对于IN的优化是,如果可以使用index,则用index进行range scan,否则使用table scan,因此并没有这种hash table probe的能力。之前在线上也多次碰到用户有大量IN表达式的需求,只能通过显式建立临时表,走semi-join的方式来改写SQL,还是比较尴尬。
因此这是一个很值得做的优化。不过需要有cost based transformation的能力,PolarDB正在做这方面的工作。
CP 4.2d Evaluation Order in Conjunctions and Disjunctions
在优化阶段,可以根据不同子条件的选择率,尽量将选择性好的子条件放在前面计算,从而尽早过滤。但选择率估计可能不准确,而且很多数据的选择率本身也是随着执行不断变化的。因此很多系统都可以在执行中,动态根据监控到的选择率改变各个子条件的evaluation顺序。这属于自适应执行的一个功能,目前PolarDB还没有这样的能力,不过可以想见,一旦有了比较完善的运行期监控+反馈机制,实现这个功能难度不算大。
CP 4.3a Raw String Matching Performance
X86指令集中扩展了SSE4.2的原语,能够在一个SIMD的指令中对16byte的字符串做比较。这可以很大提升字符串比较的效率(相对strcmp)。但一般谓词的比较,在大多数情况下都会很早的不匹配而退出,因此使用SIMD没有很好的效果,但如果是group key的比较,则命中率会高很多,更适用于SIMD。
相关子查询(Correlated Subqueries)
TPCH中的相关子查询都可以被展开,转换为多种形式的join (outer join/anti join/semi join)。
CP 5.1 Flattening Subqueries
TPCH中很多条查询都具有相关子查询的construct。
相关子查询的解相关是查询转换中为常见的一种,如果无法很好的优化,则可能导致严重的性能问题。这个问题在MPP的环境下则更为严重,相关性语义会导致大量的数据传输,无法高效并行执行复杂查询。
因此比较成熟的优化器都有一套完整的子查询处理机制,例如Oracle针对subquery unnesting有多种不同的方案(基于window function/基于derived table/子查询展开),SQL Server则基于apply算子实现了一套完整的子查询解相关的等价变换。
长时间以来,MySQL对于相关子查询的处理是比较弱的。在8.0之前,只能支持IN -> semi-join的转换,或者IN 向EXIST的转换,进入8.0之后,开始支持EXIST -> IN -> semi-join的变换,而且开始能够支持NOT EXIST的语义(但无法支持null aware anti-join)。不过这些变换只能应用于简单子查询。近几个版本中,为了支持RAPID MPP engine,社区开始支持带有group by + aggregation的相关子查询向derived table的转换,不过也仅此而已。
PolarDB在这方面也做了不少的工作,包括参考Oracle做基于window function的子查询解关联,以及IN子查询向derived table的变换等,而且目前我们正在实现cost based query transformation,解决MySQL长期以来完全基于heuristic rules的变换策略。
CP 5.2 Moving Predicates into a Subquery
这里是指像Q2/Q17/Q20这样的查询,在条件中使用相关子查询的聚集结果作为外层的过滤条件,这里还有个明显的特点,外层查询subsume了内层子查询(包含了相同的表和条件,且具有更多)。因此可以通过下推部分表+条件到子查询中的方式,来完成提前的过滤,PolarDB中实现了这个优化。
CP 5.3 Overlap between Outer- and Subquery
对于查询中外层查询块与内层查询块是subsume的情况 (外层包含内层的join tables + join 条件),在5.2中已经提到下推条件到子查询中,其实可以通过下推相关表+相关条件的方式,使整体变为一个非相关的derived table,这时内外侧公共的部分只需要在derived table物化时计算一次,避免了昂贵的重复计算。
并行和并发性(Parallelism and Concurrency)
CP 6.1 Query Plan Parallelization
随着现代硬件环境的变化,多核+大内存的配置变得越来越常见。对于多核上的查询并行,无论是从查询优化 还是查询执行,都是一项很有挑战性的工作。当然成熟的数据库系统(尤其是商业数据库)一般具有parallel execution的能力,开源的Postgres也有简单的基于parallel access table的并行计算能力。
不过很可惜,MySQL是没有这个能力的,这源于它丑陋的session紧耦合设计与复杂混乱的优化/执行结构。PolarDB的并行执行可以说是其提升分析查询能力的一项大杀器,对比AWS aurora基于smart storage的并行策略,PolarDB具有更大的灵活性和复杂算子的支持能力。而对比华为TaurusDB,感觉它还处于开发的初级阶段,PolarDB在功能上的成熟度和扩展性上已经远远的领先了对手。
PolarDB的并行执行也经历了从简单的并行表扫描向复杂的多阶段并行计划的演进。
CP 6.2 Workload Management
并行执行并不是无损的,理论上只要查询中有需要多个worker共享的资源,就会限制并行度的扩展,而且worker执行也是有资源消耗的。可以想见,随着并行度的不断增大,查询的执行时间不会无限成比例缩短,早晚会进入瓶颈。因此如果并发load很大时,理想的方式反而是每个查询串行执行互不干扰,这样可大化利用机器资源。
因此如何控制并行执行的资源占用是一个重要的问题,例如Oracle通过producer-consumer的调度+中间结果缓存机制,确保同一时间只有2组worker线程在运行,其cpu资源占用大为2 * DoP(并行度)。SQL Server由于有强大的系统控制能力,其底层实现了SQLVM封装层,将对系统资源的占用完全封装起来,它可以利用的CPU执行调度能力来细粒度控制worker的资源占用,确保不会溢出。而Greenplum就比较粗犷了,由于是multi-process模型,直接利用cgroup对资源占用进行控制。
PolarDB同样面临这个问题,目前我们关注的主要是cpu + memory两个方面:
1.对于memory,在执行一个parallel query时,会粗粒度的累计其占用的内存资源情况,后续在做并行优化时,会判断系统内存占用是否已过高,如果是则fallback到串行。
2.对于cpu,由于MySQL是没有细粒度的抢占调度能力的,因此并行优化器会基于不同stage算子的具体执行方式,通过调整stage DoP的方式,粗粒度的约束查询整体的cpu占用情况。虽然不能做到SQL Server那样的精细控制,但也可以保证不会溢出。
CP6.3 Result Re-use
可以对执行的中间结果/终结果进行缓存,供其他查询复用,是否做缓存取决于3方面的因素:
1.query result size;
2.query result获取的cost;
3.query result复用的频繁程度。
MySQL在5.7中引入过query cache,但由于其效果不好被废弃掉了,PolarDB重新基于这个patch做了大量改进工作,包括:
1.适配PolarDB的上下文
2.解决其在并发场景下争抢严重的设计缺陷,优化并发访问性能
3.改善失效机制
4.降低memory footprint
5.改善其可应用条件,提高适用性
6.修复若干bug...
总结
本文基于原论文描述了查询优化和执行中一些重要的优化点,以及MySQL的现状和PolarDB做的一些工作。未提及的内容其实还有很多很多,看完论文后结合自身的工作,大感受就是数据库的查询优化是一项复杂的工作,既需要系统性的规划,又需要一点一滴的持续改进,终会是量变产生质变。
这么多的技术方案,这么多的论文,哪些是我们应该去重点发力的呢?个人的浅见是,一些必要的基础框架是不可少的,列举如下(排序与重要性无关)
statistics + cardinality estimation
functional dependency
physical property
query transformation (cost based)
cost-based join ordering
query feedback loop
execution scheduling
......
有了这些后再在其中不断加入新功能,客户导向是个不错的选择,以满足客户需求为目标,在解决客户问题的过程中不断打磨自身的能力,即可以让系统贴近实际不偏离航道,又可以带给上下游团队足够的成就感。
关于我们
PolarDB 是阿里巴巴自主研发的云原生分布式关系型数据库,于2020年进入Gartner全球数据库Leader象限,并获得了2020年中国电子学会颁发的科技进步一等奖。PolarDB 基于云原生分布式数据库架构,提供大规模在线事务处理能力,兼具对复杂查询的并行处理能力,在云原生分布式数据库领域整体达到了国际领先水平,并且得到了广泛的市场认可。在阿里巴巴集团内部的佳实践中,PolarDB还全面支撑了2020年天猫双十一,并刷新了数据库处理峰值记录,高达1.4亿TPS。欢迎有志之士加入我们,简历请投递到yaoling.lc@alibaba-inc.com,期待与您共同打造世界的下一代云原生分布式关系型数据库。
来源:https://mp.weixin.qq.com/s/MewavCUuvFxNEzpJSxE1FA
