来自公众号:运维开发故事
什么是Kubernetes?
在《Docker容器技术》章节就有简单介绍Kuberntes,它是谷歌开源的容器容器集群管理系统,是谷歌内部容器管理系统Borg的开源版本。
Borg系统是谷歌内部使用很多的容器管理系统,在早期是采用Chroot Jail实现安全隔离,后期采用Namespace,资源隔离是采用CGroup实现。
为什么谷歌要推出Kubernetes开源版本呢?我个人的理解是:
使用开源社区的力量来解决谷歌未解决的问题 在云原生领域分一杯羹 推动云原生的发展,毕竟谷歌在容器领域已经玩了许多年了
Kubernetes具有以下特点:
便携性: 无论公有云、私有云、混合云还是多云架构都全面支持 可扩展: 它是模块化、可插拔、可挂载、可组合的,支持各种形式的扩展 自修复: 它可以自保持应用状态、可自重启、自复制、自缩放的,通过声明式语法提供了强大的自修复能力
使用 Kubernetes, 您可以快速高效地响应客户需求:
快速、可预测地部署您的应用程序 拥有即时扩展应用程序的能力 不影响现有业务的情况下,无缝地发布新功能 优化硬件资源,降低成本
Kubernetes是一个声明式系统,声明式系统和命令式系统是有本质的区别。所谓声明式系统关注点是做什么,即告诉你将要达成什么样的期望,至于怎么达到是你系统的事情。而命令式系统则是必须按照相应的规定或者步骤达到某个目标或者完成某个任务,其关注点是在怎么做。
命令式强调的是How,它需要你通过step-by-step的方式告诉计算机如何完成一个任务,在这种场景下,计算机是不具备“智能”,智能很机械的完成任务,至于完成的结果如何,需要看编程者的水平了。
而声明式强调的是What,你只需要告诉计算机你想要什么,然后由计算机自己去执行,这时候的计算机是具备一定的“智能”。当然,声明式不一定会满足你所有的需要。
在日常工作中,命令式编程比较普遍,这种编程实现比较方便,只需要按照一定的步骤开发即可,但是在一些特定的场合,声明式要比命令式方便,其实大多数声明式语言都是针对特定任务的领域专用语言,即DSL。
常见的声明式语言就是SQL,只需要告诉计算机你想要的结果集,数据库就会帮你设计获取这个结果集的执行路径,并返回结果。
Kubernetes就是一个声明式系统,在使用Kubernetes的时候,用户不需要去定义A->B->C这种Workflow,而是直接去描述一个期望状态,然后Kubernetes就会帮助用户达到这个状态,至于如何达到这个状态,用户不需要关心。这种设计使得Kubernetes更加易用和健壮,也更具弹性和扩展性。
Kubernetes的架构
Kubernetes整体是Master-Slave架构,如下: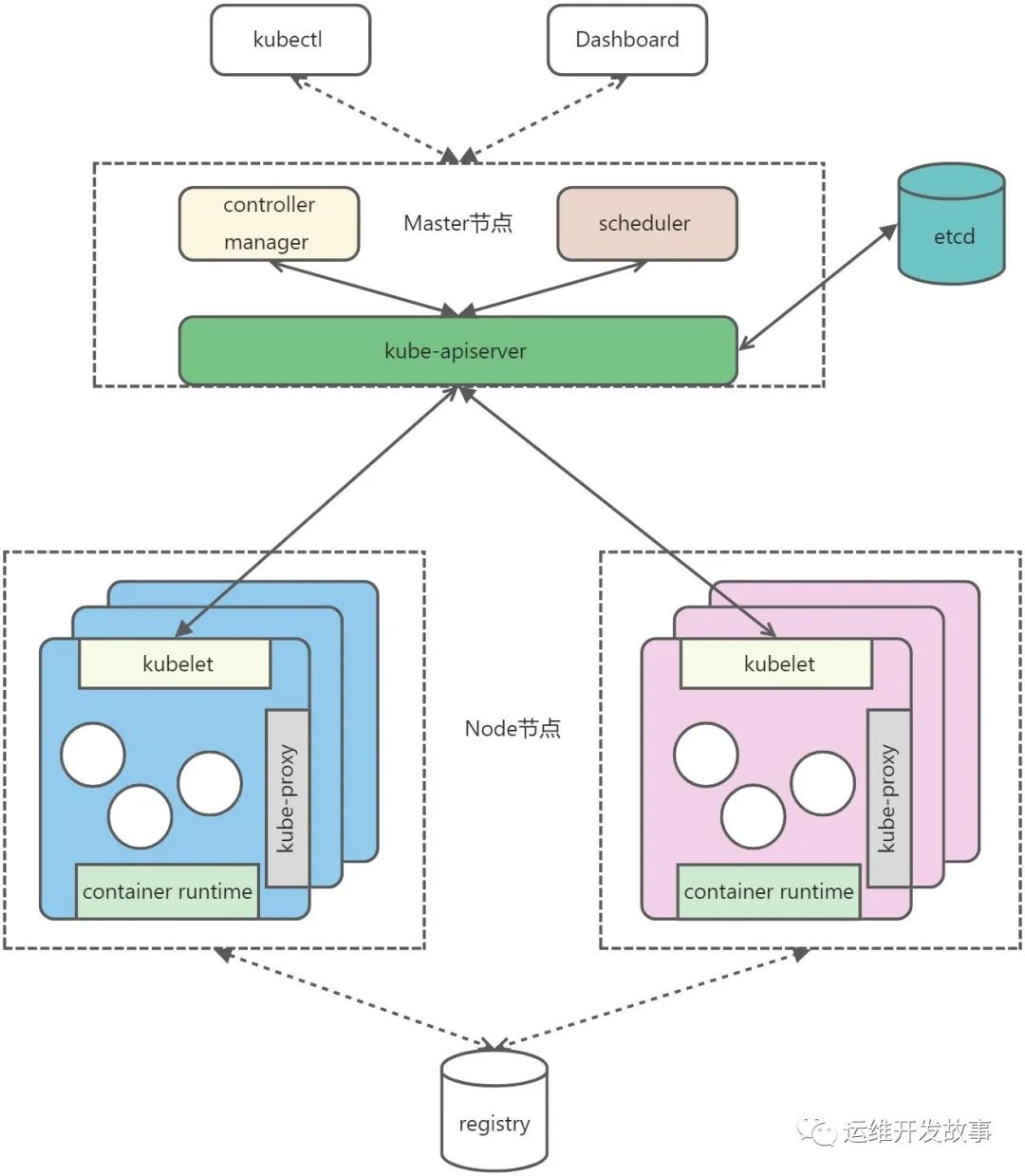
其中:
etcd 保存了整个集群的状态,就是一个数据库,只有API Server能与其通信; apiserver 提供了资源操作的入口,并提供认证、授权、访问控制、API 注册和发现等机制; controller manager 负责维护集群的状态,比如故障检测、自动扩展、滚动更新等; scheduler 负责资源的调度,按照预定的调度策略将 Pod 调度到相应的机器上; kubelet 负责维护容器的生命周期,同时也负责 Volume(CSI)和网络(CNI)的管理; container runtime 负责镜像管理以及 Pod 和容器的真正运行(CRI); kube-proxy 负责为 Service 提供 cluster 内部的服务发现和负载均衡; registry是镜像仓库,负责存储容器镜像 kubectl和dashboard都是客户端工具
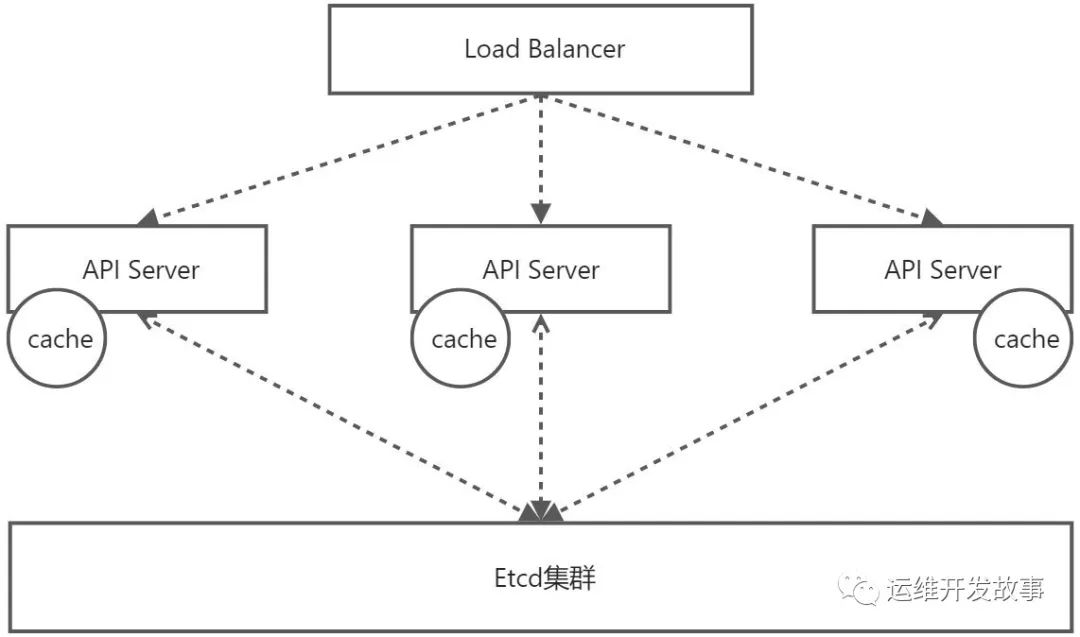
上面的架构是逻辑架构,在实际的生产运用中,为了达到高可用,会对架构做对应的调整,调整对象就是主节点,如下: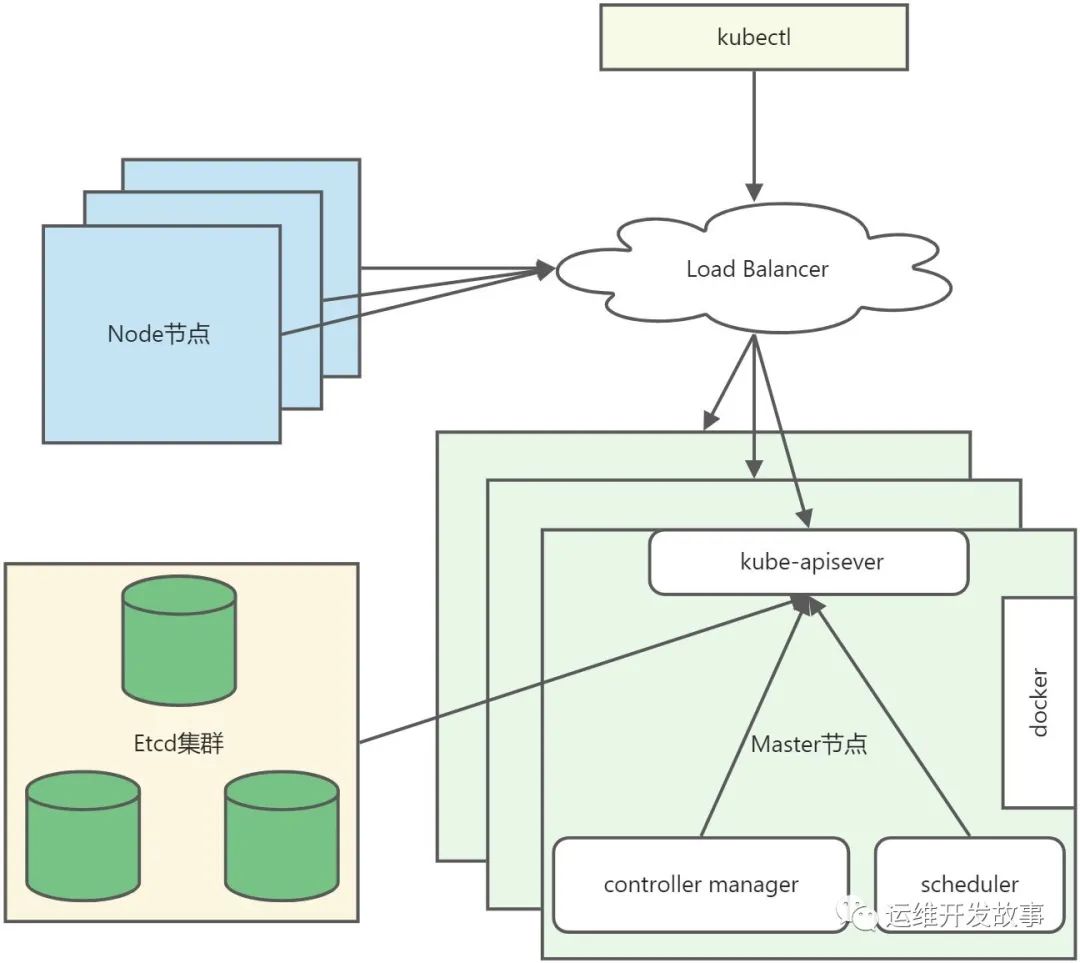
主要做了以下改变:
(1)将Master节点从单节点变成了多节点,在kube-apiserver前增加了load balancer用来负载,其他组件通信都是通过LB进行
(2)将etcd和master节点独立开,避免由于某个master节点故障导致ectd受影响
Kubernetes架构的设计原则是:
只有APIServer可以直接访问Etcd存储,其他服务必须通过Kubernetes API来访问集群的状态 单节点故障原则上不应该影响集群的状态 在没有新请求的情况下,所有组件应该在故障恢复后继续执行上次后收到的请求 所有组件应该在内存中保持所需要的状态,APIServer将状态写入Etcd存储,而其他组件则通过APIServer更新并监听所有的变化,终由Controller Manager去协调 优先使用事件监听而不是轮询
Kubernetes的重要组件
上面介绍了Kubernetes的整体架构以及简单介绍了各个组件的作用,但是它们之间的关系具体如何并没有做过多的介绍,我们现在来看看各个组件以及它们之间是怎么协作的。
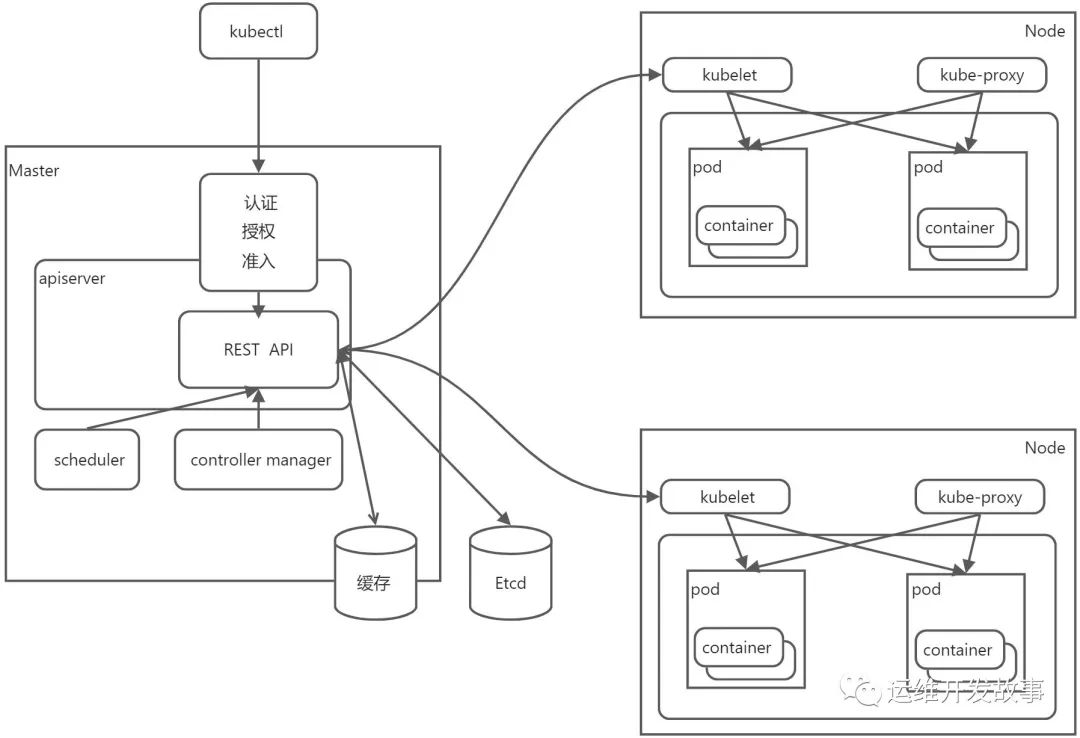
(1)kubectl 客户端首先将CLI命令转化为RESTful的API调用,然后发送到kube-apiserver。
(2)kube-apiserver 在认证、授权、准入验证过后,将任务元信息并存储到etcd,然后kube-scheduler会对任务进行调度,并将调度结果返回给kube-apiserver。
(3)一旦 kube-scheduler 返回一个适合调度的目标节点后,kube-apiserver 就把任务的节点信息存入etcd,并创建任务。
(4)此时目标节点中的 kubelet正监听apiserver,当监听到有新任务需要调度到本节点后,kubelet通过本地runtime创建任务容器,执行作业。
(5)接着kubelet将任务状态等信息返回给apiserver存储到etcd。
(6)kube-proxy也会监听apiserver,如果有网络策略相关的操作,就会在本机上创建对应的iptables或者ipvs规则。
(7)这样我们的任务已经在运行了,此时control-manager发挥作用保证任务一直是我们期望的状态。
其主要组件如下:
Etcd API Server Controller Manager Scheduler Kubelet Kube-proxy
Etcd
Etcd 是兼具一致性和高可用性的键值存储,可用于服务发现、共享配置以及一致性保障,在Kubernetes中,Etcd是作为的存储,保存Kubernetes的所有API对象。
在生产级Kubernetes中etcd通常会以集群的方式存在,安全原因,它只能从 API 服务器访问。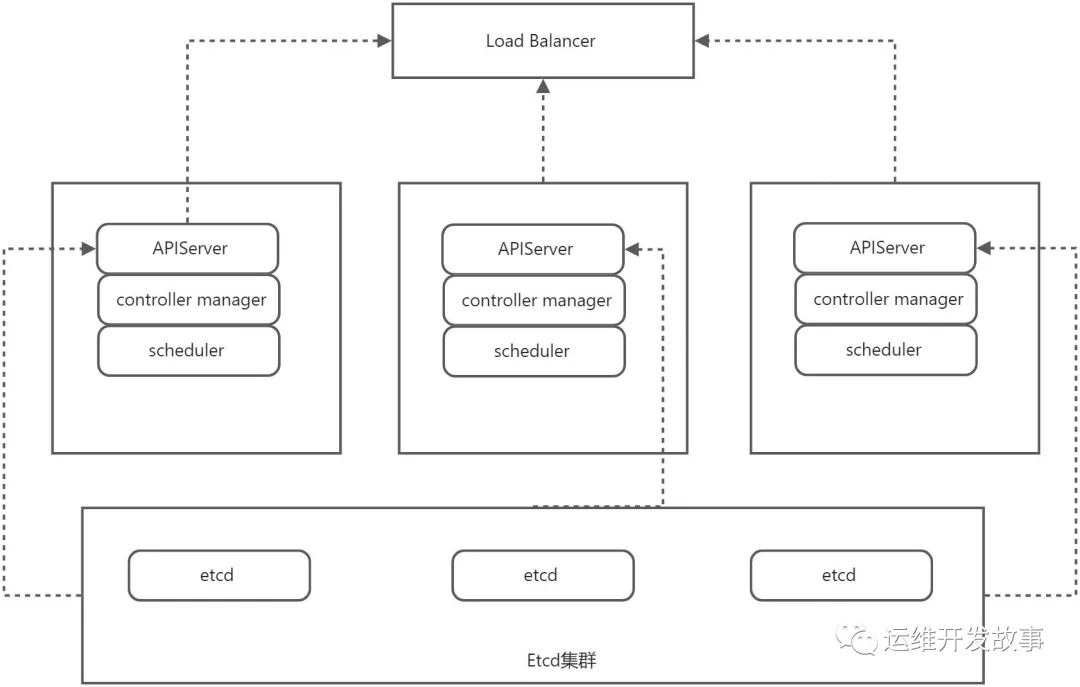
API Server
API Server是Kubernetes重要的核心组件之一,主要提供以下功能:
提供集群管理的REST API接口,包括: 认证 授权 准入 为其他模块提供数据交互和通信的枢纽 API Server提供Etcd的数据缓存,减少集群对Etcd的访问
Controller Manager
Kubernetes在后台运行许多不同的控制器进程,当服务配置发生更改时(例如,替换运行 pod 的镜像,或更改配置 yaml 文件中的参数),控制器会发现更改并开始朝着新的期望状态工作。
从逻辑上讲,每个控制器都是一个单独的进程, 但是为了降低复杂性,它们都被编译到同一个可执行文件,并在一个进程中运行。控制器包括:
节点控制器(Node Controller): 负责在节点出现故障时进行通知和响应 任务控制器(Job controller): 监测代表一次性任务的 Job 对象,然后创建 Pods 来运行这些任务直至完成 端点控制器(Endpoints Controller): 填充端点(Endpoints)对象(即加入 Service 与 Pod) 服务帐户和令牌控制器(Service Account & Token Controllers): 为新的命名空间创建默认帐户和 API 访问令牌
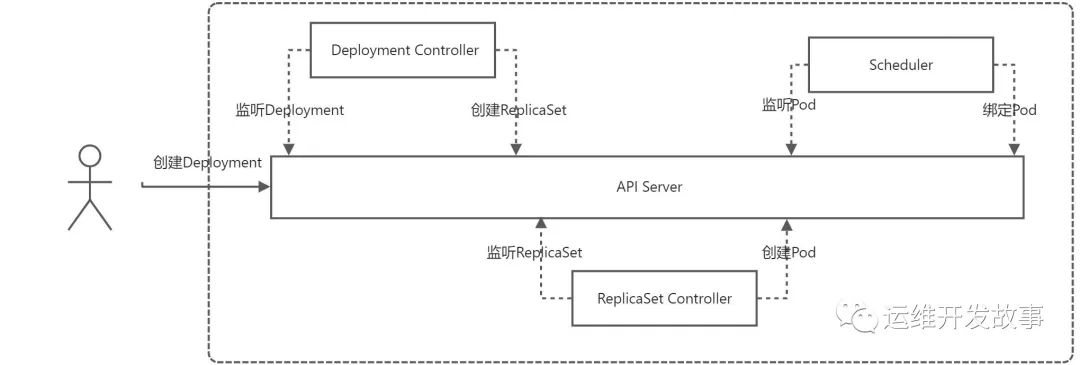
下面就是Deployment Controller和ReplicaSet Controller两个控制器的工作流程。
Scheduler
kube-scheduler 负责监视新创建、未指定运行Node的 Pods,决策出一个让pod运行的节点。例如,如果应用程序需要 1GB 内存和 2 个 CPU 内核,那么该应用程序的 pod 将被安排在至少具有这些资源的节点上。每次需要调度 pod 时,调度程序都会运行。调度程序必须知道可用的总资源以及分配给每个节点上现有工作负载的资源。调度决策考虑的因素包括单个 Pod 和 Pod 集合的资源需求、硬件/软件/策略约束、亲和性和反亲和性规范、数据位置、工作负载间的干扰和后时限。
调度总共分为三个阶段:
Predict:预选阶段,过滤不能满足业务需求的节点 Priority:优选阶段,选择优的节点 Bind:绑定阶段,将优节点和Pod进行绑定,完成调度
Kubelet
Kubelet是每个节点上的核心组件之一,负责管理节点的资源对象。
从不同源获取Pod清单,并按需启停Pod Pod清单可以来自本地文件目录、给定的Http Server、API Server等 Kubelet将Container Runtime、Network、Stroage抽象成CRI、CNI、CSI 负责汇报节点的健康状态以及资源信息 负责Pod的健康检查和状态汇报
Kube-proxy
kube-proxy 是集群中每个节点上运行的网络代理, 实现 Kubernetes 服务(Service) 概念的一部分。用于处理单个主机子网划分并向外部世界公开服务。它跨集群中的各种隔离网络将请求转发到正确的 pod/容器。kube-proxy 维护节点上的网络规则。这些网络规则允许从集群内部或外部的网络会话与 Pod 进行网络通信。如果操作系统提供了数据包过滤层并可用的话,kube-proxy 会通过它来实现网络规则。否则, kube-proxy 仅转发流量本身。
其他组件
上面介绍的这些组件是集群的架子,光有架子还不够,还需要第三方的组件让其更强大:
kube-dns:负责为整个集群提供DNS服务,常用的是CoreDNS Ingress Controller:为集群提供外网访问入口 Metrics-Server:为集群提供监控资源 DashBoard:提供GUI,方便运维 Prometheus:收集并监控集群资源 Grafana:图形化展示监控数据 ELK:收集、存储、查询集群日志
我是 乔克,《运维开发故事》公众号团队中的一员,一线运维农民工,云原生实践者,这里不仅有硬核的技术干货,还有我们对技术的思考和感悟,欢迎关注我们的公众号,期待和你一起成长!
