来自:https://juejin.cn/post/7161964571853815822
基础数据准备
联合索引
sname,s_code,address主键索引
id普通索引
height
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = ;
-- ----------------------------
-- Table structure for student
-- ----------------------------
DROP TABLE IF EXISTS `student`;
CREATE TABLE `student` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`sname` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`s_code` int(100) NULL DEFAULT NULL,
`address` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`height` double NULL DEFAULT NULL,
`classid` int(11) NULL DEFAULT NULL,
`create_time` datetime() NOT NULL ON UPDATE CURRENT_TIMESTAMP(),
PRIMARY KEY (`id`) USING BTREE,
INDEX `普通索引`(`height`) USING BTREE,
INDEX `联合索引`(`sname`, `s_code`, `address`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 5 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of student
-- ----------------------------
INSERT INTO `student` VALUES (1, '学生1', 1, '上海', 170, 1, '2022-11-02 20:44:14');
INSERT INTO `student` VALUES (2, '学生2', 2, '北京', 180, 2, '2022-11-02 20:44:16');
INSERT INTO `student` VALUES (3, '变成派大星', 3, '京东', 185, 3, '2022-11-02 20:44:19');
INSERT INTO `student` VALUES (4, '学生4', 4, '联通', 190, 4, '2022-11-02 20:44:25');
正文

左匹配原则
sname, s_code, address-- 联合索引 sname,s_code,address
1、select create_time from student where sname = "变成派大星" -- 会走索引吗?
2、select create_time from student where s_code = 1 -- 会走索引吗?
3、select create_time from student where address = "上海" -- 会走索引吗?
4、select create_time from student where address = "上海" and s_code = 1 -- 会走索引吗?
5、select create_time from student where address = "上海" and sname = "变成派大星" -- 会走索引吗?
6、select create_time from student where sname = "变成派大星" and address = "上海" -- 会走索引吗?
7、select create_time from student where sname = "变成派大星" and s_code = 1 and address = "上海" -- 会走索引吗?

EXPLAIN select create_time from student where sname = "变成派大星" -- 会走索引吗?

EXPLAIN select create_time from student where address = "上海" and s_code = 1 -- 会走索引吗?

sname, s_code)顺序的索引,是匹配不到(sname, s_code)索引的;sname, s_code的顺序。address是用不到索引的,因为s_code字段是一个范围查询,它之后的字段会停止匹配。


思考
验证
你可以认为联合索引是闯关游戏的设计
例如你这个联合索引是state/city/zipCode
那么state就是关 city是第二关, zipCode就是第三关
你必须匹配了关,才能匹配第二关,匹配了关和第二关,才能匹配第三关
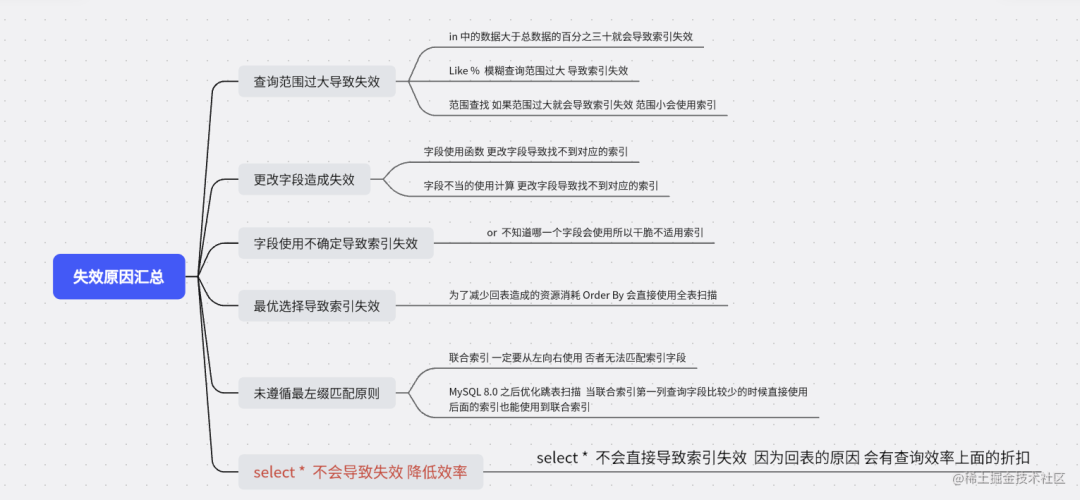
橙色代表字段 A
浅绿色 代表字段B
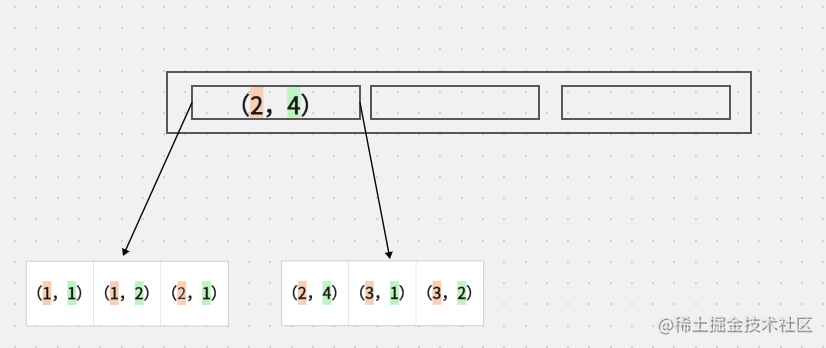
A 是有顺序的 1,1,2,2,3,4
B 是没有顺序的 1,2,1,4,1,2 这个是散列的
如果A是等值的时候 B是有序的 例如 (1,1),(1,2) 这里的B有序的 (2,1),(2,4) B 也是有序的
DROP TABLE IF EXISTS `leftaffix`;
CREATE TABLE `leftaffix` (
`a` int(11) NOT NULL AUTO_INCREMENT,
`b` int(11) NULL DEFAULT NULL,
`c` int(11) NULL DEFAULT NULL,
`d` int(11) NULL DEFAULT NULL,
`e` varchar(11) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`a`) USING BTREE,
INDEX `联合索引`(`b`, `c`, `d`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 8 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of leftaffix
-- ----------------------------
INSERT INTO `leftaffix` VALUES (1, 1, 1, 1, '1');
INSERT INTO `leftaffix` VALUES (2, 2, 2, 2, '2');
INSERT INTO `leftaffix` VALUES (3, 3, 2, 2, '3');
INSERT INTO `leftaffix` VALUES (4, 3, 1, 1, '4');
INSERT INTO `leftaffix` VALUES (5, 2, 3, 5, '5');
INSERT INTO `leftaffix` VALUES (6, 6, 4, 4, '6');
INSERT INTO `leftaffix` VALUES (7, 8, 8, 8, '7');
SET FOREIGN_KEY_CHECKS = 1;
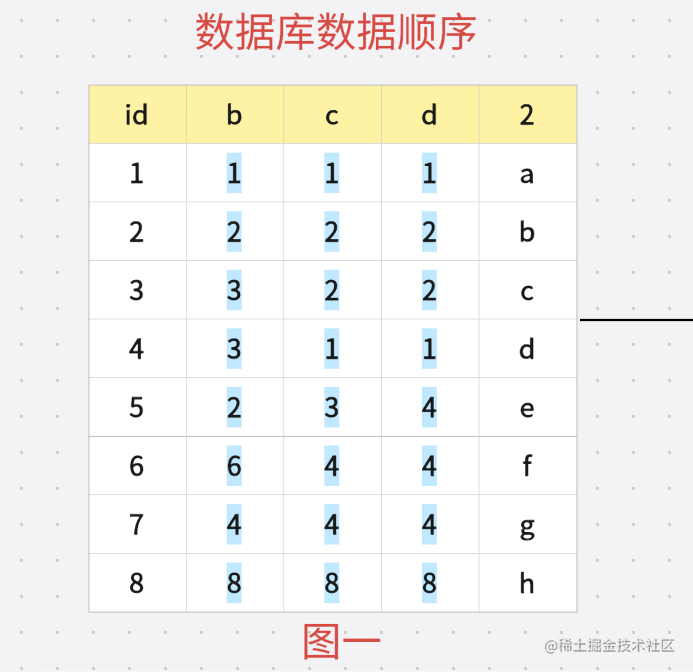
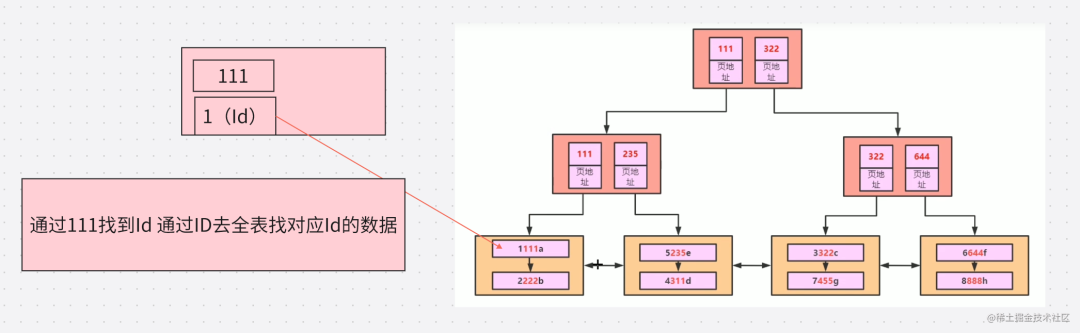
在创建索引树的时候会对数据进行排序 根据左缀原则 会先通过 B 进行排序 也就是 如果出现值相同就 根据 C 排序 如果 C相同就根据D 排序 排好顺序之后就是如下图:

索引的生成就会根据图二的顺序进行生成 我们看一下 生成后的树状数据是什么样子
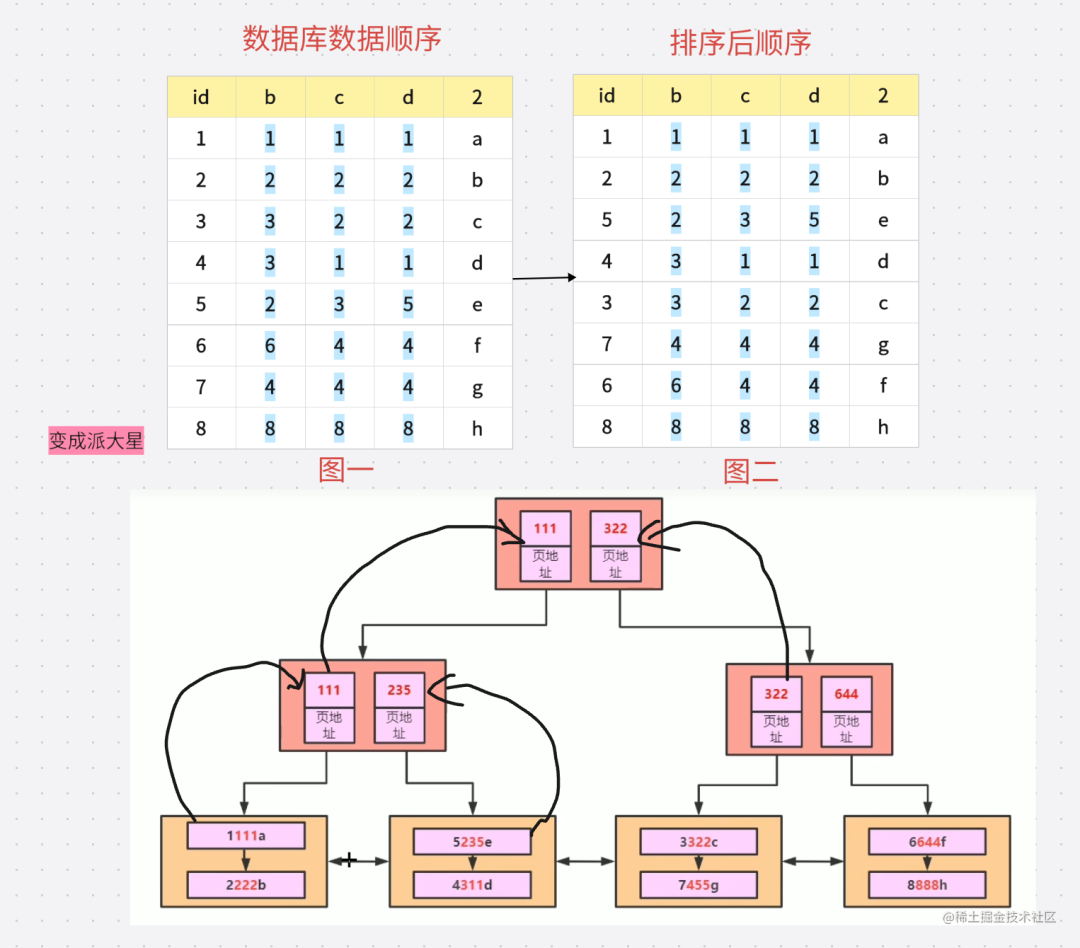
解释一些这个树状图 首先根据图二的排序 我们知道顺序 是 1111a 2222b 所以 在第三层 我们可以看到 1111a 在层 2222b在第二层 因为 111 < 222 所以 111 进入第二层 然后得出层

个字段排序,在个字段的排序基础上,然后在对第二个字段进行排序。所以B=2这种查询条件没有办法利用索引。
补充
MySQL8.0版本开始增加了索引跳跃扫描的功能,当列索引的值较少时,即使where条件没有列索引,查询的时候也可以用到联合索引。小总结
如果 我where 后面的条件是
c = 1 and d = 1为什么不能走索引呢 如果没有b的话 你查询的值相当于*11我们都知道*是所有的意思也就是我能匹配到所有的数据如果 我 where 后面是
b = 1 and d =1为什么会走索引呢?你等于查询的数据是1*1我可以通过前面 1 进行索引匹配 所以就可以走索引左缀匹配原则的重要的就是 个字段
select *
思考
解释
增加查询分析器解析成本。
增减字段容易与 resultMap 配置不一致。
-
无用字段增加网络 消耗,尤其是 text 类型的字段。

SELECT*,获取了不需要的数据,则首先通过辅助索引过滤数据,然后再通过聚集索引获取所有的列,这就多了一次b+树查询,速度必然会慢很多,减少使用select * 就是降低回表带来的损耗。
 上图就是索引失效的情况
上图就是索引失效的情况
小总结
select * 会走索引
范围查找有概率索引失效但是在特定的情况下会生效 范围小就会使用 也可以理解为 返回结果集小就会使用索引
mysql中连接查询的原理是先对驱动表进行查询操作,然后再用从驱动表得到的数据作为条件,逐条的到被驱动表进行查询。
每次驱动表加载一条数据到内存中,然后被驱动表所有的数据都需要往内存中加载一遍进行比较。效率很低,所以mysql中可以指定一个缓冲池的大小,缓冲池大的话可以同时加载多条驱动表的数据进行比较,放的数据条数越多性能io操作就越少,性能也就越好。所以,如果此时使用
select *放一些无用的列,只会白白的占用缓冲空间。浪费本可以提高性能的机会。按照评论区老哥的说法 select * 不是造成索引失效的直接原因 大部分原因是 where 后边条件的问题 但是还是尽量少去使用select * 多少还是会有影响的
使用函数


计算操作


小总结
Like %
%百分号通配符: 表示任何字符出现任意次数(可以是0次).
_下划线通配符: 表示只能匹配单个字符,不能多也不能少,就是一个字符.
-
like操作符: LIKE作用是指示mysql后面的搜索模式是利用通配符而不是直接相等匹配进行比较.
SELECT * FROM products WHERE products.prod_name like '1000';
SELECT* FROM products WHERE products.prod_name like '%Li%';
SELECT * FROM products WHERE products.prod_name like '%Li';
右:虽然走 但是索引级别比较低主要是模糊查询 范围比较大 所以索引级别就比较低
左:这个范围非常大 所以没有使用索引的必要了 这个可能不是很好优化 还好不是一直拼接上面的
小总结
使用Or导致索引失效

优化

in使用不当


order By
 这一个主要是Mysql 自身优化的问题 我们都知道OrderBy 是排序 那就代表我需要对数据进行排序 如果我走索引 索引是排好序的 但是我需要回表 消耗时间 另一种 我直接全表扫描排序 不用回表 也就是
这一个主要是Mysql 自身优化的问题 我们都知道OrderBy 是排序 那就代表我需要对数据进行排序 如果我走索引 索引是排好序的 但是我需要回表 消耗时间 另一种 我直接全表扫描排序 不用回表 也就是走索引 + 回表
不走索引 直接全表扫描
子查询会走索引吗
答案是会 但是使用不好就不会
大总结