MGR是MySQL官方推出的领先的服务高可用和数据高可靠方案,网易从2017年下半年开始对MGR进行了全面的性能和稳定性测试,发现并解决了数个问题,同时对MGR核心功能进行了优化增强,目前基于MGR的网易RDS金融版服务已经上线,为网易电商业务提供了跨机房的高可用方案。本次分享将为大家介绍网易对MGR的优化和增强,以及MGR在网易电商业务的使用和调优实践
本文是在由IMG(Inside MySQL Group)社区主办的第三届MySQL技术嘉年华上所做的“网易MGR使用和优化实践”PPT讲稿。

大家好上午好,今天主要跟大家聊聊MySQL Group Replication,也就是MGR在网易杭研这边的使用和优化情况。杭研这边使用MGR的场景主要有这么几个,一种是用在业务系统上,一般是电商业务。另一种就是作为其他高可用或跨机房系统的元数据库,这个很多业务场景都需要。

这次分享的内容包括本页所述的3个部分。先是分析下MGR技术实现,简单介绍MGR下的事务执行流程,重点分析事务排序和事务认证,这也是为第二部分做铺垫;第二部分是本次分享的重点,将会分享我们在MGR使用时发现的一些不足以及我们的优化思路和效果;后简单说下网易杭研MGR的使用方案。
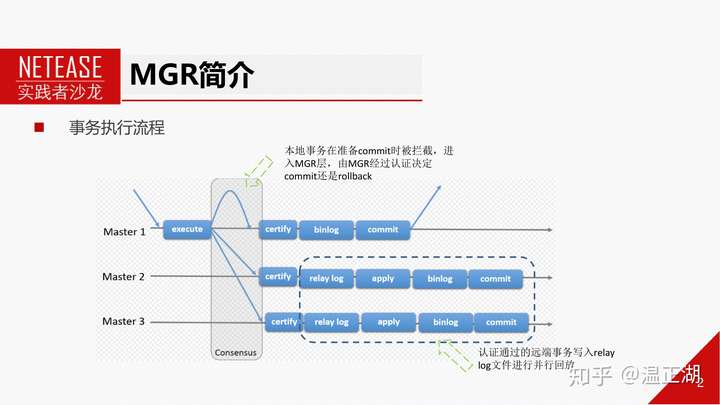
这个图相信了解过MGR的同学都比较熟悉。应该说比较直观得显示了MGR与普通的MySQL复制模式的区别。主要是MGR模式下,事务完成引擎层prepare,写Binlog之前会被MySQL的预埋钩子HOOK before_commit()拦截,进入到MGR层,将事务封装成消息通过Paxos一致性协议(consensus)进行全局排序后发送给MGR各个节点,在各节点上独自进行认证(certifiy)。
认证通过后本地节点写Binlog完成提交。其他节点写relay-log,由注册的复制通道group_replication_applier channel完成事务并行回放。

上页中提到MGR模式下有个certify阶段,就是事务认证或者叫冲突检测的过程。这是因为MGR支持多主模式(multi-master),意味着允许各个节点都执行事务并在本地提交,这就存在潜在的问题,个问题是不同节点可能在同一时刻更新相同的记录,第二个问题是交叉更新,比如节点A先更新了记录1再更新记录2,节点B先更新记录2在更新记录1,由于非本地事务是先写到relay-log里面,所以可能出现两个事务分别更新第二条记录时,条记录的更新所对应的relay-log还没有回放,也就是说读取了第二条记录的旧版本进行了更新操作。
这显然是跟事务的ACID有冲突的。必须解决掉。那么MGR就是通过certify阶段解决。其实不仅仅是多主模式,在单主模式的新主切换过程中,也需要进行事务认证。
进行事务认证的核心是右图所示的冲突检测数据库。其保存了记录的当前版本信息(gtid_set字段),即后一次修改该记录的事务提交后的gtid_executed。通过pk hash字段来标识某条记录。冲突检测数据库的sequence_number字段并不用于事务认证,而是规定认证通过后的并行回放行为。
每个事务进行认证的时候都会携带执行该事务时节点的gtid_executed,也就是事务的版本snapshot_version,以及事务所修改的记录信息writeset。通过这两部分信息跟冲突检测数据库里的信息进行比对,就能确定该事务应该提交还是回滚。
如果一个事务在各个节点都已经执行或回放了,那么该事务的writeset信息就不需要继续缓存在冲突检测数据库中。MGR会对其进行周期性清理。先广播各自节点的gtid_executed信息,然后收集其他节点的gtid_executed信息取交集stable_gtid_set,再基于这个交集来清理无用的信息。

事务在MGR中进行认证前,会先进行全局排序,就是前述的consensus。在这个阶段就需要把事务认证所需的所有信息都收集起来,封装好后通过Paxos协议进行广播。主要有3个部分的内容,部分是Transaction_context_log_event,它携带了事务认证所需信息,包括是否为本地事务,事务的快照版本,执行线程是否为worker线程,事务的gtid是否已确定(MGR作为其他MySQL实例的slave)、事务writeset等等。需要注意的是该log_event仅用于认证,不会写入binlog文件中。接下来2个部分是我们比较熟悉的部分,在认证通过后会写入Binlog文件中,首先是gtid_log_event,规定了事务的gtid,以及在回放时的组提交行为。接着就是真正的事务内容。
在后续的认证阶段,这三部分会被一一处理。

封装好后就会发给Paxos。为了支持各节点可写的多写模式,MGR底层采用了Paxos的变种mencius(也就是孟子,当然真正实现有点差别),每个Paxos节点或者说MySQL节点都是公平的,基于round robin的方式分配到对应的消息轮次。比如节点0分别占据0,3,6。。。槽位,节点1占据1,4,7。。。槽位,节点2占据2,5,8。。等槽位。
这样的话,各节点上执行的事务过了Paxos后就全局有序了。举个例子。比如MGR有3个节点,同一时间分别执行了T1,T2,T3这3个事务,在Mencius中,T2所在MySQL对应节点0,那么就占了槽位0,T1的MySQL对应节点1,占据槽位1。依次。终排定了T1,T2和T3的全局顺序。
但如果3个节点的事务提交频率是不一样的,那么会出现什么情况呢? 那些没有事务提交或提交较少的节点对应的消息轮次/槽位会被noop/null所取代。表示该轮次没有需要达成majority的数据,填空即可。但怎么知道对应消息轮次为空呢,这个实现起来比较麻烦。其他节点会尝试通过READ操作来读取,轮次所属的节点发现本轮次为空,那么发送noop,但如果是因为事务消息过大,导致达成majority很慢,其他节点多次通过READ操作无法获取到,又或者是由于网络延迟较高/网络分区,导致多次READ无法成功,那么其他节点会尝试广播prepare noop来协商该轮次为空值。这是一个潜在的问题。
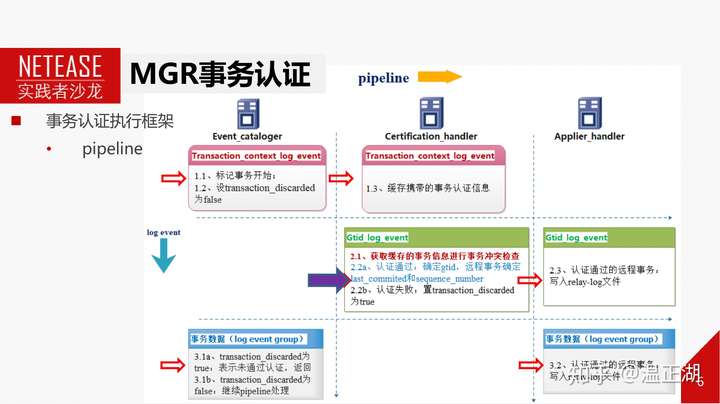
这页的图是事务认证的实现方案。基于pipeline机制,一共有3个pipeline,分别是event_cataloger,certification_handler,applier_handler。事务消息中的3部分log event依次进入pipeline。其中核心的是certification_handler处理gtid_log_event这个环节,决定了事务是否认证通过,以及通过后如果分配gtid,如何确定非本地节点事务的并行回放行为等。下面展开来说下这一步如何进行认证。

假设T2事务的快照版本是1-100,更新的记录是1,查看冲突检测数据库中1对应的版本是1-50,也就是说T2在执行的时候,节点已经执行或回放了之前所有对记录1的修改操作。因此T2得已认证通过。认证通过后需要为T2分别gtid,这里我们先确定分配的是201,他会被更新到冲突检测数据库1的gtid_set上。那么201是怎么确定的呢。需要看下图。
MGR会为每个节点预留一段连续的gtid区间,Available gtid_set表示给当前各个节点预留的可用gtid。比如当前为Server2预留的是201到300,由于T2属于Server2,所以分配目前可用的小gtid,也就是201。这样就保证了多写模式下,给不同节点事务分配的gtid是不一样的。

确定了gtid后,对于非本地事务,需要写到relay-log后回放。那么在写入relay-log文件前,需要确定并行回放行为,即last_committed和sequence_number。
再次以T2为例,首先说sequence_number,这是并行复制的逻辑时钟,根据事务提交先后次序递增。待分配的sequence_number由全局变量parallel_applier_sequence_number保存,那么T2的sequence_number即为387。parallel_applier_sequence_number递增为388。
接下来确定last_committed,我们在前面在介绍过,并行回放时的组提交行为依赖于冲突检测数据库,每条记录除了保存了对应的事务版本外,还保持了后一个事务的sequence_number。这里是120,那么T2这个事务依赖于120这个事务,必须等待120这个事务回放完之后才能回放,也就是说T2的last_committed初始化为120。后,将记录1对应的sequence_number更新为387。
这样,MGR在事务处理过程中需做的事情基本上处理完了。Relay-log中的事务交由worker线程回放即可。

接下来分享下MGR在考拉业务场景上使用时遇到的问题,由于时间有限,只重点说明影响大的2个案例,分别是事务认证模块、Paxos模块的不足和优化。还有很多问题的定位和优化就只能简单列举下。
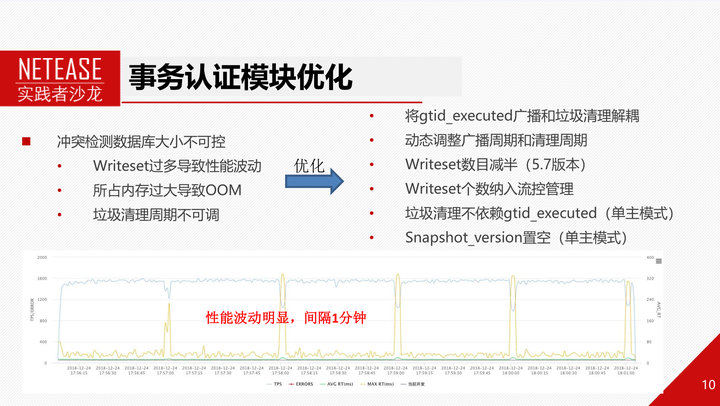
我们前面提到,MGR会每隔60s广播本节点的gtid_executed信息,各节点取交集后清理冲突检测数据库信息。但在网易电商场景下,这样的机制会有明显的性能波动,如下图所示,非常规律的每分钟一次性能波动,延迟升高,tps降低。我们分析发现,这个跟冲突检测数据库清理有关系。因为上面累计了太多的writeset,而执行清理的时候需要加锁遍历整个冲突检测数据库,这就跟事务的认证流程的加锁起了冲突,导致事务性能下降,延迟提升。另外,在某些较极端的情况下,比如流控参数设置较大,或每个事务writeset较多,或gtid_set较大时。writeset清理不及时也容易导致冲突检测数据库占据过多内存空间,导致mysqld OOM。
基于此,我们做了些优化。比如将gtid_executed广播周期变为动态可调的参数,默认设置为20s;将事务产生的writeset个数减半;将writeset个数纳入MGR流控模块管理。这样可以有效降低冲突检测数据库中的writeset个数。
但在节点间复制延迟较大的情况下,冲突检测数据库仍可能比较大。针对这个,我们在单主模式下做了进一步优化,就是writeset清理不依赖于gtid_executed交集。而是采用writeset个数达到阈值直接清掉。因为单主模式不会有事务冲突,冲突检测数据库并不是发挥事务认证作用,而仅仅用于决定事务的并行回放行为。这个优化还报错将gtid_set字段置空,来进一步减少内存消耗。

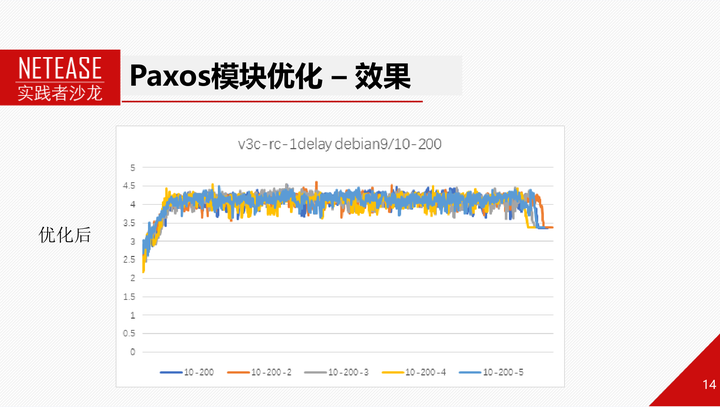
右图是优化前后的性能对比。可以发现,性能波动大大改善。平均性能得到提升。而且内存也得到了有效控制。
除了事务认证模块,也对MGR底层的Paxos模块进行了优化改进。这主要是为了解决大量数据导入场景下的问题,包括Primary节点OOM,或者有个Secondary节点由于无法获取paxos消息导致mysqld自动退出问题。
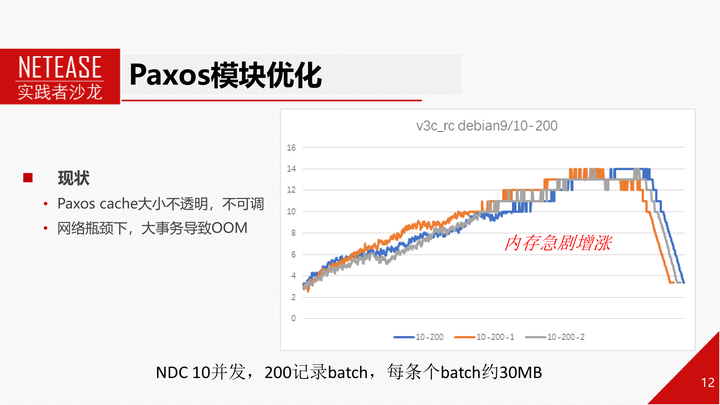
如右图所示,使用NDC往MGR导入数据,设置为10个并发,每个事务为200条记录组成的batch,事务大小在30MB左右。导入过程中,内存急剧增涨。
我们分析发现原因一是paxos cache过大,占据太多内存;二是paxos消息发送和接受环节未考虑高网络延迟情况。

这个2个方面原因展开来说:
首先是paxos cache,目前社区版的cache大小阈值1G,且不可调(8.0新版本已经可调),但其实无法将cache大小严格控制在1G左右。主要是因为达到大小阈值后,cache对象是否能被清理需要看其他节点是否还需要该cache对象,另外达到cache大小阈值后,新的cache对象还会从空闲队列分配而不是通过LRU替换当前cache对象。
第二个原因是paxos协议实现导致的内存增涨,主要是由于大事务在网络中低效率传输导致网络拥塞。由于网络拥塞,未参与majority的节点尝试获取消息时无法及时获取对应消息轮次节点返回的消息,就会不断进行重试,但其实此时对应轮次节点正在回复消息数据,只是因为事务较大,网络较差,导致传输速度太慢。如果不断重试,会不断恶化这个情况。节点在回复消息数据时会拷贝一份消息数据。也就是30MB,那么如果每个消息都重复多次,显然会迅速消耗大量内存。
这是Paxos层优化后的内存使用情况,可以看到,已经变得非常平稳。而且其实性能并没有什么损耗。
除了上面这些大点外,我们也从运维角度进行了优化,比如将8.0版本的一些特性迁移到5.7上。还有就是对故障恢复和选主等环节进行优化,比如选择gtid_executed新的节点作为Primary节点。节点加入集群时优先从其他secondary节点获取数据。等等。时间关系,不展开介绍。
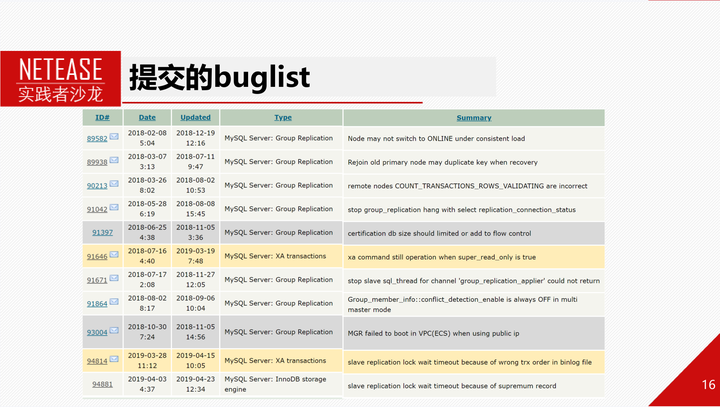
这是我们上报的MGR模块,或者跟MGR相关的一些官方bug。有MGR选主和故障恢复方向的,也有跟复制或者XA事务相关的。其中有些非常严重的问题,比如数据不一致问题,复制中断问题,只读开关开启情况下还能提交事务等等。这些问题的发现和修复,为我们业务能够使用MGR打下了基础。目前上面的绝大多数问题MySQL官方都已经在新版本上修复了。

第三部分简单说下MGR使用方案。包括MGR如何与网易云RDS服务配合实现金融级高可用实例,如何实现考拉的同城跨机房,如何与DDB配合来减低硬件成本等。
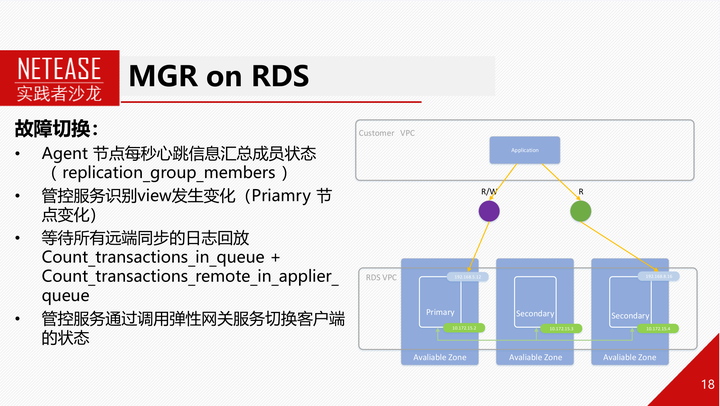
首先是MGR在网易云RDS上的使用。网易云RDS支撑了网易杭研95%以上的业务,是网易内部使用MySQL的主要平台。相比自建MySQL,网易云RDS有非常多的优势。目前网易云RDS已经基于MGR推出3节点的金融版实例。相比主从复制架构的RDS高可用实例,基于MGR的RDS金融版实例,在数据可用性和可靠性上又有了进一步提升。引入MGR后,RDS Agent和管控的逻辑需要针对性得进行适配,这里主要介绍MGR在故障时的路由切换和故障恢复。
MGR会自己选主,但无法将MySQL访问路由从旧主切换到新主,这个是需要RDS做的。RDS可以通过监测主节点心跳来发现节点宕机等行为。然后通过各个节点上报的心跳信息来感知view视图变更和新选出来的主是哪个节点。等新主的认证队列和回放队列均为空,relay-log回放完之后,将网络路由切换到新主上。
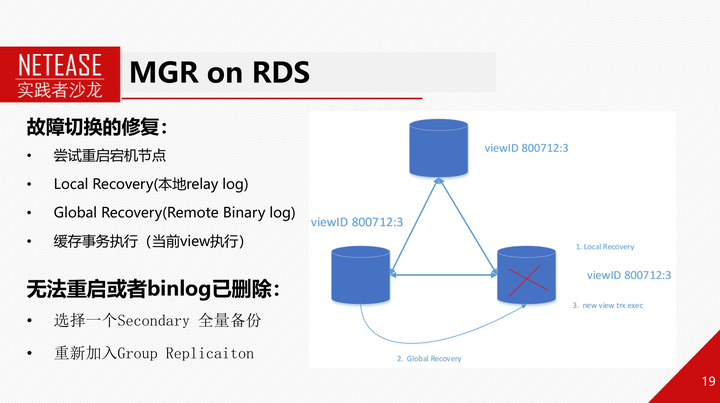
对于故障的节点,会尝试重启,如果无法重启,那么RDS需要用xtrabackup基于MGR其他节点做个全量物理备份,重新加入MGR。如果重启成功,重新加入MGR后节点会首先回放本地applier通道上的relay-log,然后连上其他节点使用recovery通道获取binlog并回放,如果此时其他节点binlog已经被purge,那么也需要进行全量重建。

接下来介绍下MGR在考拉跨机房上的使用,目前的部署模式是同城跨机房基于MGR,跨城的多机房使用异步复制进行。
为了提高同城2机房模式下数据的可用性和可靠性。我们将Primary节点放在1个机房,2个Secondary节点放在另一个机房。在2机房架构下,只有将Primary和Secondary隔开才能确保任意一个机房挂掉,数据不会丢失。因为如果Primary跟任意一个Secondary在一个机房的话,就可能在机房内部对一个事务达成majority,另一个机房的secondary可能还未收到数据。这种情况下,Primary所在机房宕机时就可能导致数据丢失。
还有,在跨机房场景下,不可能通过切换ip来调整业务的路由。所以设计了基于ETCD的DNS切换方案,一个机房故障的情况下,另一个机房还能跟第三个机房实现majority,因此还能够修改DNS地址,实现业务访问的跨机房高可用。
目前某电商业务的测试环境均已经升级为基于MGR的RDS金融版实例。线上也有小规模使用,目前正在逐步将线上RDS高可用实例替换为基于MGR的RDS金融版实例。
