Closing Performance Gap Between Volatile and Persistent Memory

原题目:Closing the Performance Gap Between Volatile and Persistent Key-Value Stores Using Cross Referencing Logs
文章概况:
这篇文章主要研究基于 Persistent Memory(PM,持久内存)的高性能 key-value 存储。

1. Motivation
传统的 key-value 存储方案主要分为两种,(1)用作 cache,存放在 DRAM(内存) 中,以 memcached 和 redis 为代表;(2)用作持久化存储,以 LSM-tree 方案为代表,大家所熟知的有 Leveldb 和 Rocksdb 。随着当前 Persistent Memory (PM) (其实也就是 NVM 设备,例如 Intel/Micron’s 3D XPoint)技术的发展,PM 设备已经拥有仅次于 DRAM 的 latency 和吞吐,且具有持久化存储和 byteaddressable 的能力。而传统 key-value 存储方案并不完全适用于 PM 设备:传统方案(1)并不能直接迁移到 PM 设备上;方案(2)由于读写放大的因素,其实不能充分的发挥 PM 设备的性能,因为 PM 设备的顺序读写和随机读写性能相差并不大。
这篇论文的作者主要动机就是设计基于 PM 设备的高性能 key-value 存储,使其尽可能的接近 DRAM 的性能,也就是 closing the gap between DRAM with PM for key-value store。因为相比 DRAM,PM 设备具有持久化的能力,而且 latency 和 throughput 和 DRAM 非常接近, 如果能够将 PM 设备上的 key-value 存储优化到 latency 和 throughput 足够接近 DRAM,那将是一件很美妙的事情。
但是 DRAM 和 PM 之间存在一定的 gap, 如下图,给出了几组 key-value 存储在DRAM 和 PM 设备的表现:
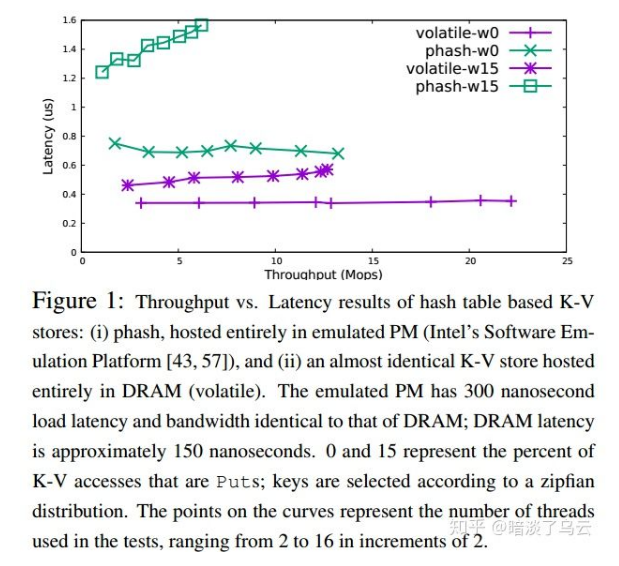
从上图我们不难发现:
- 随着 write 的比例增多,DRAM 和 PM 的 latency 差距越来越大,从 write 比例 0% 到15%,latency 的 gap 也从 2X 增加到了 4X;
- DRAM 在多线程的情况 latency 表现平稳,而 PM 设备随着线程的增加 latency 显著上升;
- 由上图的分析不难得知,key-vale 存储在 DRAM 和 PM 上的 gap 就是 write 性能较差,而且扩展性不好,也就是在多线程的表现下,性能下降很快,不能充分利用现在多核 CPU 的优势。
2. Innovation
作者给出了一个名为 Bullet 的 key-value 方案,使用 DRAM 作为 Cache,PM 负责持久化 key-value 和 log 数据,其核心的贡献在于使用多个 log 来衔接 DRAM 和 PM,从而实现了 PM 上的 key-value store 在多线程环境下具有良好的 Scalability,而且为了解决多 log 的 Consistency Apply 的问题(就是 log apply 到 PM 上的 key-value 数据中),创新的使用了一种 cross-referencing logs (CRLs) 技术。
3. Implementation
3.1. Bullet architecture
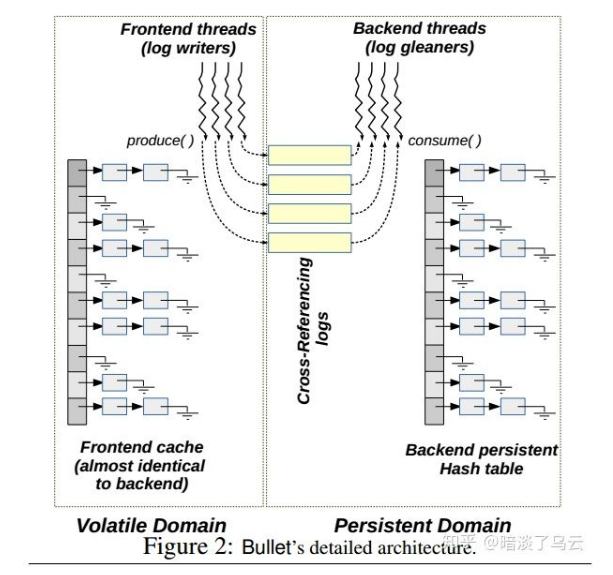
首先看看 Bullet 的架构,如上图,Bullet 分为 front-end 和 back-end:
- front-end 将 kv 写入 DRAM hash table 中,为了保证数据落盘,还要写 log,log 是在 PM 设备上,front-end 有多个 log writers 线程(DRAM 中的 hash table 相当于就是一个 read/write Cache,因为毕竟 DRAM 相比于 PM 还是在性能上有优势的)
- back-end 在 PM 上:有一个 hash table 负责持久化 key-value 数据;多个 log 文件。后端也会有多个 log gleaners 线程,负责将 Op log entry applied 到 PM 上的 hash table 中
3.2. CRLs
相比传统是只有一个 log,多个 log 会减少竞争,但同时也会带来一致性问题,因为需要将多个 log 按顺序 applied 到 back-end 的 hash-table 中才行,论文给出了一个巧妙的解决方案,它就是 cross-referencing logs (CRLs) ,其大致的思路就是在每个 Op log entry 中会记录其前一个有依赖关系的 log entry 的指针,所谓的有依赖关系,就是操作同一个 key 的 Op log entry 就是有依赖关系,它们 apply 的时候必须按照严格的写入顺序 apply。

下面来详细的分析 CRLs 核心结构:
- Op log entry :主要关心几个字段就可以了
- op code : 什么 op 类型,update/delete
- applied : 是否被 applied,也就是是否已经后拷贝到 back-end PM 上的 hash table 中了
- pre : 前一个依赖 op log entry 的指针(如果是个 update/delete,那么其 pre 为 NULL)
- lentry :
就是 Figure 3: 的下面部分,它是一个持久化的 K-V Pairs,每个 key-value 数据还会有一个 lentry Pair 对应,其记录了这个 key-value pair 新的 Op log entry 的位置,这样一个新来的 Op log entry,无论是 append 到哪个 log 上,只需要读取这个 lentry,然后存放在自己的 pre 字段中,然后更新自己的位置为 lentry 即可。
3.3. Appending op log entry
下面来看看,CRLs 是如何 Write Op log entry 到 log 文件中的,下面给出 append 一个 Op log entry 的步骤:
- 根据 key-value pair 加锁
- 读取这个 key-value pair 的 lentry,并放在当前 Op log entry 的 pre 字段中
- 持久化这个 Op log entry
- 更新当前 Op log entry 的位置到 lentry 中(注意这步是 cas 操作)
- unlock
从上面的步骤可以看出,相比单个 log 文件,多个 log 文件并发性将会极大提升。下面给一个图例(三个 log 文件,front-end 的 log writer append Op log entry 到 log 文件中,back-end 的 log gleaners 将 Op log entry applied 到 back-end 的 hash table 中):
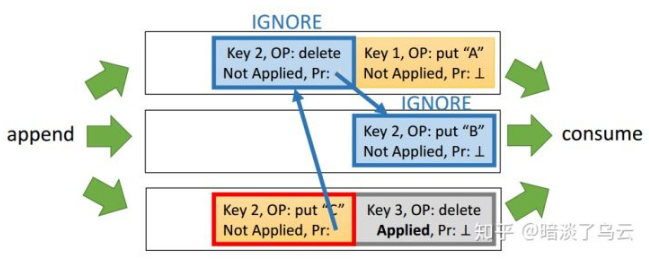
3.4. Applying Log Records
接着来看,如何 applied 一条 Op log entry 到 PM 的 key-value (hash table)数据中
- 从 log 的 head 取一条 Op log entry (tail 用于 append)
- 然后在 lentry 中取出整个具有依赖关系的 Op log entry list
- 按照相反的顺序 applied,并跟新 Op log entry 的 applied 字段(因为是 pre 指向的更早的 Op log entry,applied 的时候必须按照 Op 的顺序)
- 更新此 key-value pair 的 lentry
3.5. Optimization
3.5.1. Dynamic Worker Threads
可以根据 read/write 的比例,动态的调整 front-end log writers 线程 和 log gleaners 线程的数量,如下图是 write-heavy workload 场景,因为在 write heavy 的场景下,由于 log 空间有限,需要多一些的 gleaner 线程尽快将 log 中的 Op log entry apply 到 PM 中 key-value hash table 中,避免阻塞 write。

3.5.2. Overwriting
在 apply Op log entry 的时候,因为是将整个有 key-value pair 的 op log entry list 都拉出来了,实际上只有后一条被 applied 就可以了,前面的都可以直接忽略,如下图,key 2 的前面两个 Op log entry 就被忽略了。
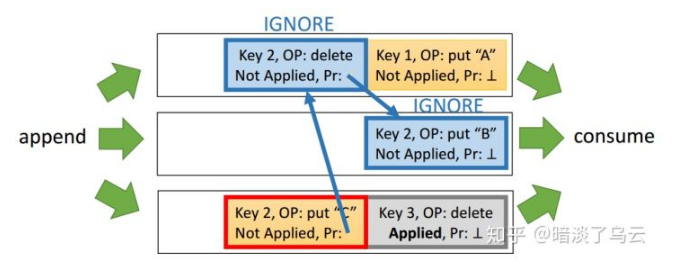
不过这里有个顺序需要注意一下,保证即使出现故障也能够一致:
- applied key 2 的后一条 Op log entry
- 然后再按照 lentry list 的相反顺序修改 Op log entry 的 applied 字段
4. Summary
CRTLs 思路比较有意思,有些乱序 applied 的意思,感觉和 PolarFS [2] ParallelRaft 中乱序提交和乱序 apply 有着异曲同工之妙。
Notes
限于作者水平,难免在理解和描述上有疏漏或者错误的地方,欢迎共同交流;部分参考已经在正文和参考文献列表中注明,但仍有可能有疏漏的地方,有任何侵权或者不明确的地方,欢迎指出,必定及时更正或者删除;文章供于学习交流,转载注明出处
参考文献
[1]. Closing the Performance Gap Between Volatile and Persistent Key-Value Stores Using Cross-Referencing Logs. https://www.usenix.org/conference/atc18/presentation/huang
[2]. PolarFS: An Ultra-low Latency and Failure Resilient Distributed File System for Shared Storage Cloud Database. http://www.vldb.org/pvldb/vol11/p1
