0. 介绍
当前,以LevelDB、RocksDB为代表的LSM-tree k-v存储引擎广泛应用,所以研究和优化的非常多,无论是学术界和工业界,之前也有介绍多个相关的工作。今天也因为"利奇马"到访杭州,所以难得清闲在家里休息,撇了一眼ATC 2019,挑了今年的Best Paper SILK: Preventing Latency Spikes in Log-Structured Merge Key-Value Stores[1]给大家分享下,和以往通过减少Compaction减少write放大来提升write吞吐性能不同,这篇文章主要集中优化write长尾延迟(Latency Spikes、99th percentile latencies ),文章立意明确、论述思路清晰充分,单论写作,也是一篇不错文章,值得一读。
1. 长尾
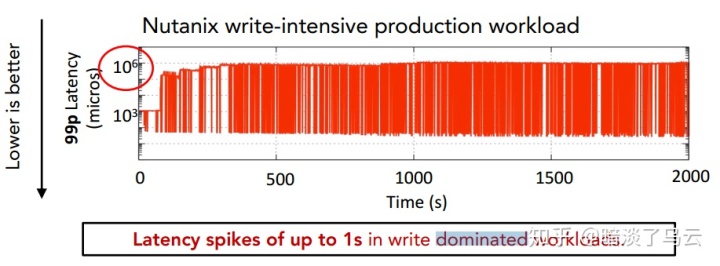
首先来看所谓的write延迟长尾,如下图:
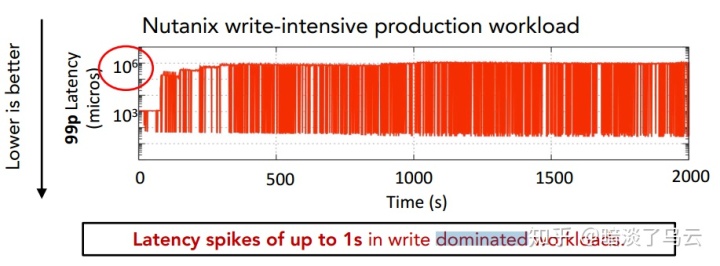
作者以write为主的测试场景进行分析发现,在持续的write密集型生产压力下,LSM-tree kv存储系统的长尾延迟明显,如上图,不难看出,99%分位的延迟很快到达了秒级。实际上长尾延迟可能在很多系统中都是一个难题。
2. 成因
要解决长尾延迟,首要就是弄明白,造成长尾延迟的原因是什么 ?下面将以LevelDB为例来描述这个问题。在介绍之前,首先简单回顾下LevelDB数据写入的基本流程:
- 首先append write WAL log(保证写入的原子性)
- write写内存中mutable memtable(skiplist)
- 如果mutable memtable到达一定的大小,转换成immutable memtable
- 执行Minor Compaction(Flushing)将immutable memtable转换成 level 0 sstable
- 后台然后根据一定的策略对不同level的sstable进行compaction,leveldb的compaction可以参考我之前文章[2]
上面大致的write流程里面其实隐藏了一些write limit的细节,这也是造成长尾的关键原因,如下图:
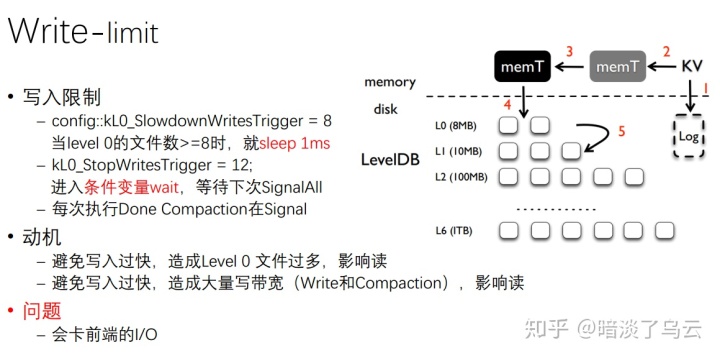
如上图所述,leveldb在level 0的sstable文件数超过一定的阈值的时候,就会适当的停止上层的I/O。尽管总体上RocksDB的实现可能有一些不同,也作了一些优化,但是都是会存在由于level 0文件数过多而造成write limit的情况,这也是造成write长尾延迟的罪魁祸首。
为了方便后面的描述,先对各种操作进行分类,其中用户的write操作定义为:Client Operation,LSM-tree kv存储中的(1)Flushing;(2)L0->L1 compaction;(3)Higher level compactions统称为Internal opertations(如下图)。


总结下来write长尾延迟主要原因就是下面2个:
- level 0的sst数据过多,flushing停止,那么会卡client,从而造成write出现长尾延迟,这也是核心的原因
- 底层Compaction过多,挤占了flushing和WAL log的性能
3. 方案
针对write长尾延迟的原因,作者提出了一种I/O Scheduler的策略:
(1)优先flushing和lower levels的compaction,低level的compaction优先于高level的compaction,这样保证flushing能尽快的写入level 0,level 0尽快compaction level 1,(a)尽量避免因为memtable到达上限卡client I/O,(b)尽量避免因为level 0的sstable文件数到达上限卡client I/O。实际实现的时候会有一个线程池专门用于Flushing;另外一个线程池用于其他的Compaction
(2)Preempting Compactions:支持抢占式Compaction,也就是高优先级的compaction可以抢占低优先级的compaction,也就是说另外一个用于L0~LN之间的compaction的线程池,优先级高的low level compaction可以抢占high level的compaction,这样L0->L1在这个线程池,高优先级的compaction就能够在必要的时候抢占执行,保证尽量不会出现level 0的sstable数量超过阈值
(3)在low load的时候,给Internal Operation(compaction)分配更多的bandwidth,相反,在high load的时候,给Client operation分配更多的带宽,这样可以保证Compaction在适当的时候也能得到更多的处理,减少read放大和空间放大,这个调度策略也是基于通常的client operation load是波动这事实来设计的,如下图,就是一个真实环境的workload变化规律:
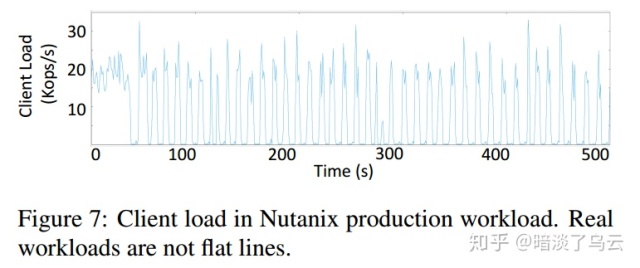
这其实也是针对write长尾延迟原因2的优化。
4. 总结
更多的细节这里没有详细描述,感兴趣的读者可以详细阅读这篇论文和论文里面提到的参考文献,并结合LevelDB和RockDB I/O流程和 Compaction机制,相应大家对LSM-tree的一些关键设计和问题都会有一个更清晰的认识。
Notes
限于作者水平,难免在理解和描述上有疏漏或者错误的地方,欢迎共同交流;部分参考已经在正文和参考文献列表中注明,但仍有可能有疏漏的地方,有任何侵权或者不明确的地方,欢迎指出,必定及时更正或者删除;文章供于学习交流,转载注明出处
参考文献
[1]. SILK: Preventing Latency Spikes in Log-Structured Merge Key-Value Stores. ATC 2019. https://www.usenix.org/conference/atc19/presentation/balmau
[2]. LevelDB Compaction. https://zhuanlan.zhihu.com/p/46718964
