推荐系统是根据用户的行为、兴趣等特征,将用户感兴趣的信息、产品等推荐给用户的系统,它的出现主要是为了解决信息过载和用户无明确需求的问题,根据划分标准的不同,又分很多种类别:
- 根据目标用户的不同,可划分为基于大众行为的推荐引擎和个性化推荐引擎
- 根据数据之间的相关性,可划分为基于人口统计学的推荐和基于内容的推荐
......
通常,我们在讨论推荐系统时主要是针对个性化推荐系统,因为它才是更加智能的信息发现过程。在个性化推荐系统中,协同过滤算法是目前应用成功也是普遍的算法,主要包括两大类,基于用户的协同过滤算法和基于物品的协同过滤算法。
此外,在实际的推荐系统中,往往会针对不同的场景使用不同的策略以及多策略组合,从而达到好的推荐效果。
本篇文章主要通过应用Spark KMeans、ALS以及基于内容的推荐算法来进行推荐系统的构建,具体涉及到的数据、表和代码比较多,后续会在github上给出详细说明。
首先看一下推荐系统的概况图:
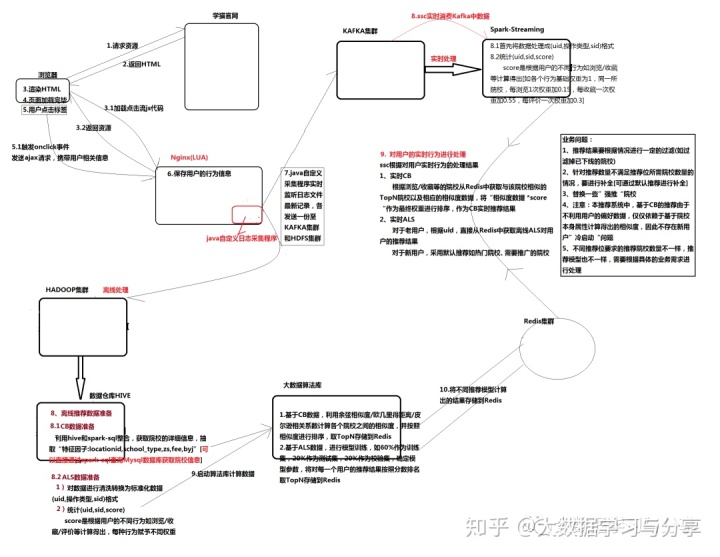
下面主要针对推荐算法的应用和推荐过程做详细阐述。
1. 基于Spark KMeans实现对院校聚类
1.1 数据准备
通过院校信息的结构化数据school.txt和school_loca.txt,将两个结构化文件加载到hive表中。
(1)school.txt数据样例
院校id 名称 地址 类型 住宿方式 学费 备用金 运营归属 授权平台 审核状态
1,诺丹姆吉本斯主教中学(Notre Dame-Bishop Gibbons School),纽约州-斯克内克塔迪,混校,寄宿家庭,283047,13289,UC代理,校代网/微信,审核通过
2,毕晓普马金高中(Bishop Maginn High School),纽约州-奥尔巴尼,混校,寄宿家庭,277488,13028,UC代理,校代网/微信,审核通过school.txt加载到hive表中的表结构信息:
schoolid int ##院校id
name string ##院校名称
location string ##院校地址
type string ##学校类型
zhusu string ##住宿方式
fee double ##学费
byj double ##备用金
yygs string ##运营归属
sqpt string ##授权平台
shzt string ##审核状态(2)school_loca.txt数据样例
地址id 地址名称
1,加利福尼亚州-洛杉矶
2,纽约州-里弗黑德
3,新泽西州-莱克伍德市
4,安大略省-鲍曼维尔市school_loca.txt加载到hive表中的表结构信息
locationid int ##院校地址id
name string ##院校地址名称(3)对院校信息进行量化处理
sql语句示例:
select
sd.schoolid,
sd.name schoolname,
sd.location,
sl.locationid,
(case
when sd.type="混校" then "0"
when sd.type="男校" then "1"
when sd.type="女校" then "2"
end) as school_type,
(case
when sd.zhusu="寄宿家庭" then "0"
when sd.zhusu="学校宿舍" then "1"
when sd.zhusu="男生学校宿舍/女生寄宿家庭" then "2"
when sd.zhusu="学校宿舍/寄宿家庭" then "3"
when sd.zhusu="学校宿舍-寄宿家庭" then "3"
end) as zs,
sd.fee,
sd.byj
from
school2_detail sd
join
school2_location sl
on sd.location = sl.name;提取出描述一所院校的“特征因子”:学校地址id(locationid)、学校类型(school_type)、住宿方式(zs)、学费(fee)、备用金(byj),并将这些"特征因子"进行量化(除了locationid、fee、byj按照实际值进行量化,scool_type、zs量化标准参考上述sql语句)。
1.2 数据归一化处理
首先了解一个概念,奇异样本数据数据:指相对于其他输入样本特别大或特别小的样本矢量。奇异样本数据数据的存在会引起训练时间增大,并可能引起无法收敛。所以在存在奇异样本数据的情况下,进行训练之前好进行归一化,如果不存在奇异样本数据,则可以不用归一化。
院校"特征因子"具有不同的量纲,为了消除指标之间的量纲影响,需要进行数据标准化处理,以解决数据指标之间的可比性。原始数据经过数据标准化处理后,各指标处于同一数量级,适合进行综合对比评价。
本数据处理采取归一化方式:大—小标准化。
大—小标准化是对原始数据进行线性变换,设MIN(A)和MAX(A)分别是属性A的小值和大值,将A的一个原始值x通过大—小标准化映射到区间[0, 1]的值x’,那么公式如下:x’ = (x - MIN(A)) / (MAX(A) - MIN(A))。
在院校信息中,school_type、zs往往取值较小,而fee、byj取值较大,量纲对数据分析时会产生一定影响,需要进行归一化处理:
schoolId schoolName locationId school_type zs fee byj
归一化前:1 诺丹姆吉本斯主教中学(Notre Dame-Bishop Gibbons School) 71 0 0 283047.0 13289.0
归一化后:1 诺丹姆吉本斯主教中学(Notre Dame-Bishop Gibbons School) 0.693069306930693 0.0 0.0 0.4018890324907577 0.4000060201071579归一化处理sql语句示例:
create table school2_detail_number as
select
sd.schoolid,
sd.name schoolname,
sl.locationid,
(case
when sd.type="混校" then "0"
when sd.type="男校" then "1"
when sd.type="女校" then "2"
end) as school_type,
(case
when sd.zhusu="寄宿家庭" then "0"
when sd.zhusu="学校宿舍" then "1"
when sd.zhusu="男生学校宿舍/女生寄宿家庭" then "2"
when sd.zhusu="学校宿舍/寄宿家庭" then "3"
when sd.zhusu="学校宿舍-寄宿家庭" then "3"
end) as zs,
sd.fee,
sd.byj
from
school2_detail sd
join
school2_location sl
= = = table school2_detail_number_gyh 终归一化结果表 = = = =
create table school2_detail_number_gyh as
select
t1.schoolid,
t1.name,
(t1.locationid-t2.min_lid)/(t2.max_lid-t2.min_lid) as gyh_lid,
(t1.school_type-t2.min_type)/(t2.max_type-t2.min_type) as gyh_school_type,
(t1.zs-t2.min_zs)/(t2.max_zs-t2.min_zs) as gyh_zs,
(t1.fee-t2.min_fee)/(t2.max_fee-t2.min_fee) as gyh_fee,
(t1.byj-t2.min_byj)/(t2.max_byj-t2.min_byj) as gyh_byj
from school2_detail_number t1
join
(select
MAX(locationid) as max_lid,
MIN(locationid) as min_lid,
MAX(school_type) as max_type,
MIN(school_type) as min_type,
MAX(zs) as max_zs,
MIN(zs) as min_zs,
MAX(fee) as max_fee,
MIN(fee) as min_fee,
MAX(byj) as max_byj,
MIN(byj) as min_byj
from school2_detail_number) as t2;2. 基于内容的推荐
2.1 基于内容推荐概述
基于内容的推荐(CB):主要是根据用户过去喜欢的物品(item),为用户推荐和他过去喜欢的物品相似的物品,关键在于item相似度的度量。CB的过程一般包括以下三步:
- 根据item的属性抽取一些特征来表示此item
2. 利用一个用户过去喜欢(及不喜欢)的item特征数据,来学习此用户的喜好特征
3. 通过比较上一步得到的用户喜好特征与“候选”item特征,为此用户推荐一组相似度较大的item
优点:易于实现,不需要用户数据因此不存在稀疏性和冷启动问题;基于物品本身特征推荐,因此不存在过度推荐热门的问题。
缺点:抽取的特征既要保证准确性又要具有一定的实际意义,否则很难保证推荐结果的相关性。
2.2 相似度算法描述
1. 欧几里得距离
衡量空间各个点之间的距离,跟各个点所在位置的坐标直接相关。欧氏距离能够体现个体数值特征的差异,所以更多的用于需要从维度的数值大小中体现差异的分析,如使用用户行为指标分析用户价值的相似度或差异。值域范围[0,正无穷大]
2. 皮尔逊相关系数
强调的是空间中各点之间的线性相关关系。值域范围[-1,1]。0代表无相关性,负值代表负相关,正值代表正相关
3. 余弦相似度
衡量空间向量的夹角,主要体现在方向上的差异,而不是位置。比如A、B两点:保持A点位置不变,B点朝原方向远离坐标轴原点,则二者之间的余弦距离是保持不变的(因为夹角没有变化),但A、B两点的距离明显发生变化。余弦距离更多的是从方向上区分差异,而对的数值不敏感,更多的用于使用用户对内容评分来区分兴趣的相似度和差异,同时修正了用户间可能存在的度量标准不统一的问题(因为余弦距离对数值不敏感)。值域范围[-1,1]
2.3 数据准备和处理
同“基于Spark KMeans对院校进行聚类”中的数据准备
对于相似度算法实现,参考文章《Spark实现推荐系统中的相似度算法》
2.4 具体实现逻辑
待处理数据示例:
院校id 院校名称 院校地址 院校地址id 学校类型 住宿方式 学费 备用金
1,诺丹姆吉本斯主教中学(Notre Dame-Bishop Gibbons School),纽约州-斯克内克塔迪,71,0,0,283047.0,13289.0
2,毕晓普马金高中(Bishop Maginn High School),纽约州-奥尔巴尼,25,0,0,277488.0,13028.0
4,萨拉托加中央天主中学(Saratoga Central Catholic School),纽约州-萨拉托加斯普林斯,72,0,0,285705.0,13289.0
5,天主教中央中学(Catholic Central High School),纽约州-特洛伊,66,0,0,283047.0,13289.0实现思路:
根据上述获得院校详细数据,提取出特征因子,计算各个院校之间的相似度并根据相似度倒序排序,并计算每个院校与它相似的院校取TopN存储到reids中【注意:去掉基准院校】。
3. 基于SparkALS实现离线推荐
3.1 Spark基于模型协同过滤推荐算法ALS
Spark没有像mahout那样,严格区分基于物品的协同过滤推荐(ItemCF)和基于用户的协同过滤推荐(UserCF)。只有基于模型的协同过滤推荐算法ALS(model-based CF)。
ALS通过数量相对少的未被观察到的隐藏因子,来解释大量用户和物品之间潜在联系。ALS基于矩阵分解通过降维的方法来补全用户-物品矩阵,对矩阵中没有出现的值进行估计。
ALS基本假设:任何一个评分矩阵均可近似分解成两个低维的用户特征矩阵和物品特征矩阵。矩阵分解过程可理解成将用户和物品均抽象的映射到相同的低维潜在特征空间中。
3.2 具体实现逻辑
3.2.1 预处理日志数据获得用户对院校的“综合分数”
通过处理采集到的日志数据,得到school_als.txt,示例如下:
| 用户id,操作类型(浏览/收藏等),院校id 1,浏览,141,浏览,261,浏览,11,收藏,12,浏览,152,浏览,82,浏览,122,浏览,10 |
根据用户id和院校id分组获得各个用户对院校的操作类型的次数,从而计算终对应院校的分值(score)【注意:这里暂且将各个操作类型的基础权重设为1,浏览一次权重加0.15、收藏一次权重加0.55,评论一次权重加0.3。后续具体根据业务来定具体的权重】。终得到的数据示例如下:
用户id,院校id,分数,标示id(方便后边切分数据训练ALS模型)
((1,16,1.15),16)
((1,3,1.15),87)
((1,26,2.3),88)
((1,34,1.15),154)3.2.2 训练Spark ALS模型,进行推荐
- 准备数据
1)“历史”综合评分数据:将上一步处理得到的数据,转换成ALS的Rating格式数据,并将标示id模于10(用于切分数据)
2)院校数据(school.txt)处理成(院校id -> 院校名称)并转成map
3)单一用户“实时”综合评分数据:用户在页面实时的行为数据并处理成“用户id,院校id,综合分数”的格式
2. 切分数据
将“综合评分数据”切分成3个部分,60%用于训练(加上单一用户“实时”综合评分数据),20%用于校验,20%用于测试
3. 训练模型
spark ALS训练API主要有这几个参数:
ratings:用户评分数据RDD[Rating]
rank:隐因子个数,越大计算量越大,一般越
iterations:迭代次数
lambda:控制正则化过程,值越高正则化程度越高
计算不同参数下,根据训练集获得的模型计算校验集的RMSE(均方根误差)RMSE小的即为佳模型。
将用户“实时”浏览的院校去掉,其他院校作为“候选”推荐院校,根据训练的优模型取TopN进行推荐。
4. 基于ALS和CB的业务角度分析
4.1 针对用户是否产生实时行为数据的不同处理
注意:由于本推荐系统中基于CB的推荐,是基于院校相似度的推荐(不依赖于用户偏好度数据),只要用户产生浏览/收藏等行为,就能基于浏览/收藏等的院校计算相似院校,所以不考虑新用户“冷启动”问题。
4.1.1 用户产生实时行为数据(浏览/收藏/评论等,设置不同权重)
1)ALS
正常处理
2)CB
参考下方"基于CB的离线和实时推荐结果落地分析"
4.1.2 用户没有产生实时行为数据
1)ALS老用户:直接根据用户历史数据,按照ALS的正常处理逻辑进行处理
新用户:可以推荐一些热门院校、需要推广的院校等
2)CB参考下方"基于CB的离线和实时推荐结果落地分析"
4.2 推荐结果"落地"分析
注意:
- 原始加载的院校数据是基层、完整的数据(包括下线院校),所以推荐院校集要过滤掉已下线院校再进行推荐【也可以在加载院校数据时通过sql语句过滤已下线院校,通过离线计算获得的推荐院校集也就不包含已下线院校;实时的推荐结果也会利用离线的推荐结果集所以获得推荐院校也不包含已下线院校。但是如果在离线结果已形成(当天或之前)或实时计算时下线院校更新而没有及时更新相应的推荐数据会有一定延迟误差】
2. 取TopN存储到redis中,但实际推荐院校的时候只取TopN中的前几个院校数据作为推荐,为了方便进行院校做CRUD处理时,redis中推荐数据的更新
3. 离线推荐结果和在线推荐结果进行汇总做终推荐时,要过滤掉用户已浏览的院校[根据业务具体需求看是否过滤掉近期已经推荐过的院校]
4. 终推荐院校集数量可能不满足需要推荐的院校数量,可以设置默认推荐集(如热点院校)进行补全
4.2.1 离线结果"落地"分析
- 基于CB的离线推荐结果"落地"利用相似度算法,分别计算每一所院校与其他院校的相似度(并根据相似度倒序排序)
==> 如果没有新增院校或已有院校属性("特征因子")不改变,只需计算一次。计算量:200+所院校,计算4W+次。将每个院校相似度计算结果,取TopN进行存储(redis/HBase等)
==> 如存储到redis中:以前缀"recom:offlineCB:"和"基准院校id"拼接成的字符串为key,以与基准院校”相似院校id:相似度”为value("recom:offlineCB:"+baseSchoolId,"sid1:sims1,sid2:sims2,…")
2. 基于Spark ALS的离线推荐结果"落地"
由于ALS需要训练模型,如果每来一个用户,产生了浏览/收藏等行为,ALS模型就要实时重新训练一次,会有一定的延迟;当用户比较多时产生的数据量也比较大,延迟性会进一步加大。因此,采取根据前一天及之前的历史数据,每天训练一次ALS模型,取TopN结果进行存储(redis/HBase等)
==> 如存储到redis中:以前缀"recom:offlineALS:"和"用户id"拼接成的字符串为key,以"推荐给该用户的院校id"为value("recom:offlineALS:"+uId,"sid1,sid2,sid3,…")
注意:设置redis的key前缀是为了区别不同推荐模型
4.2.2 实时结果"落地"分析
用户浏览官网,spark-streaming从kafka消费数据进行处理,先将数据处理成标准化数据:“用户id,操作类型,院校id”,再处理成“用户id,院校id,score”格式。
- 基于CB的实时推荐结果"落地"
根据院校id从Redis中获取该院校基于CB的相似度推荐列表,自定义一个类CusItem.scala(属性:院校id,weight),以“score*相似度”作为终权重weight并根据weight进行倒序排序,取TopN进行推荐(存储到redis:以"recom:realCB:+userId"为key,以推荐院校id列表[拼接成字符串]为value)
2. 基于spark ALS的实时推荐结果"落地"
老用户直接通过用户id获取redis中ALS离线推荐结果(存储到redis中:以"recom:realALS:+userId"为key,以推荐院校id列表[拼接成字符串]为value)
4.3 基于院校"流行度"对实时和离线推荐结果的补充
主要是对热门院校(比如点击率高的、申请率高的)、需要推广的院校等进行推荐。可以根据PV、UV、日均PV或分享率等数据分析出热门院校。能够解决新用户冷启动问题,同时根据不同的用户特点推荐不同的院校
4.4 院校信息发生改变具体分析
当有“新增/删除(包括院校下线)院校”或“已有院校属性发生改变”时,后台录入对院校信息进行处理的同时,异步发送一条消息(如通过ActiveMQ,将院校id和对应的操作类型[add、delete、update])给“调整”计算院校相似度的程序,进行相应的处理。【注意:如果更新院校的属性不是“特征因子”,就不要发送信息了】
4.4.1 新增院校
step1:以新增院校为基准,计算其他院校与该院校的相似度数据,并按照相似度数据进行倒序排序,取TopN存储到redis【去掉基准院校】
step2:以其他院校为基准,分别计算新增院校与其他院校的相似度,用该相似度与其他院校相似度数据中TopN院校后一个院校的相似度数据比较,如果前者比后者小,不作任何操作;如果前者比后者大,根据TopN院校和新增院校的相似度数据进行倒序排序,去除相似度小的,然后更新Redis中相应的数据
4.4.2 删除院校(包括院校下线)
step1:删除Redis中对应删除院校的CB相似度数据
step2:两种情况 =>
1)“删除院校”不在其他院校的TopN列表中,不更新Redis中其他院校的相似度数据
2)“删除院校”在其他院校的TopN列表中,移除该院校[TopN列表移除完的情况:实际业务场景可能性比较小,可不考虑]
4.4.3 已有院校属性发生改变
1. 改变属性不是"特征因子"
不作任何处理[让业务方那边先判断一下改变的属性是不是“特征因子”,如果不是就不要发消息了]。
特殊情况:改变属性是“上线状态”,如果由下线改为上线,则调用‘新增院校’的处理方法
2. 改变属性是"特征因子"
step1:更新自己redis中相似度数据
step2:更新其他院校[两种方式:直接计算各个院校之间的相似度数据,但计算量为200*200+;下面的方式麻烦一点但相对计算量会少很多]
1) 改变院校在其他院校redis中TopN列表计算该院校与其他院校的相似度数据,将该值与TopN列表后一个院校相似度数据进行比较:如果前者比后者大则TopN排序更新redis数据;如果前者比后者小则,重新计算其他院校所有的相似度数据倒序取TopN
2) 改变院校不在其他院校redis中TopN列表
计算该院校与其他院校的相似度数据,将该值与TopN列表后一个院校相似度数据进行比较:如果前者比后者大,进行TopN相似度数据和改变院校相似度数据倒序排序,并移除后一个;如果前者比后者小,不作处理。
对于上述的算法模型实现逻辑以及具体的数据处理、推荐处理等除了算法建模本身的考量,还要结合实际业务做相应调整,企业实际运用中要比上述复杂的多,包括推荐算法的种类、训练模型、数据的标准化,业务的场景,等等。本文更多是抛砖引玉,希望在大家做推荐系统的过程中给出一个参考思路。
关联文章:
关注微信公众号:大数据学习与分享,获取更多技术干货
