与Fescar这种比较复杂的、将分布式事务由一个单独的服务来支撑的架构不同,本文提出的架构不同点主要体现在以下两点:
1)它是无中心的,不需要架设单独的事务服务器,这在某些情况下,例如两个用户之间两两转账时,因为不需要中心服务器的支撑,性能高、实施容易,而且不会出现因为中心服务器的故障导致整个系统不可用的情况。
2)为简化起见,它只支持通过JDBC连接的Datasource,暂不考虑Dubbo等远程协议调用方式,因为通常分布式事务很多情况不是位于异地,而只是在同一个机房下的不同数据库之间。
因为分布式事务本身就比较复杂,本人的水平有限,可能这个架构中有什么逻辑错误没发现,还请指正。
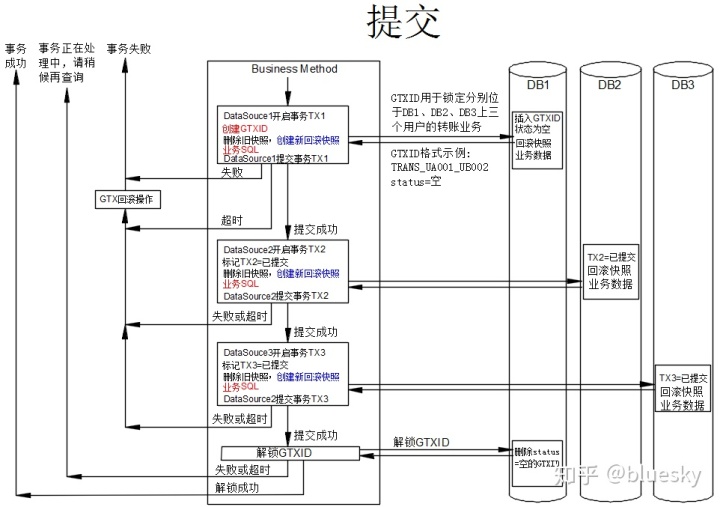
先讲一下提交流程:
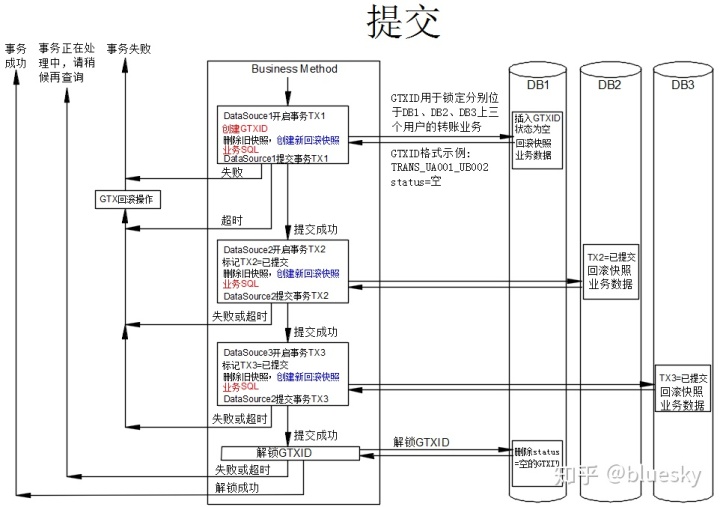
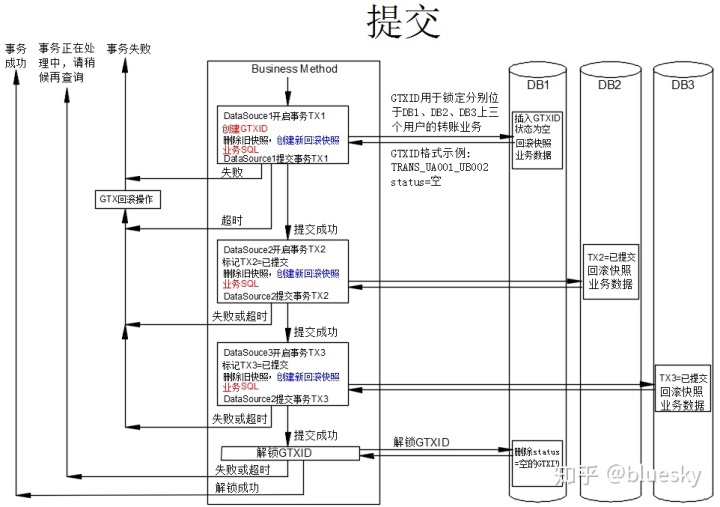
简单说明:
- 整个流程以同时操作三个数据库为例,演示一个完整的分布式事务提交流程,红色字为用户必须提供的代码,蓝色部分即可以由用户实现,也可以由工具类实现,其余黑色字体部分则由工具来提供,用户不需要关心,以减少对业务的入侵。生成回滚SQL是一个比较繁琐的工作,如果完全交给工具实现(如Fescar),因为SQL的复杂性导致解晰和生成快照不是一件轻松的活,数据库兼容性有问题,目前Fescar还在改进中,距离可靠应用还有一段距离。如果交给用户,则工作量太大,不可行。我的一个初步设想是交给ORM工具层,由ORM工具来提供一些API,半自动、半手动地生成快照和回滚SQL,以达到大的数据库兼容性。
- 这个分布式事务实现的原理是基于GTXID实现的全局事务锁,它是一个与业务相关的ID,当GTXID一定时,即相当于锁定了相关的业务,其它需要用到这个业务资源的事务将不能重复获取这个全局事锁。 注意这是一个逻辑锁 ,并不能防范第三方或手工修改数据库字段打破数据一致性。以上概念与Fescar的全局事务锁是相通的。
- 对于分布式事务,它是一个拜占庭将军问题,是无解的,那么它是怎么保证事务的一致性的?在这里,不得不引入一个"事务正在处理中"这一中间状态,专门用来处理网络、硬件等故障造成的“事务有疑问”状态,工具类尽可能处理所有可能处理的情况,实在工具类不能处理时,则必须手工介入处理。以牺牲可用性来确保数据的终一致性。
- 从逻辑上来说,它与Fescar的架构是等同的,只是将分布式事务服务器转移到了个DB上,更易于实施。在阶段,由程序员提供GTXID后,插入到个DB里,并删除以前的快照,重新生成一个数据库快照,以供回滚用,在个阶段,加锁逻辑、生成快照、业务逻辑是混合的。这里的个DB是与业务相关的,并不是固定的,通常由业务性质来决定谁是个DB。
- 如果阶段提交成功,则表示加锁成功,转入对其它数据库的提交。实际上,在个阶段,也可以将对其它数据库的事务打开,但不提交,如果有错误发生,直接将一阶段回滚,连锁都不用加了。
- 后阶段,如果没有错误发生,进行解锁,运行delete from GCTX where gctxid='xxx' and status='空',如果删除成功,则整个分布式事务完成。
如果有错误发生,则会转入回滚流程:

回滚流程的原理与提交非常类似,而且除非是手工干预外,完全由工具类完成,这个部分就不多说了,看图就可以了。
回滚流程的后一步是将gctxid记录状态改为“回滚中”,防止它被删除,后一步是执行delete from GCTX where gctxid='xxx' and status='回滚中',如果删除成功,则回滚成功,否则就需要人工干预了。通常需要人工干预的场合是软件逻辑错误、网络故障、硬件故障等
