本文主要介绍如何搭建一个neo4j高可用集群,往集群中动态添加neo4节点,节点的故障恢复。介绍如何进行事务操作和驱动配置来在节点故障,尤其是neo4j主节点(raft leader,写服务)故障时,尽可能减小对业务的影响。
neo4j raft集群
这里所说的neo4j raft集群是指neo4j企业版的因果集群(Causal Cluster)功能。该集群基于raft实现图数据多副本一致性,在数据的安全性和可服务性上相比仅支持单机的neo4j社区版强大很多。 详细的raft集群搭建流程可参考neo4j官方文档的这两个链接:
这两者基本上是一样的,只是在参数配置上,同个服务器上搭建需要考虑端口的占用问题。 这里简单说下集群的搭建,主要是需要配置文件(conf/neotj.conf)中的几个相关参数:
dbms.connectors.default_listen_address=0.0.0.0
dbms.connectors.default_advertised_address=core01.example.com
dbms.mode=CORE
causal_clustering.minimum_core_cluster_size_at_formation=3
causal_clustering.minimum_core_cluster_size_at_runtime=3
causal_clustering.initial_discovery_members=core01.example.com:5000,core02.example.com:5000,core03.example.com:5000- default_listen_address表示neo4j进程/节点的监听地址,类似于MySQL的bind_address参数。对于数据库服务来说,一般不会做绑定,为此将该设置为0.0.0.0,表示监听所有的IPv4网络地址。
- default_advertised_address用于指定其他机器连接该neo4j节点的域名或IP地址。
- mode指定了该neo4j节点的角色,在neo4j raft集群中,有2种角色,分别是CORE和READ_REPLICA,前者参与raft的majority,后者仅作为raft learner;
- 接下来2个是跟core相关的参数,minimum_core_cluster_size_at_formation表示在初始化本neo4j所在集群时,必须有指定个数的core节点存在才能成功进行集群初始化;minimum_core_cluster_size_at_runtime表示在集群运行期间,必须至少有指定个数的core节点在线;
- initial_discovery_members表示本节点等待加入的neo4j集群中的其他节点。该参数必不可少,作用包括进行节点的数据同步等。
对于一个集群中的不同neo4j节点,这些配置参数需要修改的一般只有default_advertised_address。
初始化新集群
确定了各个节点的配置文件后,就可以使用如下命令启动neo4j进程:
server-1$ ./bin/neo4j start
server-2$ ./bin/neo4j start
server-3$ ./bin/neo4j start这里我们假设http://core01.example.com对应的服务器为server-1,一次对应。从上面的启动命令可以发现,并没有显式指定neo4j的配置文件,这是因为默认配置文件位于bin目录同级的conf目录下,neo4j启动时会自动搜索获取。
root@server-1:/ebs/neo4j-community-3.4.11-SNAPSHOT# ls
bin conf data import lib LICENSES.txt LICENSE.txt logs NOTICE.txt plugins README.txt run UPGRADE.txt
root@server-1:/ebs/neo4j-community-3.4.11-SNAPSHOT# ls ./bin/
neo4j neo4j-admin neo4j-import neo4j-shell tools
root@server-1:/ebs/neo4j-community-3.4.11-SNAPSHOT# ls ./conf/
neo4j.conf neo4j-default.conf
root@server-1:/ebs/neo4j-community-3.4.11-SNAPSHOT#需要注意的是:在初始化集群时,虽然各个节点的启动顺序没有要求,但必须在较短时间内将所有neo4j均启动起来,因为集群形成阶段有个发现其他节点的过程,如果各个节点启动时间相差较大,会导致无法发现足够多的节点而初始化失败。也就是说,neo4j在初始化集群时没有boot节点的概念。 下面是一个neo4j节点从启动到加入集群开始提供服务过程的日志如下所示:
2019-08-15 18:17:57.721+0800 INFO ======== Neo4j 3.4.11-SNAPSHOT ========
2019-08-15 18:17:57.760+0800 INFO Starting...
2019-08-15 18:17:59.334+0800 INFO Initiating metrics...
2019-08-15 18:17:59.428+0800 INFO My connection info: [
Discovery: listen=0.0.0.0:5000, advertised=59.111.222.xxx:5000,
Transaction: listen=0.0.0.0:6000, advertised=59.111.222.xxx:6000,
Raft: listen=0.0.0.0:7000, advertised=59.111.222.xxx:7000,
Client Connector Addresses: bolt://59.111.222.xxx:7687,http://59.111.222.xxx:7474,https://59.111.222.xxx:7473
]
2019-08-15 18:17:59.428+0800 INFO Discovering cluster with initial members: [127.0.0.1:5000, 127.0.0.1:5100, 127.0.0.1:5200]
2019-08-15 18:17:59.428+0800 INFO Attempting to connect to the other cluster members before continuing...
2019-08-15 18:22:09.635+0800 INFO Sending metrics to CSV file at /ebs/neo4j1/metrics
2019-08-15 18:22:09.644+0800 INFO Started publishing Prometheus metrics at http://localhost:2004/metrics
2019-08-15 18:22:09.723+0800 INFO Bolt enabled on 0.0.0.0:7687.
2019-08-15 18:22:12.319+0800 INFO Started.
2019-08-15 18:22:12.540+0800 INFO Mounted REST API at: /db/manage
2019-08-15 18:22:12.620+0800 INFO Server thread metrics has been registered successfully
2019-08-15 18:22:13.540+0800 INFO Remote interface available at http://59.111.222.xxx:7474/显然,很容易发现,上面的例子是在同一个服务器上创建的 neo4j集群。上述仅是一个测试环境的例子,在生产环境中,不建议使用公网ip作为neo4j服务端口。
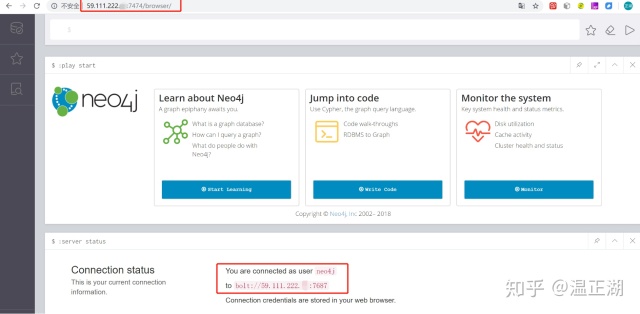
接下来,可以通过“http://59.111.222.xxx:7474”来访问该neo4j节点。次登录时,会要求输出账号和密码(neo4j/neo4j)。登录后修改密码提高访问权限。浏览器中会出现neo4j browser界面。虽然访问端口是7474,但neo4j browser实际上是通过bolt协议访问default_advertised_address对应的ip地址上(默认)7687端口,如下所示:
可以通过call dbms.cluster.overview()和call dbms.cluster.routing.getServers()来查看集群成员角色和请求路由信息:

可以发现,有2个FOLLOWER节点,1个LEADER节点。写被路由到LEADER节点,FOLLOWER节点仅能进行读操作。
我们可以连上LEADER节点插入一个顶点,再连上任意FOLLOWER节点查看该顶点是否存在。

先查询下图中是否存在name为wzh的Person,确认没有后再插入。在另一个节点查询确认是否已完成数据同步。

往集群中加入新节点
接下来,我们尝试往集群中加入一个全新的节点,看看会发生什么。
2019-08-20 15:21:28.294+0800 INFO [o.n.c.r.ReadReplicaStartupProcess] Local database is empty, attempting to replace with copy from upstream server MemberId{2738a484}
2019-08-20 15:21:28.294+0800 INFO [o.n.c.r.ReadReplicaStartupProcess] Finding store id of upstream server MemberId{2738a484}
2019-08-20 15:21:28.398+0800 INFO [o.n.c.p.h.HandshakeClientInitializer] Scheduling handshake (and timeout) local null remote null
2019-08-20 15:21:28.407+0800 INFO [o.n.c.p.h.HandshakeClientInitializer] Initiating handshake local /10.0.8.169:46062 remote /59.111.222.xxx:6000
2019-08-20 15:21:28.453+0800 INFO [o.n.c.p.h.HandshakeClientInitializer] Installing: ProtocolStack{applicationProtocol=CATCHUP_1, modifierProtocols=[]}
2019-08-20 15:21:28.484+0800 INFO [o.n.c.r.ReadReplicaStartupProcess] Copying store from upstream server MemberId{2738a484}
2019-08-20 15:21:28.503+0800 INFO [o.n.c.c.s.StoreCopyClient] Requesting store listing from: 59.111.222.xxx:6000上面是新节点的debug.log文件中的日志,可以看出neo4j起来后,发现本地数据库为空,会尝试从其他节点拷贝数据覆盖本地数据。所选择的节点id为 MemberId{2738a484},对应ip为59.111.222.xxx:6000。 完成拷贝后,通过其他节点的browser可以看到新加入的节点。

从日志和官方文档store copy小结的内容:
Causal Clustering uses a robust and configurable store copy protocol. When a store copy is started it will first send a prepare request to the specified instance. If the prepare request is successful the client will send file and index requests, one request per file or index, to provided upstream members in the cluster.
可以发现,neo4j支持没有数据的新节点加入集群,neo4j会通过store copy流程进行全量拷贝,将其他节点的数据拷贝到新节点上,而且走的是物理拷贝,每次一个数据或索引文件。
这是一个非常不错的特性,大大方便了neo4j集群的故障运维操作。与MySQL 8.0.17版本新增的InnoDB克隆功能类似。
集群故障恢复
下面我们尝试kill掉LEADER节点的neo4j进程,看看是否能够进行自动选主。
2019-08-20 19:07:39.352+0800 WARN [o.n.c.m.SenderService] Lost connection to: 59.111.222.81:7200 (/59.111.222.81:7200)
2019-08-20 19:07:39.353+0800 INFO [o.n.c.p.h.HandshakeClientInitializer] Scheduling handshake (and timeout) local null remote null
2019-08-20 19:07:39.354+0800 WARN [o.n.c.m.SenderService] Failed to connect to: /59.111.222.81:7200. Retrying in 100 ms
2019-08-20 19:07:39.455+0800 INFO [o.n.c.p.h.HandshakeClientInitializer] Scheduling handshake (and timeout) local null remote null
2019-08-20 19:07:39.657+0800 INFO [o.n.c.p.h.HandshakeClientInitializer] Scheduling handshake (and timeout) local null remote null
2019-08-20 19:07:40.060+0800 INFO [o.n.c.p.h.HandshakeClientInitializer] Scheduling handshake (and timeout) local null remote null
2019-08-20 19:07:40.865+0800 INFO [o.n.c.p.h.HandshakeClientInitializer] Scheduling handshake (and timeout) local null remote null
2019-08-20 19:07:42.169+0800 INFO [o.n.c.d.HazelcastCoreTopologyService] Core member removed MembershipEvent {member=Member [127.0.0.1]:5200 - 8c4a157d-271
8-47b3-bf5b-75a9291a74c8,type=removed}
2019-08-20 19:07:42.171+0800 INFO [o.n.c.d.HazelcastCoreTopologyService] Core topology changed {added=[], removed=[{memberId=MemberId{d8fbf929}, info=CoreS
erverInfo{raftServer=59.111.222.81:7200, catchupServer=59.111.222.81:6200, clientConnectorAddresses=bolt://59.111.222.81:7887,http://59.111.222.81:7674,htt
ps://59.111.222.81:7673, groups=[]}}]}
2019-08-20 19:07:42.171+0800 INFO [o.n.c.c.c.m.RaftMembershipManager] Target membership: [MemberId{2738a484}, MemberId{8b5fd3fe}]
2019-08-20 19:07:42.171+0800 INFO [o.n.c.c.c.m.RaftMembershipManager] Not safe to remove member [MemberId{d8fbf929}] because it would reduce the number of
voting members below the expected cluster size of 3. Voting members: [MemberId{d8fbf929}, MemberId{8b5fd3fe}, MemberId{2738a484}]
2019-08-20 19:07:42.469+0800 INFO [o.n.c.p.h.HandshakeClientInitializer] Scheduling handshake (and timeout) local null remote null
2019-08-20 19:07:44.073+0800 INFO [o.n.c.p.h.HandshakeClientInitializer] Scheduling handshake (and timeout) local null remote null
2019-08-20 19:07:45.677+0800 INFO [o.n.c.p.h.HandshakeClientInitializer] Scheduling handshake (and timeout) local null remote null使用neo4j stop停掉或通过kill -9杀掉当前主节点后,另一个节点检测到失联信息“Lost connection to: 59.111.222.81:7200 (/59.111.222.81:7200)”。开始不断重连“Scheduling handshake (and timeout) local null remote null”。 接着HazelcastCoreTopologyService对象将失联节点移除。随后RaftMembershipManager对象也尝试移除失联节点,但由于我们设置的minimum_core_cluster_size_at_runtime为3,所以移除失败。因此HandshakeClientInitializer对象一直维持对失联节点的重连尝试。
2019-08-20 19:08:43.340+0800 INFO [o.n.c.c.c.RaftMachine] Election timeout triggered
2019-08-20 19:08:43.342+0800 INFO [o.n.c.c.c.RaftMachine] Election started with vote request: Vote.Request from MemberId{8b5fd3fe} {term=17, candidate=Memb
erId{8b5fd3fe}, lastAppended=113496, lastLogTerm=16} and members: [MemberId{d8fbf929}, MemberId{8b5fd3fe}, MemberId{2738a484}]
2019-08-20 19:08:43.342+0800 INFO [o.n.c.c.c.RaftMachine] Moving to CANDIDATE state after successfully starting election
2019-08-20 19:08:43.345+0800 INFO [o.n.c.m.RaftOutbound] No address found for MemberId{d8fbf929}, probably because the member has been shut down.
2019-08-20 19:08:43.364+0800 INFO [o.n.c.c.c.RaftMachine] Moving to LEADER state at term 17 (I am MemberId{8b5fd3fe}), voted for by [MemberId{2738a484}]
2019-08-20 19:08:43.365+0800 INFO [o.n.c.c.c.s.RaftState] Leader changed from MemberId{d8fbf929} to MemberId{8b5fd3fe}一分钟之后,本节点的选举超时被触发,开始选主操作,选主的信息为“Vote.Request from MemberId{8b5fd3fe} {term=17, candidate=Memb erId{8b5fd3fe}, lastAppended=113496, lastLogTerm=16} and members: [MemberId{d8fbf929}, MemberId{8b5fd3fe}, MemberId{2738a484}]”指明了选主请求发起节点的选举信息(新任期,候选节点,节点的日志和当前所处任期),参与选举的节点集合。候选节点将自己的状态切换为CANDIDATE,在得到另一个节点MemberId{2738a484}的选票后,切换为LEADER状态,leader节点。
上一段提到一分钟之后触发选举,这是由参数causal_clustering.leader_election_timeout控制的,默认为7s,例子中我们设置为60s。可以根据neo4j所运行的网络环境和业务负载情况进行调整。需要注意的是,该值的调整需要跟业务逻辑对重试行为相匹配,在后面的“neo4j驱动”小节会展开来讲。
预选举
为了提高集群的稳定性,降低由于网络抖动等因素导致leader节点频繁切换,neo4j支持开启预选举特性,可通过causal_clustering.enable_pre_voting开启。开启后,日志如下:
2019-08-23 09:44:39.993+0800 INFO [o.n.c.c.c.RaftMachine] Election timeout triggered
2019-08-23 09:44:39.994+0800 INFO [o.n.c.c.c.RaftMachine] Pre-election started with: PreVote.Request from MemberId{4c669302} {term=4, candidate=MemberId{4c
669302}, lastAppended=86720, lastLogTerm=4} and members: [MemberId{31fe5843}, MemberId{18c53057}, MemberId{4c669302}]
2019-08-23 09:44:39.994+0800 INFO [o.n.c.m.RaftOutbound] No address found for MemberId{18c53057}, probably because the member has been shut down.
2019-08-23 09:44:39.999+0800 INFO [o.n.c.c.c.RaftMachine] Election started with vote request: Vote.Request from MemberId{4c669302} {term=5, candidate=Membe
rId{4c669302}, lastAppended=86720, lastLogTerm=4} and members: [MemberId{31fe5843}, MemberId{18c53057}, MemberId{4c669302}]
2019-08-23 09:44:39.999+0800 INFO [o.n.c.c.c.RaftMachine] Moving to CANDIDATE state after successful pre-election stage
2019-08-23 09:44:40.024+0800 INFO [o.n.c.c.c.RaftMachine] Moving to LEADER state at term 5 (I am MemberId{4c669302}), voted for by [MemberId{31fe5843}]
2019-08-23 09:44:40.024+0800 INFO [o.n.c.c.c.s.RaftState] Leader changed from MemberId{18c53057} to MemberId{4c669302}关于更进一步得选举实现,可参考官方文档选举。虽然3.4版本官方文档没有预选举特性的说明,但其实跟3.5版本一样,功能是存在的。
节点故障修复
neo4j的单机和集群节点,其磁盘数据管理方式并非完全相同,单机实例无法提升为集群节点,集群节点可以降级为单机实例。单机的事务日志直接写tx_log指定的目录中,而neo4j集群的事务提交,是先写到raft_log文件中的。详细描述见官方文档描述。
对于节点被kill掉的场景,neo4j启动后会进行故障修复。需要做很多事情,包括存储的数据一致性检查、事务日志回放和元数据、数据和索引文件重建等。日志截取如下:
2019-08-23 13:56:20.526+0800 INFO [o.n.k.i.DiagnosticsManager] --- INITIALIZED diagnostics START ---
2019-08-23 13:56:20.646+0800 INFO [o.n.k.i.DiagnosticsManager] --- INITIALIZED diagnostics END ---
2019-08-23 13:56:31.031+0800 INFO [o.n.k.i.i.s.f.FusionIndexProvider] Schema index cleanup job registered:xxx
2019-08-23 13:56:31.157+0800 INFO [o.n.k.i.i.l.NativeLabelScanStore] Label index cleanup job registered
2019-08-23 13:56:31.158+0800 INFO [o.n.k.NeoStoreDataSource] Commits found after last check point (which is at LogPosition{logVersion=0, byteOffset=45575883}). First txId after last checkpoint: 115322
2019-08-23 13:56:31.158+0800 INFO [o.n.k.NeoStoreDataSource] Recovery required from position LogPosition{logVersion=0, byteOffset=45575883}
2019-08-23 13:56:31.202+0800 INFO [o.n.k.r.Recovery] 10% completed
2019-08-23 13:56:31.214+0800 INFO [o.n.k.r.Recovery] 20% completed
2019-08-23 13:56:31.224+0800 INFO [o.n.k.r.Recovery] 30% completed
2019-08-23 13:56:31.230+0800 INFO [o.n.k.r.Recovery] 40% completed
2019-08-23 13:56:31.238+0800 INFO [o.n.k.r.Recovery] 50% completed
2019-08-23 13:56:31.346+0800 INFO [o.n.k.r.Recovery] 60% completed
2019-08-23 13:56:31.394+0800 INFO [o.n.k.r.Recovery] 70% completed
2019-08-23 13:56:31.439+0800 INFO [o.n.k.r.Recovery] 80% completed
2019-08-23 13:56:31.473+0800 INFO [o.n.k.r.Recovery] 90% completed
2019-08-23 13:56:31.506+0800 INFO [o.n.k.r.Recovery] completed
2019-08-23 13:56:31.507+0800 INFO [o.n.k.NeoStoreDataSource] Recovery completed. 866 transactions, first:115322, last:116187 recovered
2019-08-23 13:56:31.509+0800 INFO [o.n.k.i.s.DynamicArrayStore] Rebuilding id generator for[/ebs/neo4j-holmes3/data/databases/wzh_rc.db/neostore.nodestore.db.labels] ...
2019-08-23 13:56:31.580+0800 INFO [o.n.k.i.i.l.NativeLabelScanStore] Label index cleanup job started
2019-08-23 13:56:31.580+0800 INFO [o.n.k.i.i.l.NativeLabelScanStore] Label index cleanup job finished: Number of pages visited: 11, Number of cleaned crashed pointers: 0, Time spent: 0ms
2019-08-23 13:56:31.580+0800 INFO [o.n.k.i.i.l.NativeLabelScanStore] Label index cleanup job closed
2019-08-23 13:56:31.609+0800 INFO [o.n.k.i.DatabaseHealth] Database health set to OK
2019-08-23 13:56:31.841+0800 INFO [o.n.c.c.s.m.t.LastCommittedIndexFinder] Last transaction id in metadata store 116187
2019-08-23 13:56:32.085+0800 INFO [o.n.c.c.s.m.t.LastCommittedIndexFinder] Start id of last committed transaction in transaction log 116186
2019-08-23 13:56:32.085+0800 INFO [o.n.c.c.s.m.t.LastCommittedIndexFinder] Last committed transaction id in transaction log 116187
2019-08-23 13:56:32.086+0800 INFO [o.n.c.c.s.m.t.LastCommittedIndexFinder] Last committed consensus log index committed into tx log 116591
2019-08-23 13:56:32.086+0800 INFO [o.n.c.c.s.m.t.ReplicatedTransactionStateMachine] Updated lastCommittedIndex to 116591
2019-08-23 13:56:32.087+0800 INFO [o.n.c.c.s.m.t.ReplicatedTokenStateMachine] (Label) Updated lastCommittedIndex to 116591
2019-08-23 13:56:32.087+0800 INFO [o.n.c.c.s.m.t.ReplicatedTokenStateMachine] (RelationshipType) Updated lastCommittedIndex to 116591
2019-08-23 13:56:32.087+0800 INFO [o.n.c.c.s.m.t.ReplicatedTokenStateMachine] (PropertyKey) Updated lastCommittedIndex to 116591
2019-08-23 13:56:32.088+0800 INFO [o.n.c.c.s.CommandApplicationProcess] Restoring last applied index to 113496
2019-08-23 13:56:32.088+0800 INFO [o.n.c.c.s.CommandApplicationProcess] Resuming after startup (count = 0)
2019-08-23 13:56:32.100+0800 INFO [o.n.c.n.Server] catchup-server: bound to 0.0.0.0:6200
2019-08-23 13:56:32.103+0800 INFO [o.n.c.n.Server] backup-server: bound to 127.0.0.1:6562
2019-08-23 13:56:34.878+0800 INFO [o.n.c.p.h.HandshakeServerInitializer] Installing handshake server local /10.0.8.169:6200 remote /59.111.222.xxx:41136
2019-08-23 13:56:47.140+0800 INFO [o.n.c.m.SenderService] Creating channel to: [59.111.222.81:7000]
2019-08-23 13:56:47.144+0800 INFO [o.n.c.p.h.HandshakeClientInitializer] Scheduling handshake (and timeout) local null remote null
2019-08-23 13:56:47.148+0800 INFO [o.n.c.c.c.s.RaftState] First leader elected: MemberId{2738a484}
2019-08-23 13:56:47.148+0800 INFO [o.n.c.d.HazelcastCoreTopologyService] Leader MemberId{d8fbf929} updating leader info for database default and term 20
2019-08-23 13:56:47.163+0800 INFO [o.n.c.m.SenderService] Connected: [id: 0x01a0acb6, L:/10.0.8.169:33836 - R:/59.111.222.xxx:7000]
2019-08-23 13:56:47.166+0800 INFO [o.n.c.p.h.HandshakeClientInitializer] Initiating handshake local /10.0.8.169:33836 remote /59.111.222.xxx:7000
2019-08-23 13:56:47.194+0800 INFO [o.n.c.p.h.HandshakeClientInitializer] Installing: ProtocolStack{applicationProtocol=RAFT_1, modifierProtocols=[]}
2019-08-23 14:00:32.105+0800 INFO [o.n.c.c.c.m.MembershipWaiter] MemberId{d8fbf929} Catchup: 117587 => 117587 (0 behind)这里,我们仅关系日志回放部分:
2019-08-23 13:56:31.158+0800 INFO [o.n.k.NeoStoreDataSource] Commits found after last check point (which is at LogPosition{logVersion=0, byteOffset=45575883}). First txId after last checkpoint: 115322
2019-08-23 13:56:31.158+0800 INFO [o.n.k.NeoStoreDataSource] Recovery required from position LogPosition{logVersion=0, byteOffset=45575883}
2019-08-23 13:56:31.202+0800 INFO [o.n.k.r.Recovery] 10% completed
2019-08-23 13:56:31.214+0800 INFO [o.n.k.r.Recovery] 20% completed
2019-08-23 13:56:31.224+0800 INFO [o.n.k.r.Recovery] 30% completed
2019-08-23 13:56:31.230+0800 INFO [o.n.k.r.Recovery] 40% completed
2019-08-23 13:56:31.238+0800 INFO [o.n.k.r.Recovery] 50% completed
2019-08-23 13:56:31.346+0800 INFO [o.n.k.r.Recovery] 60% completed
2019-08-23 13:56:31.394+0800 INFO [o.n.k.r.Recovery] 70% completed
2019-08-23 13:56:31.439+0800 INFO [o.n.k.r.Recovery] 80% completed
2019-08-23 13:56:31.473+0800 INFO [o.n.k.r.Recovery] 90% completed
2019-08-23 13:56:31.506+0800 INFO [o.n.k.r.Recovery] completed
2019-08-23 13:56:31.507+0800 INFO [o.n.k.NeoStoreDataSource] Recovery completed. 866 transactions, first:115322, last:116187 recovered作为事务型数据库,crash后进行事务恢复是必须的。MySQL是这样,neo4j也是这样。但跟MySQL的InnoDB存储引擎不一样的是两者的事务日志组织管理上。InnoDB的redo日志文件是固定大小的,空间循环利用。而neo4j的事务日志管理类似于MySQL Binlog管理,是可以无限增长的。
事务日志管理和checkpoint
因此,如果在故障恢复/recovery前累积了大量的事务日志,那么就需要花费很长的时间进行recovery操作。如果写入压力很大,可能需要数个小时。而与日志累积有关的参数包括但不限于如下几个:
neo4j-sh (?)$ call dbms.listConfig() yield name, value where name contains 'dbms.checkpoint' return name, value;
+----------------------------------------------+
| name | value |
+----------------------------------------------+
| "dbms.checkpoint" | "periodic" |
| "dbms.checkpoint.interval.time" | "900000ms" |
| "dbms.checkpoint.interval.tx" | "100000" |
| "dbms.checkpoint.iops.limit" | "300" |
+----------------------------------------------+
4 rows
48 ms
neo4j-sh (?)$ call dbms.listConfig() yield name, value where name contains 'dbms.tx_log' return name, value;
+-------------------------------------------------------+
| name | value |
+-------------------------------------------------------+
| "dbms.tx_log.rotation.retention_policy" | "7 days" |
| "dbms.tx_log.rotation.size" | "262144000" |
+-------------------------------------------------------+
2 rows
32 ms上述所列6个参数均为默认值。官方文档对这些含义也有比较清楚的描述。
- dbms.checkpoint:指定neo4j节点做checkpoint的策略,默认为periodic,也就是周期性执行checkpoint。这种策略情况下具体行为与interval.time和interval.tx两个参数值相关。neo4j企业版还支持另外2种策略,分别是‘continuous’和‘volumetric’,种会忽略其他参数,一直做checkpoint;第二种策略的行为依赖于事务日志回收参数dbms.tx_log.rotation.retention_policy的设置相关。
- dbms.checkpoint.interval.time:指定至少多少时间执行一次checkpoint;dbms.checkpoint.interval.tx:指定至少多少个事务后才会执行一次checkpoint。这两个参数满足其中一个即可触发checkpoint操作。
- dbms.checkpoint.iops.limit:指定了做checkpoint时可使用的IO资源,具体来说就是指定了可以执行多少个8KB的写IO。默认为300个,可以将其设置为-1表示可以不受限制地使用。
- dbms.tx_log.rotation.size:指定每个事务日志文件的大小,达到该大小即切换到一个新的日志文件;
- dbms.tx_log.rotation.retention_policy:该参数规定了事务日志文件保留策略,true表示不删除文件,显然地,一般不会这么做;false表示仅保留新的非空文件,也就是会保留不大于dbms.tx_log.rotation.size的日志量;还可以设置为保留多少天或多少日志量或多少个事务。
在进行故障恢复时,需要从新/后一次checkpoint之后产生的事务日志开始。checkpoint行为对故障恢复所需时间有决定性影响。未进行checkpoint的日志量越大,需要的恢复时间越长。
显然,日志的保留策略和checkpoint的策略有关系,只有该日志文件已经都完成checkpoint后才能被安全地删除。在3种checkpoint策略中,‘volumetric’会根据日志的保留策略来进行checkpoint操作。
neo4j驱动
本节我们以neo4j的java驱动(neo4j-java-driver)为例来说明neo4j驱动的使用方式。 目前新的java驱动为1.7.5版本,对于maven项目,需要进行如下配置:
<dependencies>
<dependency>
<groupId>org.neo4j.driver</groupId>
<artifactId>neo4j-java-driver</artifactId>
<version>1.7.5</version>
</dependency>
</dependencies>所依赖的java版本为Java 8+。
驱动的连接方式
neo4j提供了2种连接模式,分别是单机模式和集群模式。下面是单机模式的一个例子:
public class HelloWorldExample implements AutoCloseable
{
private final Driver driver;
public HelloWorldExample( String uri, String user, String password )
{
driver = GraphDatabase.driver( uri, AuthTokens.basic( user, password ) );
}
@Override
public void close() throws Exception
{
driver.close();
}
public void printGreeting( final String message )
{
try ( Session session = driver.session() )
{
String greeting = session.writeTransaction( new TransactionWork<String>()
{
@Override
public String execute( Transaction tx )
{
StatementResult result = tx.run( "CREATE (a:Greeting) " +
"SET a.message = $message " +
"RETURN a.message + ', from node ' + id(a)",
parameters( "message", message ) );
return result.single().get( 0 ).asString();
}
} );
System.out.println( greeting );
}
}
public static void main( String... args ) throws Exception
{
try ( HelloWorldExample greeter = new HelloWorldExample( "bolt://localhost:7687", "neo4j", "password" ) )
{
greeter.printGreeting( "hello, world" );
}
}
}注:该例子使用的是事务函数模式。
生命周期
从上面的例子可以看出,通过 GraphDatabase.driver()方法返回一个Driver对象,然后基于该对象获取Session对象,在Session对象中执行读写事务操作。后调用Driver对象的close()方法将其关闭。
从main()函数可知,单机模式通过“bolt:”前缀连接,其只适用于在neo4j单机实例,或在neo4j集群下连接到特定的READ_REPLICA节点进行只读操作。因为其不具备在所连接的节点故障时切换到其他节点的能力。
集群模式
将单机模式的连接前缀从“bolt:”改为“bolt+routing:”即变为集群模式。形如“bolt+routing://graph.example.com:7687”。
驱动会访问http://graph.example.com:7687地址,并通过“dbms.cluster.routing.getServers()”返回集群中的详细路由信息。
neo4j-sh (?)$ call dbms.cluster.routing.getServers();
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| ttl | servers |
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| 300 | [{addresses -> ["59.111.222.xxx:7787"], role -> "WRITE"},{addresses -> ["59.111.222.xxx:7687","59.111.222.xxx:7887","59.111.222.81:7987"], role -> "READ"},{addresses -> ["59.111.222.xxx:7887","59.111.222.xxx:7687","59.111.222.xxx:7787"], role -> "ROUTE"}] |
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row
40 ms返回信息中包括WRITE可写节点,及leader;READ只读节点,可包括非leader的CORE节点和所有的READ_REPLICA节点;后是可用于路由的节点,即全部的CORE节点。我们结合“dbms.cluster.overview()”可以有更加直观的理解。
neo4j-sh (?)$ call dbms.cluster.overview();
+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| id | addresses | role | groups | database |
+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| "2738a484-cb78-46cc-91a2-694646336f7e" | ["bolt://59.111.222.xxx:7687","http://59.111.222.xxx:7474","https://59.111.222.xxx:7473"] | "FOLLOWER" | [] | "default" |
| "8b5fd3fe-e347-40fe-b3e2-18291aa1e678" | ["bolt://59.111.222.xxx:7787","http://59.111.222.xxx:7574","https://59.111.222.xxx:7573"] | "LEADER" | [] | "default" |
| "d8fbf929-47fb-4ff6-9827-29ea67ab221a" | ["bolt://59.111.222.xxx:7887","http://59.111.222.xxx:7674","https://59.111.222.xxx:7673"] | "FOLLOWER" | [] | "default" |
| "a6ef5255-3a71-48cb-9b9a-42512643d4c4" | ["bolt://59.111.222.xxx:7987","http://59.111.222.xxx:7774","https://59.111.222.xxx:7773"] | "READ_REPLICA" | [] | "default" |
+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------+
4 rows
11 ms显然,驱动的输出日志是跟上面完全一致的:
八月 23, 2019 10:59:54 上午 org.neo4j.driver.internal.logging.JULogger info
信息: Routing driver instance 1286783232 created for server address 59.111.222.xxx:7687
八月 23, 2019 10:59:54 上午 org.neo4j.driver.internal.logging.JULogger info
信息: Routing table is stale. Ttl 1566529194229, currentTime 1566529194246, routers AddressSet=[59.111.222.xxx:7687], writers AddressSet=[], readers AddressSet=[]
八月 23, 2019 10:59:54 上午 org.neo4j.driver.internal.logging.JULogger info
信息: Updated routing table. Ttl 1566529494853, currentTime 1566529194855, routers AddressSet=[59.111.222.xxx:7687, 59.111.222.xxx:7887, 59.111.222.xxx:7787], writers AddressSet=[59.111.222.xxx:7787], readers AddressSet=[59.111.222.xxx:7687, 59.111.222.xxx:7987, 59.111.222.xxx:7887]
-
八月 23, 2019 10:59:55 上午 org.neo4j.driver.internal.logging.JULogger info
信息: Closing driver instance 1286783232
八月 23, 2019 10:59:55 上午 org.neo4j.driver.internal.logging.JULogger info
信息: Closing connection pool towards 59.111.222.xxx:7787
八月 23, 2019 10:59:55 上午 org.neo4j.driver.internal.logging.JULogger info
信息: Closing connection pool towards 59.111.222.xxx(59.111.222.xxx):7687而且,从“Updated routing table. Ttl 1566529494853, currentTime 1566529194855”可以看出,路由信息的有效时间是300s,也就是每个5分钟更新一次路由信息。
支持多种子连接
在驱动中仅配置neo4j集群的一个节点信息是不够的。因为如果该节点发生故障,那么业务就无法连上该集群了。所以,在连接时提供多个可选路由非常重要。neo4j作为一个成熟的数据库产品,显然也考虑到了。官方的例子如下:
private Driver createDriver( String virtualUri, String user, String password, ServerAddress... addresses )
{
Config config = Config.builder()
.withResolver( address -> new HashSet<>( Arrays.asList( addresses ) ) )
.build();
return GraphDatabase.driver( virtualUri, AuthTokens.basic( user, password ), config );
}
private void addPerson( String name )
{
String username = "neo4j";
String password = "some password";
try ( Driver driver = createDriver( "bolt+routing://x.acme.com", username, password, ServerAddress.of( "a.acme.com", 7676 ),
ServerAddress.of( "b.acme.com", 8787 ), ServerAddress.of( "c.acme.com", 9898 ) ) )
{
try ( Session session = driver.session( AccessMode.WRITE ) )
{
session.run( "CREATE (a:Person {name: $name})", parameters( "name", name ) );
}
}
}可通过“Config.builder().withResolver()”方法来配置多个neo4j节点信息。 注:该例子采用的是自动提交事务模式。
驱动层failover
但,不要以为这样就稳了。我们在上篇文章提到,neo4j中事务由3种模式,分别是自动提交事务,事务函数和显式事务。neo4j官方推荐用事务函数模式,这是因为它支持事务重试,可以在发送neo4j节点故障或leader节点切换等情况下进行节点重连或重新路由。下面举个事务函数模式下重连的例子。 起一个事务函数,在函数中循环插入一些数据,当把leader节点stop掉后,出现异常和重试日志,采集如下:
八月 23, 2019 11:50:47 上午 org.neo4j.driver.internal.logging.JULogger warn
警告: Transaction failed and will be retried in 1157ms
八月 23, 2019 11:50:49 上午 org.neo4j.driver.internal.logging.JULogger warn
警告: Transaction failed and will be retried in 1777ms
八月 23, 2019 11:50:52 上午 org.neo4j.driver.internal.logging.JULogger warn
警告: Transaction failed and will be retried in 4771ms
八月 23, 2019 11:50:56 上午 org.neo4j.driver.internal.logging.JULogger warn
警告: Transaction failed and will be retried in 6693ms
八月 23, 2019 11:51:03 上午 org.neo4j.driver.internal.logging.JULogger warn
警告: Transaction failed and will be retried in 17082ms这能够说明,该事务确实会进行重试,而且重试的间隔是遵从指数增长的。但在后一次17s的重试后,程序就结束了。并没有再次重试。这原因是重试的超时时间默认为30s。对应代码如下:
/**
* Specify the maximum time transactions are allowed to retry via
* {@link Session#readTransaction(TransactionWork)} and {@link Session#writeTransaction(TransactionWork)}
* methods. These methods will retry the given unit of work on {@link ServiceUnavailableException},
* {@link SessionExpiredException} and {@link TransientException} with exponential backoff using initial
* delay of 1 second.
* <p>
* Default value is 30 seconds.
*
* @param value the timeout duration
* @param unit the unit in which duration is given
* @return this builder
* @throws IllegalArgumentException when given value is negative
*/
public ConfigBuilder withMaxTransactionRetryTime( long value, TimeUnit unit )
{
long maxRetryTimeMs = unit.toMillis( value );
if ( maxRetryTimeMs < 0 )
{
throw new IllegalArgumentException( String.format(
"The max retry time may not be smaller than 0, but was %d %s.", value, unit ) );
}
this.retrySettings = new RetrySettings( maxRetryTimeMs );
return this;
}而在本例中,30s是不够的,因为我们设置的causal_clustering.leader_election_timeout选举超时时间为60s,显然,需要至少60s才能选出新的leader节点。所以,修改例子,将重试超时时间设置为10分钟。
private Driver createDriver( String virtualUri, String user, String password, ServerAddress... addresses )
{
Config config = Config.builder()
.withResolver( address -> new HashSet<>( Arrays.asList( addresses ) ) )
.withMaxTransactionRetryTime(600, TimeUnit.SECONDS)
.build();
return GraphDatabase.driver( virtualUri, AuthTokens.basic( user, password ), config );
}重新开始并关闭leader后,日志如下:
八月 23, 2019 12:17:27 下午 org.neo4j.driver.internal.logging.JULogger warn
警告: Transaction failed and will be retried in 822ms
八月 23, 2019 12:17:29 下午 org.neo4j.driver.internal.logging.JULogger warn
警告: Transaction failed and will be retried in 2182ms
八月 23, 2019 12:17:32 下午 org.neo4j.driver.internal.logging.JULogger warn
警告: Transaction failed and will be retried in 3652ms
八月 23, 2019 12:17:36 下午 org.neo4j.driver.internal.logging.JULogger warn
警告: Transaction failed and will be retried in 8935ms
八月 23, 2019 12:17:46 下午 org.neo4j.driver.internal.logging.JULogger warn
警告: Transaction failed and will be retried in 19175ms
八月 23, 2019 12:18:06 下午 org.neo4j.driver.internal.logging.JULogger warn
警告: Transaction failed and will be retried in 28022ms
八月 23, 2019 12:18:37 下午 org.neo4j.driver.internal.logging.JULogger warn
警告: Transaction failed and will be retried in 71794ms
....
八月 23, 2019 12:19:49 下午 org.neo4j.driver.internal.logging.JULogger info
信息: Routing table is stale. Ttl 1566534216286, currentTime 1566533989107, routers AddressSet=[59.111.222.81:7787, 59.111.222.81:7887], writers AddressSet=[], readers AddressSet=[59.111.222.81:7887, 59.111.222.81:7787, 59.111.222.81:7987]
八月 23, 2019 12:19:49 下午 org.neo4j.driver.internal.logging.JULogger info
信息: Updated routing table. Ttl 1566534289125, currentTime 1566533989126, routers AddressSet=[59.111.222.81:7787, 59.111.222.81:7887, 59.111.222.81:7687], writers AddressSet=[59.111.222.81:7887], readers AddressSet=[59.111.222.81:7787, 59.111.222.81:7987, 59.111.222.81:7687]可以看到,进行了更多次重试,直到发现新leader产生后,更新了集群的路由表信息。继续执行事务。所以,大家在使用过程中,一定要注意超时的问题。
总结
本文主要是针对neo4j集群行为和如何正确使用neo4j集群做了一些说明。包括集群的搭建,集群故障切换和恢复行为。已经用户在使用neo4j集群时需要注意的驱动端配置。
