点击上方蓝字,和我一起学技术。

线性代数是机器学习领域当中非常重要的基础知识,但是很遗憾的是,在真正入门之前很少有人能认识到它的重要性,将它学习扎实,在入门之后,再认识到想要补课也不容易。
我自己也是一样,大学期间只是浅尝辄止,这门课考试成绩还可以,但是过后记住的内容不多。导致后来在看很多论文以及资料的时候,很吃力,很多公式很难看懂,即使看懂了也很容易忘记。
线性代数的内容不少,许多非常精深,这里我们只提炼关键的知识点。没学过的同学可以很容易get到精髓,学过的同学也可以当做复习。
行列式定义
维基百科中的定义是,行列式是一个函数,将一个n * n的矩阵映射到一个标量。这个标量表示经过这个矩阵所代表的的线性变幻之后,矩阵的“体积”在空间当中发生的变化。
也就是说,行列式的输入是一个n * n的方阵,输出是一个具体的数。我们把行列式用det来表示,假设A是某一个n * n的矩阵,那么det(A)即表示该矩阵的行列式。
行列式计算
二阶行列式
令

那么,
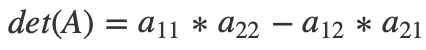
即为对角线乘积的差。
再来看三阶的情况:
令
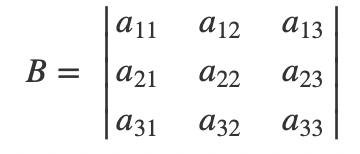
那么
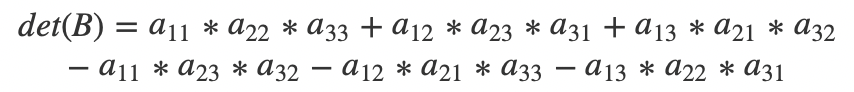
光看公式非常复杂,如果我们把所有正项的乘积用红线相连,把负项的成绩用蓝线相连,那么我们可以得到下面这张图。
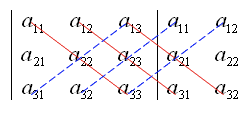
其实本质上来说,还是对角线的乘积差,即所有正向(从左上往右下)对角线的乘积和减去反向(从右上往左下)对角线的乘积和。
我们列出了二项以及三项行列式的式子,自然而然,我们下面就要写出n项行列式的计算方法。但在此之前,我们先要引入另外一个相关的概念——逆序数。
逆序数
逆序数本身主要就是应用在行列式的计算当中,不过除此之外在面试题当中经常出现,许多面试题会让求职者写出或口述逆序数的计算算法。关于这点,会在之后的算法专栏当中单独讲解。
假设我们有一个数组A,它当中有n个各不相同的元素。在理想情况下,A当中的元素应该都是有序的。比如说都是从小到大排列,但理想情况很少发生。大多数情况下,数组当中的元素都是无序的。
假如我们想要知道,数组当前的排序距离理想情况的升序究竟有多大的差距。很正常地可以想到,我们可以遍历这个数组当中所有Ai和Aj的组合,看看究竟有多少数的次序有误。在这个序列所有两两元素的组合当中,有误的次序的组合总数就叫做逆序数。
光看概念有些拗口,但是直接看代码的话其实非常简单:
reverse = 0for i in range(n):for j in range(i):if A[i] < A[j]:reverse += 1
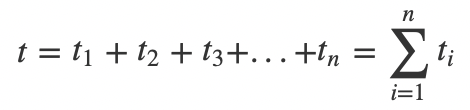
n阶行列式
我们再回到n阶行列式来,理解了逆序数的概念之后,我们就很方便地可以写出n阶行列式的公式了。首先,先定义出矩阵D,是一个n阶的方阵:
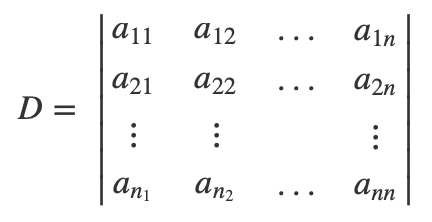
假设自然数
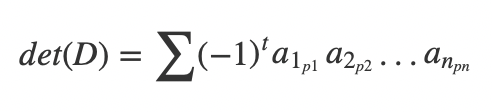
由于长度为n的序列的全排列一共有
除此之外,行列式还有另外一种计算方法。
在n阶行列式当中,把

其中(2,2)元的代数余子式为:

代数余子式可以用来表示行列式。
A矩阵的行列式可以写成
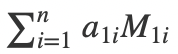
证明也很简单,其实这只不过是行列式表达式的一个变形。我们用三阶行列式举例:
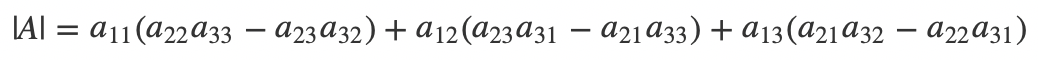
我们把这些值用代数余子式表示出来:
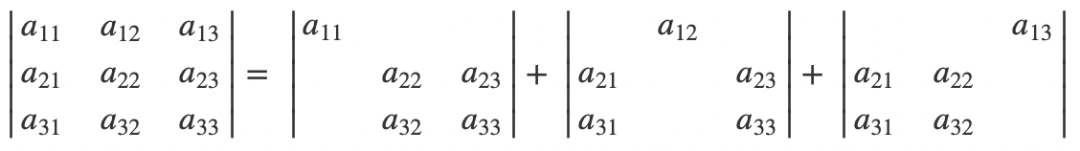
化简一下,显然就是上面公式的结果。
克拉默法则
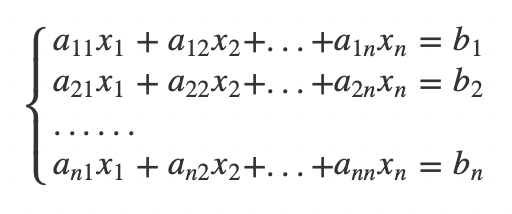
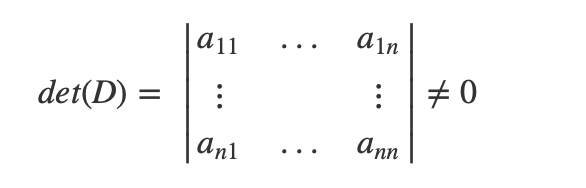
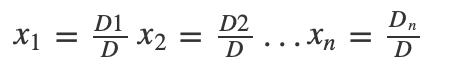
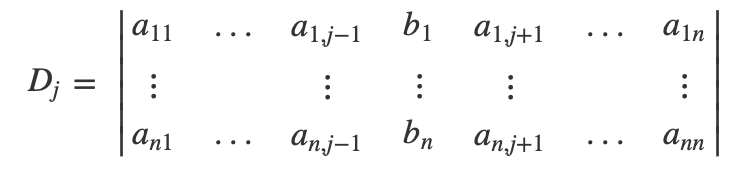
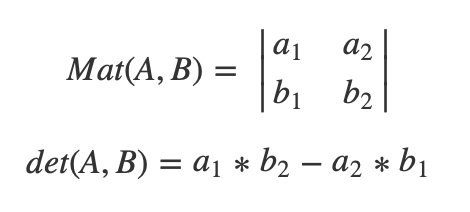
pip install numpy