
kafka多牛啊,老少通吃,风光无限,从业务服务到大数据,无所不能。
但,即使它这么牛x,在不少项目中,依然能看到很多的替代品,比如RabbitMQ、RocketMQ、Pulsar等。
等等,先不说这些同质的竞争品。在我见到的很多项目里,经常有一只乱入的消息队列,那就是Redis。还别说,使用还挺广泛的。
是他们傻?还是单纯的水平不够?

Redis很强
因为Kafka的对手是Redis!
redis很强,满身的肌肉,几乎是的。如果你的内存足够大,你甚至可以把所有的数据放到内存中。
除了常见的5种常见的数据结构,Redis还支持非常多的扩展数据结构,其中就有“借鉴”Kafka所实现的Stream类型。
Stream就是低配版的Kafka,有Kafka经验的,玩起它来自然不在话下。相对于比较老旧的LPUSH/BRPOP、PUB/SUB模式,Stream在这个场景中完胜。
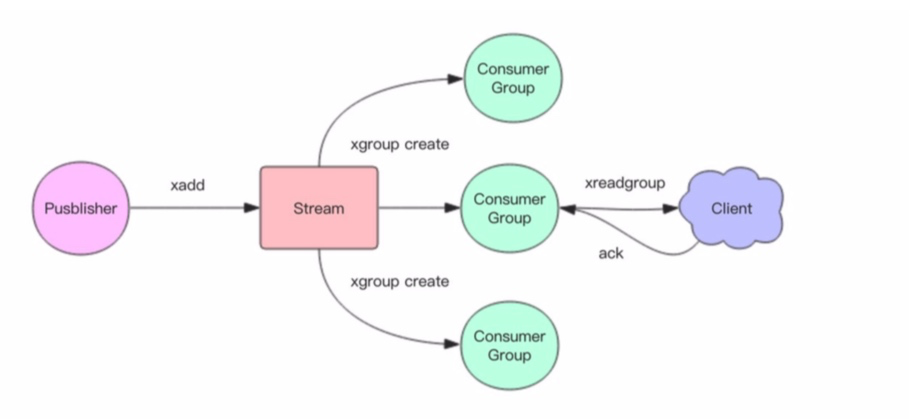
可以看到,Streamn的生产消费模式,几乎和Kafka是一个模子出来的,竟然还有消费组的概念。但Stream并没有Partition的概念,所以它是个低配版的Kafka。
我们来看看官网的说明。
Consumer groups were initially introduced by the popular messaging system Kafka (TM). Redis reimplements a similar idea in completely different terms, but the goal is the same: to allow a group of clients to cooperate in consuming a different portion of the same stream of messages.
Redis Can up
在很多软件开发中,尤其是把软件部署到甲方的机器上,引入一个新的组件,成本是巨大的。这方面,众多外包和OD们应该比较清楚它的凶残。
对于这类系统,甚至是发展势头还不错的中小公司来说,对于消息的需求并没有那么大的要求。与其引入一个新的Kafka组件,不如直接用项目中所存在的Redis组件来完成工作。
我们还是来回顾一下消息队列的作用。
削峰 用于承接超出业务系统处理能力的请求,使业务平稳运行。这能够大量节约成本,比如某些秒杀活动,并不是针对峰值设计容量。 缓冲 在服务层和缓慢的落地层作为缓冲层存在,作用与削峰类似,但主要用于服务内数据流转。比如批量短信发送。 解耦 项目尹始,并不能确定具体需求。消息队列可以作为一个接口层,解耦重要的业务流程。只需要遵守约定,针对数据编程即可获取扩展能力。 冗余 消息数据能够采用一对多的方式,供多个毫无关联的业务使用。 健壮性 消息队列可以堆积请求,所以消费端业务即使短时间死掉,也不会影响主要业务的正常进行。
不好意思,除了内存容量小一点,上面说的这些需求,Redis的Stream全部能够完成,包括对于缓存系统来说比较难得的持久化,它一样支持。
那还犹豫个毛!怎么简单怎么玩!
还有好处
Kafka为了增加吞吐量,可以说用尽了心思。比如,使用Filesystem Cache PageCache缓存来减少与磁盘的交互;使用顺序写来增加写入的吞吐量;使用Zero-copy和MMAP来减少内存交换;使用批量,以流的方式进行交互,直顶网卡上限;使用拉模式进行消息的获取消费,与消费端处理能力相符。
这么一优化下来,虽然功能很强大,但同时膨胀的还有代码加上软件的体积。
对于Redis来说,领域就在内存里玩,不需要这么多花架子就可以达到比Kafka更高的速度。就连partition这个特性,也可以使用不同的Key划分来实现,性能自然是比Kafka高的。
再一个,就是使用简单。
比如XADD指令、XLEN、XRANGE、XREAD等,指令少且好理解,远比Kafka使用简单。
这些优点一汇聚,就不能抵挡它成为MQ中的香馍馍。
End
简单、够用好维护,这么多优点,为什么不选Redis呢?给客户上个又笨又重的Kafka、Pulsar,来给自己添麻烦,何必呢?
当然,以上的评价是对于外包、项目类公司来说的。如果你的公司产品是持续迭代的,持续优化的,又有量,一次性到位选择成熟的额消息队列才是正确的选择。
所以,把Redis的Stream用在正确的项目,正确的地方的人,根本就不傻,他们大智若愚,堪负重任!
