本期作者

王翔宇
哔哩哔哩开发工程师
2017年加入B站,现服务于基础架构实时团队。先后负责B站日志系统、实时流式传输工作。
魏泽丰
哔哩哔哩开发工程师
2021年加入B站,现服务于基础架构实时团队,负责实时流式传输以及Flink CDC相关工作。


高瑞超
哔哩哔哩开发工程师
2021年加入B站,现服务于基础架构实时团队,负责实时流式传输以及Flink connector相关工作。
01 背景
Lancer是B站的实时流式传输平台,承载全站服务端、客户端的数据上报/采集、传输、集成工作,秒级延迟,作为数仓入口是B站数据平台的生命线。目前每日峰值 5000w/s rps, 3PB/天, 4K+条流的数据同步能力。

服务如此大的数据规模,对产品的可靠性、可扩展性和可维护性提出了很高的要求。流式传输的实现是一个很有挑战的事情,聚焦快、准、稳的需求, Lancer整体演进经历了大管道模型、BU粒度管道模型、单流单作业模型三个阶段的演进,下面我们娓娓道来。
02 关键词说明
logid:每个业务方上报的数据流以logid进行标识,logid是数据在传输+集成过程中的元信息标识。
数据源:数据进入到lancer的入口,例如:log-agent,bfe-agent,flink cdc
lancer-gateway(数据网关):接收数据上报的网关。
数据缓冲层:也叫做内部kafka,用于解耦数据上报和数据分发。
lancer-collector(数据分发层):也叫做数据同步,可以根据实际场景完成不同端到端的数据同步。
03 技术演进
整个B站流式数据传输架构的演进大致经历了三个阶段。
3.1 架构V1.0-基于flume的
大管道数据传输架构(2019之前)
B站流式传输架构建立之初,数据流量和数据流条数相对较少,因此采用了全站的数据流混合在一个管道中进行处理,基于flume二次定制化的数据传输架构,架构如下:

整个架构从数据生成到落地分为:数据源、数据网关、数据缓冲、数据分发层。
数据上报端基本采用sdk的方式直接发送http和grpc请求上报。
数据网关lancer-gateway是基于flume二次迭代的数据网关,用于承载数据的上报,支持两种协议:http用于承载公网数据上报(web/app),grpc用于承载IDC内服务端数据上报。
数据缓冲层使用kafka实现,用于解耦数据上报和数据分发。
数据分发层lancer-collector同样是基于flume二次迭代的数据分发层,用于将数据从缓冲层同步到ODS。
v1.0架构在使用中暴露出一些的痛点:
1. 数据源端对于数据上报的可控性和容错性较差,例如:
数据网关故障情况下,数据源端缺少缓存能力,不能直接反压,存在数据丢失隐患。
-
重SDK:SDK中需要添加各种适配逻辑以应对上报异常情况
2. 整体架构是一个大管道模型,资源的划分和隔离不明确,整体维护成本高,自身故障隔离性差。
3. 基于flume二次迭代的一些缺陷:
逻辑复杂,性能差,我们需要的功能相对单一
hdfs分发场景,不支持exactly once语义,每次重启,会导致数据大量重复
3.2 架构V2.0-BU粒度的
管道化架构(2020-2021)
针对v1.0的缺陷,我们引入了架构v2.0,架构如下:
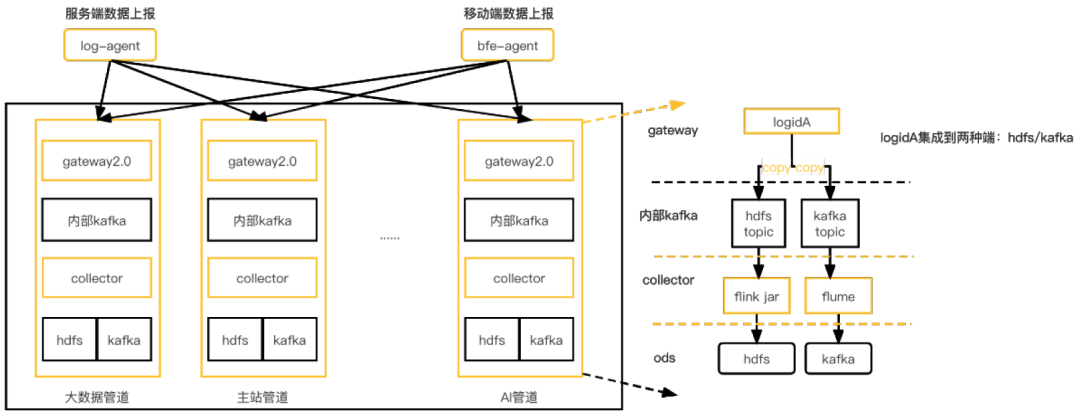
此架构的关键细节如下:
1. 强化了数据上报源端的边缘可控能力
服务器上部署log-agent承载服务端数据上报。
cdn上部署bfe-agent用于承载公网(web端、app端)数据上报。
log-agent/bfe-agent中集成数据缓冲、预聚合、流控、重试、降级等能力,数据上报sdk只需专注数据的生成和上报逻辑。
agent端基于logid的BU属性,将数据路由到不同的管道。
2. 数据管道以BU为粒度搭建,管道间资源隔离,每个管道包含整套独立的完整数据传输链路,并且数据管道支持基于airflow快速搭建。故障隔离做到BU级别。
3. 数据网关升级到自研lancer-gateway2.0,逻辑精简,支持流控反压,并且适配kafka failover, 基于k8s进行部署。
4. hdfs分发基于flink jar进行实现:支持exactly once语义保证。
V2.0架构相对于v1.0, 重点提升了数据上报边缘的可控力、BU粒度管道间的资源划分和隔离性。但是随着B站流式数据传输规模的快速增加,对数据传输的时效性、成本、质量也提出了越来越高的要求,V2.0也逐渐暴露出了一些缺陷:
1. logid级别隔离性差:
单个管道内部某个logid流量陡增,几倍甚至几十倍,依然会造成整个管道的数据分发延迟,
单个管道内分发层组件故障重启,例如:hdfs分发对应的flink jar作业挂掉重启,从checkpoint恢复,此管道内所有的logid的hdfs分发都会存在归档延迟隐患。
2. 网关是异步发送模型,极端情况下(组件崩溃),存在数据丢失风险。
3. ods层局部热点/故障影响放大
由于分发层一个作业同时分发多个logid,这种大作业模型更易受到ods层局部热点的影响,例如:hdfs某个datanode热点,会导致某个分发作业整体写阻塞,进而影响到此分发作业的其他logid, kafka分发同理。
hdfs单个文件块的所有副本失效,会导致对应分发任务整体挂掉重启。
4. hdfs小文件问题放大
hdfs分发对应的flink jar作业为了保证吞吐,整体设置的并发度相对较大。因此对于管道内的所有logid,同一时刻都会打开并发度大小的文件数,对于流量低的logid,就会造成小文件数量变大的问题。
针对上述痛点,直接的解决思路就是整体架构做进一步的隔离,以单logid为维度实现数据传输+分发。面临的挑战主要有以下几个方面:
如何保证全链路以logid为单位进行隔离,如何在资源使用可控的情况下合理控流并且保证数据流之间的隔离性
需要与外部系统进行大量的交互,如何适配外部系统的各种问题:局部热点、故障
集成作业的数量指数级增加,如何保障高性能、稳定性的同时并且高效的进行管理、运维、质量监控。
3.3 架构V3.0-基于Flink SQL的
单流单作业数据集成方案
在V3.0架构中,我们对整体传输链路进行了单作业单数据流隔离改造,并且基于Flink SQL支撑数据分发场景。架构如下:

相比v2.0, 资源池容量管理上依然以BU为粒度,但是每个logid的传输和分发相互独立,互不影响。具体逻辑如下 :
agent:整体上报SDK和agent接收+发送逻辑按照logid进行隔离改造,logid间采集发送相互隔离。
lancer-gateway3.0:logid的请求处理之间相互隔离,当kafka发送受阻,直接反压给agent端,下面详细介绍。
数据缓冲层:每个logid对应一个独立的内部kafka topic,实现数据的缓冲。
数据分发层:分发层对每个logid的启动独立的flink sql作业进行数据的分发,单个logid处理受阻,只会导致当个logid的数据堆积。
相较于之前的实现,v3.0架构具有以下的优势:
1. 可靠性:
功能质量上整理链路可以保证数据不丢失,网关层以同步方式发送数据,可以保证数据被持久化到内部kafka;flink支持状态恢复和exactly once的语义,同样保证数据不丢。
2. 可维护性上:
隔离性上logid之间相互隔离,一个logid出现问题,其他logid不受影响。
资源分配以logid为小单位,可以控制单个logid的资源使用。
3. 可扩展性:
可以以单个logid为单位灵活管控:灵活的扩缩资源
04 V3.0架构具体实现
我们重点介绍下,当前V3.0结构各个分层的实现。
4.1 数据上报边缘层
4.1.1 log-agent
基于go自研,插件化架构,部署于物理机,可靠、高效的支持服务端数据上报。

时间架构分为收集、处理、发送三层,具有以下主要特性:
支持文件采集和unix sock两种数据上报方式
与网关GRPC通信:ACK+退避重试+流控
整体上报SDK和agent接收+发送逻辑按照logid进行隔离改造,单logid处理相互隔离:每个logid启动独立的pipeline进行采集、解析、发送。
网关基于服务发现,自适应网关的调整
发送受阻情况下,基于磁盘进行本地堆积
logid粒度的埋点监控,实时监控数据的处理状态
CGroup资源限制:CPU + 内存
数据聚合发送,提升传输效率
支持物理机和容器日志此采集,配置随应用发布,自适应配置的增、删、改。
4.1.2 bfe-agent
基于go自研,部署于cdn,用于承载公网数据上报。
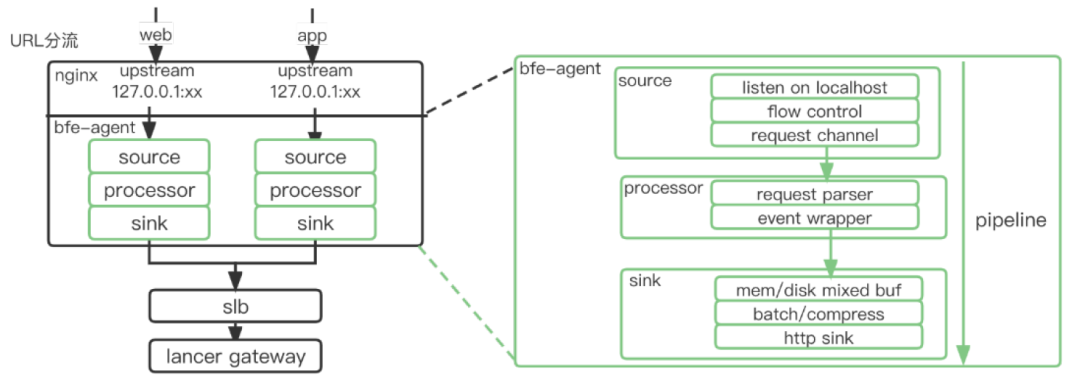
边缘cdn节点,cdn服务器上部署nginx和bfe-agent,bfe-agent整体实现架构与log-agent类似,对于web和app端数据上报请求QPS高、突发性强的特点,主要强化了以下能力:
应对流量陡增:基于边缘节点的本地缓冲起到削峰作用
策略(降级、流控)前置,增强可控力
logid级别分流隔离, 支持等级划分
聚合压缩回传以提升数据传输效率、降低成本,回源QPS降低90%以上。
4.2 数据上报网关层
v3.0方案中,数据数据网关的架构如下:

数据网关功能特性如下:
kafka的通用代理层:支持grpc /http协议
基于kafka send callback实现了同步发送模型,保证数据不丢:数据写入kafka后,再对请求返回ack
请求不拆分:基于agent的聚合机制,只支持单次请求单条记录,因此一条记录对应一条缓存层kakfa的消息
lancer-gateway3.0根据请求的topic信息,发送请求到对应的kafka集群
lancer-gateway3.0适配kafka集群的局部热点:支持partition动态剔除
logid与topic一一对应,处理流程中相互隔离:一个topic发送受阻,不影响其他的topic
整个数据网关中的实现难点是:单gateway承载多logid处理的过程中如何保证隔离性和公平性,我们参考了Golang 中GMP的机制,整体数据流程如下:

1. 收到的请求,会把请求放到logid对应的请求队列,如果队列满,直接拒绝请求
2. 每个kafka集群,会初始化一个N大小的kafka producer pool,其中每个producer会遍历所有的队列,进行数据的发送。
3. 对于每个logid的请求队列,会从两个维护限制资源的占用,以保证公平性和隔离性
限制当个logid队列绑定的producer数量
基于时间片限定当个producer服务于单个队列的时间长度
4.3 数据上报分发层
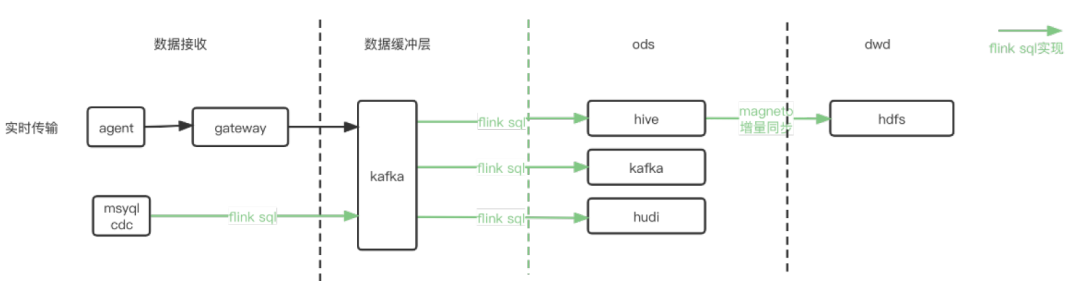
随着flink在实时计算领域的成熟,其高性能、低延迟、exactly once语义保证、批流一体、丰富的数据源支持、活跃的社区等优势,促使我们选择了以flink sql作为数据分发层的解决方案。当前我们主要支持了kafka→hive, kafka→kafka, cdc→kafka->hudi/hive三种场景:
1. kafka→hive
以流式方式,实时导入数据到hive。
file rolling on check,保证exactly once。
按照event time写入分区和归档,归档延迟小于15min
支持text+lzo(行存)和 orc+zstd(列存)两种存储格式。
支持下游作业增量同步。
2. kafka→kafka
以流式方式,支持数据的实时同步
支持kafka header metadata信息的透传
3. cdc→kafka->hudi/hive
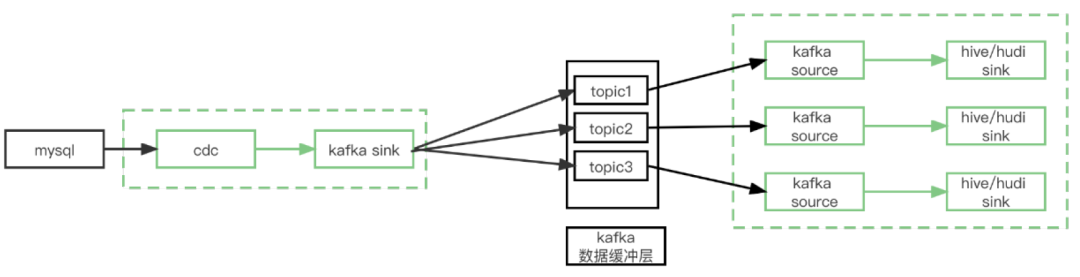
以实时流的方式同步全量和增量数据,整个cdc的使用场景分为两个环节
cdc → kafka
基于cdc 2.1,同步mysql的全量和增量binlog同步
单sql作业支持分库分表、多库多表的同步。
支持根据db和table自定义策略分流到不同的数据缓冲层kafka topic
kafka→hudi/hive
消费单topic同步到单张hudi/hive表,支持event_time落分区。
保证数据终一致性
05 Flink connector功能迭代
在Flink SQL数据分发场景的支持中,针对我们遇到的实际需求,对社区原生connector进行了对应的优化,我们针对性的介绍下。
5.1 hive sink connector优化
断流空分区提交
背景:B站离线作业的拉起依赖上游分区提交,HDFS分区提交的判断依赖于作业整体watermark的推进,但是某些logid在断流的情况下,如何进行分区的提交呢
解决办法:

如图所示:当所有的StreamFileWriter连续两次checkpoint内未处理任何数据的情况下,StreamingFileCommiter会判定发生了断流,按照当前时间提交分区。
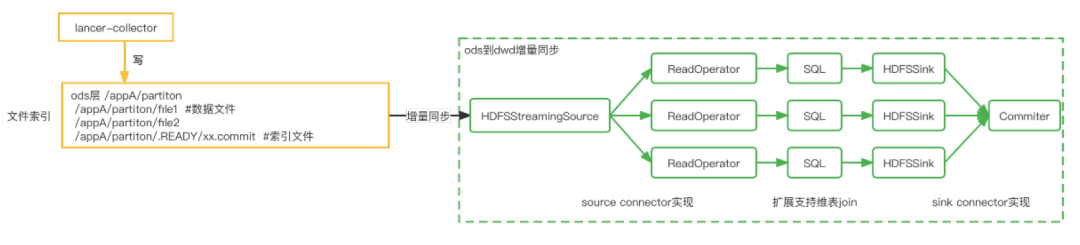
支持下游增量数据同步
背景:传统方式ods到dwd的数据同步只有当ods层分区ready之后才会开始,时效性较差,如何加速数据的同步?
解决办法:
不依赖ods层分区ready,当ods目录中文件生成后,即可开始数据的处理,以增量的方式读取数据文件。
通过HDFS的list操作来获取需要读取的文件,对NameNode压力较大,为此我们提供了文件list列表索引(包括文件名和数据条数),下游只需要读取索引,即可获取增量文件列表。
实现中索引文件状态被持久化到state中,snapshot中生成.inflight状态临时文件,notifyCheckpointComplete中将文件rename成commit正式文件, 提供exactly once语义保证。
下游作业读取文件索引,支持ods到dwd的增量数据同步。

orc+zstd
背景:相较于行式存储,列式存储在压缩比上有着显著的优势。
解决办法:支持orc+zstd, 经过测试,相较于text+lzo,空间节省在40%以上。
hdfs异步close
背景:snapshot阶段flush数据,close文件经常因为个别文件慢拖累整体吞吐。
解决办法:
将close超时的文件扔到异步队列中。也就是 close 的动作不会去堵塞整个主链路的处理,提升hdfs局部热点情况下的吞吐。异步close 文件列表保存到pendingPartsForCurrentCheckpoint,并且持久化到 state 当中。故障恢复时,也能继续对文件进行关闭。
异步close的引入,会引入分区提前创建的隐患,为此引入了对于bucket状态的判断。对于某分区,只有当隶属于此分区的所有bucket中的pendingPartsForCurrentCheckpoint为空(所有文件都进行了关闭),才在commit算子中进行分区的提交。
小文件合并
背景:rolling on checkpoint的滚动策略,会导致文件数量的膨胀,对namenode产生较大的压力。
解决办法:

引入了小文件合并功能,在checkpoint完成后,由 Streaming writer 的 notifyCheckpointComplete 方法触发合并操作,向下游发送EndCheckpoint信号。
coordinator 收到每个writer的EndCheckpoint后,开始进行文件的分组,封装成一个个compactunit广播下游,全部unit发送完之后,再广播EndCompaction。
compact operator找到属于自己的任务后开始处理,当收到EndCompaction后,往下游发送分区提交信息。
5.2 kafka connector优化
支持protobuf format
背景:用户有处理protobuf格式数据的需求
解决办法:
使用protoc 生成java类,打包jar,上传到实时计算平台。
实现对应的DeserializationSchema和SerializationSchema,动态加载pb类并通过反射调用方法,完成pb bytes与RowData的互转。
kafka sink支持自定义分流
背景:用户希望在一个sql作业中根据需要,灵活定制将消息发送到指定kafka 集群和topic。
解决办法:
支持用户自定义udf,灵活选择sql中的字段作为udf的入参,在udf内部,用户根据业务场景定制逻辑,返回topic或者broker list。终sink内部发送到对应的kafka集群和topic。
kakfa sink内部动态加载udf,通过反射机制实时获取对应的broker和topic,同时支持结果的缓存。
例子:
CREATE TABLE sink_test (broker_name_arg varchar,topic_name_arg varchar,message string,t1 string) WITH('bootstrapServers' = 'BrokerUdf(broker_name_arg)', // 根据broker_name_arg作为udf参数计算brokers'bootstrapServers.udf.class' = 'com.bilibili.lancer.udf.BrokerUdf', // 获取brokers Udf'topic' = 'TopicUdf(broker_name_arg, topic_name_arg)', // 根据broker_name_arg和topic_name_arg作为udf参数计算topic'topic.udf.class' = 'com.bilibili.lancer.udf.TopicUdf', // 计算topoc Udf'udf.cache.min' = '1', // 缓存时间'exclude.udf.field' = 'false', // udf的相关字段是否输出'connector' = 'kafka-diversion');
5.3 cdc connector优化
sql场景下多库多表场景支持
背景:原生的flink cdc source在单个sql任务中,只能同步相同DDL定义的表,如果需要同步异构DDL,不得不启动多个独立的job进行同步。这样会存在资源的额外开销。
解决办法:
-
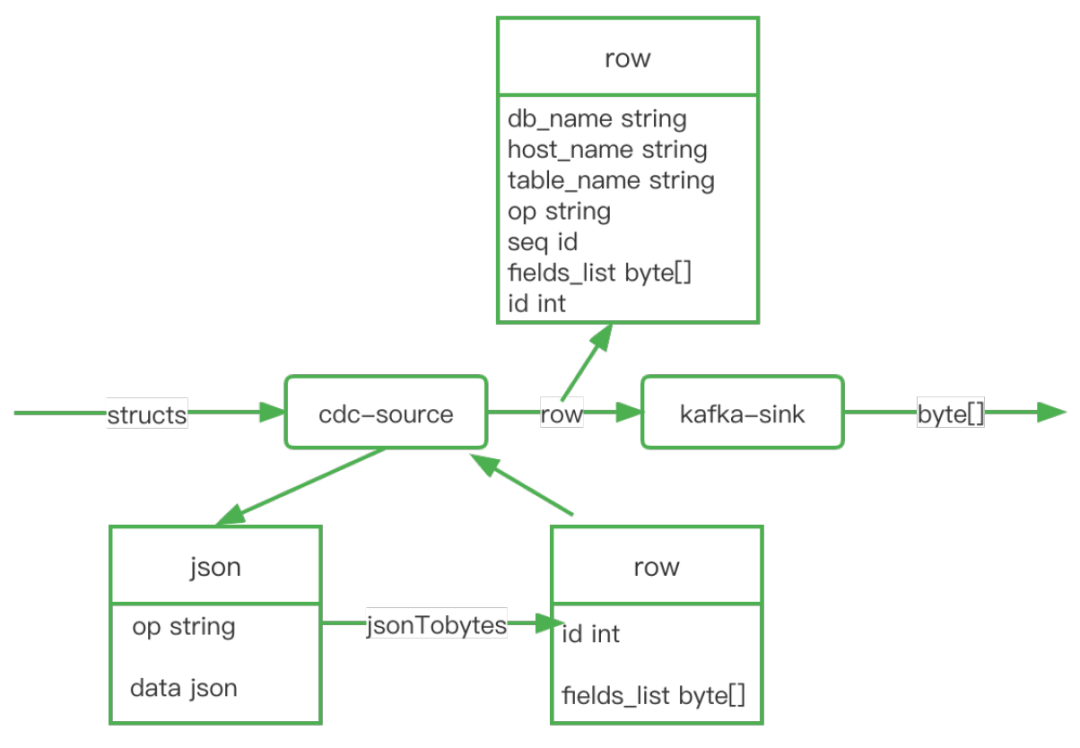
sql定义去DDL:
原生flink cdc source会对所有监听到的数据在反序列化时根据sql ddl定义做column转换和解析,以RowData的形式传给下游。我们在cdc-source中新增了一种的format方式:changelog bytes序列化方式。该format在将数据反序列化时在不再进行column转换和解析,而是将所有column直接转换为changelog-json二进制传输,外层将该二进制数据直接封装成RowData再传给下游。对下游透明,下游在消费kafka数据的时候可以直接通过changelog-json反序列化进行数据解析。并且由于该改动减少了一次column的转换和解析工作,通过实际测试下来发现除自动感知schema变更外还能提升1倍的吞。在kafka sink connector中,根据db和table进行分流,可以支持发送到不同的topic。
-
扩展metadata,添加sequence:
将增量数据同步到kafka中,由于kafka存在多分区,因此必然会导致消息乱序问题。因此需要提供一个单任务内严格单调递增的sequence,用于下游消费者进行排序,保证数据的终一致性。终我们提取binlog中的gtid作为binlog消息的sequence id,通过metadata的方式暴露处理来,写入kafka record的header中,对于全量数据,sequence设置为0。
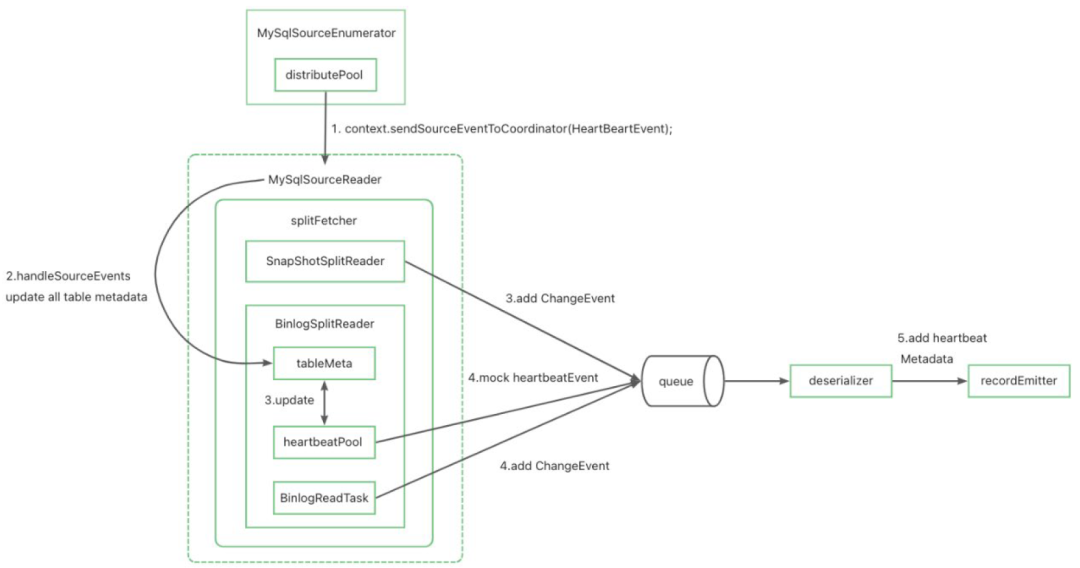
断流场景分区提交支持
背景:由于整个cdc方案存在上游和下游两个独立的job,并且都是基于event time推进watermark做分区的提交,下游watermark的推进受阻可能受到数据正常断流或者上游作业异常两种原因的影响,如果正确判断呢?
解决办法:
在cdc source connector内定义一种新类型的record HeartbeatRecord,此record时间为当前时间。当发现某张表数据停止发送时,定期mock心跳数据进行发送。正常断流情况下,下游作业可以根据心跳信息正常推进watermark,并且可以过滤丢弃此信息。
终cdc connector sql样例:
CREATE TABLE mysql_binlog (host_name STRING METADATA FROM 'host_name' VIRTUAL,db_name STRING METADATA FROM 'database_name' VIRTUAL,table_name STRING METADATA FROM 'table_name' VIRTUAL,operation_ts TIMESTAMP(3) METADATA FROM 'op_ts' VIRTUAL,sequence BIGINT METADATA FROM 'sequence' VIRTUAL, // sequence严格单调递增heartbeat BOOLEAN METADATA FROM 'heartbeat'VIRTUAL, // 对于心跳信息标识为truemtime TIMESTAMP(3) METADATA FROM 'mtime'VIRTUAL, // 提取mtime,用于下游推进watermarkid BIGINT NOT NULL,filed_list BYTES NOT NULL, // 去DDL,在source内部数据全部按照changelog-json格式进行序列化、PRIMARY KEY(id) NOT ENFORCED) WITH ('connector' = 'mysql-cdc','hostname' = 'xxxx','port' = '3552','username' = 'datacenter_cdc','password' = 'xxx','database-name' = 'xxx','debezium.format' = 'bytes','table-name' = 'xxx','server-time-zone' = 'Asia/Shanghai','heartbeat.enable'='true','scan.incremental.snapshot.chunk.size' = '80960');
06 架构稳定性优化
为了保障流式传输稳定和高效运行,我们在以下几个方面做了一些优化,分别介绍下:
6.1 管道热点优化
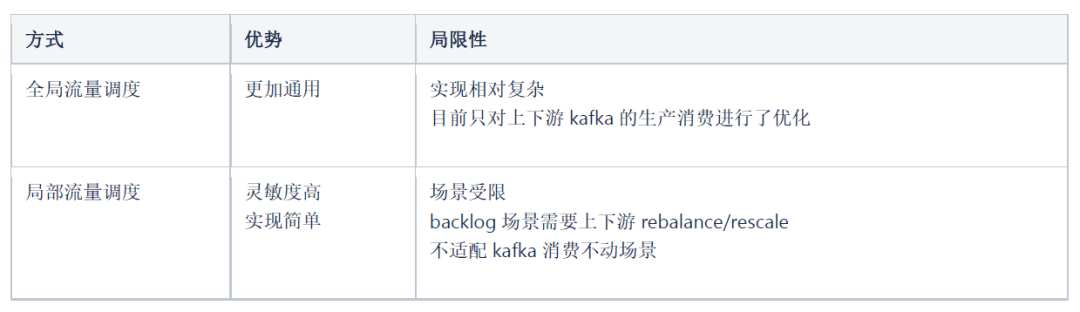
作业在正常运行的过程中,经常遇到局部热点问题,例如kafka/hdfs io热点导致局部并行度消费速度下降或者写入受阻、yarn队列机器load不均匀导致作业部分并行度消费能力不如,虽然原因多种多样,但是本质看,这些问题的一个共性就是由于局部热点导致局部数据延迟。针对这个问题,我们分别从局部流量调度和全局流量调度两个维度进行优化。
局部流量调度
局部流量调度的优化思路是在单个producer和task内部,分区之间进行流量的重分配。目前在两个点就行了优化:
-
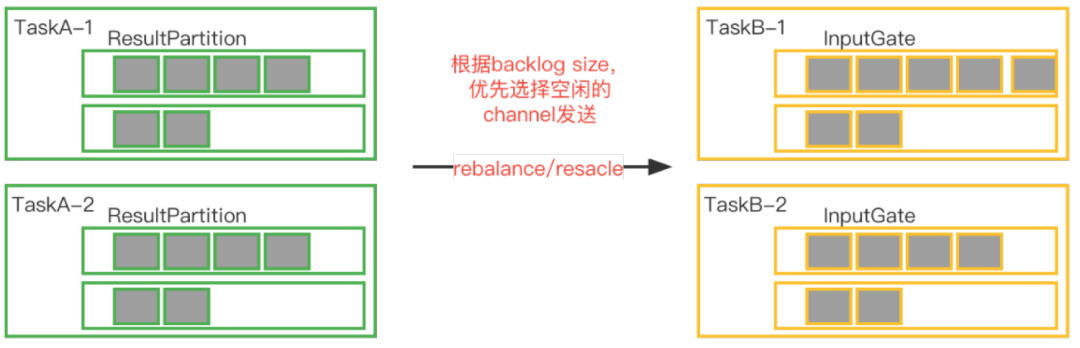
bsql Task manager内部subtask上下游通信优化:
集成作业并没有keyby的需求,基于Flink Credit-based Flow Control反压机制,可以通过Backlog Size判断下游任务的处理负载,那么我们就可以将Round-robin发送的方式修改为根据Channel的Backlog Size信息选择负载更低的下游Channel发送的方式。注意:此种策略只有source和sink端之间是rebalance/rescale时,才有效果。会造成一定的序列化开销,但是测试下来可以接受。
-
kafka producer partition自动剔除机制:
kafka producer在发送数据callback异常(绝大多数是timeout)超出一定的阈值,会将对应tp从available partition list中进行剔除,后续record将不再发送到剔除的tp。同时,被剔除tp后续将进行恢复性测试,如果数据可以正常发送,将重新放入到available partition list中。目前此机制在flink kafka sink connector和标准kafka client都进行了实现。
全局流量调度
全局流量调度的优化思路是整个传输链路层级之间的流量调配,目前我们将生产者(lancer-gateway)与消费者(flink sql kafka source)进行联动,当消费者出现tp消费lag的情况,通过注册黑名单(lag partition)到zookeeper,上游生产者感知黑名单,停止向高lag partition中继续发送数据。

Flink kafka source中基于flink AggregateFunction机制,kafka source subtask上报lag到job manager,job manager基于全局lag判断注册黑名单到zookeeper
黑名单判断逻辑:当单tp lag > min(全局lag平均值,全局lag中位数)* 倍数 && 单tp lag 大于 lag值, 其中 "单tp lag 大于 lag值" 是为了规避此机制过于敏感,"单tp lag > min(全局lag平均值,全局lag中位数)* 倍数" 用于筛选出头部的lag tp。为了防止黑名单比例过大,黑名单剔除的tp数量上限不得大于全部tp数量的一定比例。
局部流量调度和全局流量调度在管道热点优化效果上存在一定的互补性,但是也各有优势。
6.2 全链路埋点质量监控
数据质量是重要一环,通常数据质量包含完整性、时效性、准确性、一致性、性等方面,对于数据传输场景,当面我们重点关注完整性和时效性两个方面

整体质量方案大致包含监控数据采集和规则配置两个大的方向,整体架构如下:

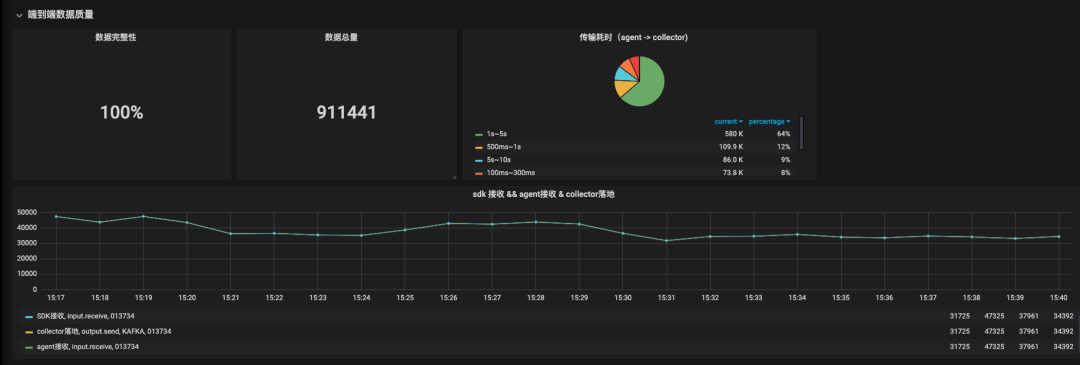
监控数据采集
我们自研了trace系统:以logid为单位,我们在数据处理流程中的每一层都进行了监控埋点
每层埋点包含三个方面:接收、发送、内部错误。所有埋点数据以数据创建时间(ctime)进行窗口对齐,并且通过更新utime以统计层间和层内的处理耗时。
通过监控埋点可以实时统计出:端到端、层级间、层级内部的数据处理耗时、完整性、错误数。
当前方案缺陷:flink sql挂掉从ck恢复,监控数据不能保证幂等,后续需要进一步改进。
监控报警规则
我们针对数据流进行了分级,每个等级指定了不同的保障级别(SLA),SLA破线,报警通知oncall同学处理。
延迟归档报警:hdfs分区提交延迟,触发报警。
实时完整性监控:基于trace数据,实时监控端到端的完整性,接收条数/落地条数
离线数据完整性:hdfs分区ready后,触发dqc规则运行,对比接收条数(trace数据)/落地条数(hive查询条数)
传输延迟监控:基于trace数据,计算端到端数据传输延迟的分位数。
DQC阻塞:离线数据完整性异常后,阻塞下游作业的调度。
6.3 kafka同步断流重复优化
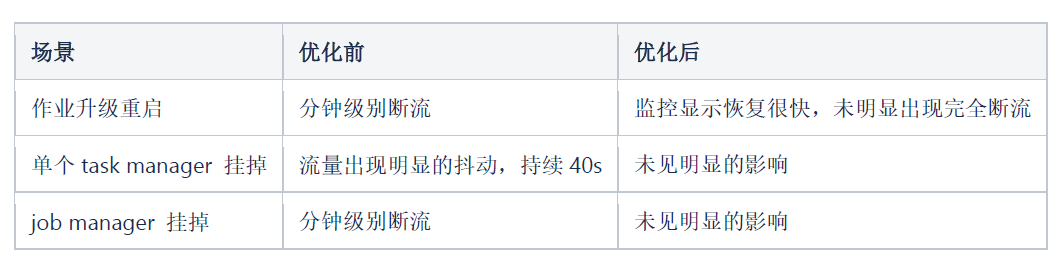
相对比2.0方案中flume方案,基于flink sql的kafka到kafka的实现方案明显的一个变化就是作业的重启、故障恢复会导致整体的断流和一定比例的数据重复(从checkpoint恢复),因此如何降低用户对此类问题的感知,至关重要。
首先梳理下可能造成问题出现的原因:1)作业升级重启 2)task manager故障 3)job manager 故障 4)checkpoint连续失败,同时根据flink job整体提交流程,影响作业恢复速度的关键环节是资源的申请。根据上述分析和针对性测试,针对kafka同步场景的断流重复采用了如下优化方式:
checkpoint interval设置成10s:降低从checkpoint恢复导致的数据重复比例
基于session模式提交作业:作业重启无需重复申请资源
jobmanager.execution.failover-strategy=region,单个tm挂掉后,只恢复对应的region,不用恢复整个作业。集成作业DAG相对简单,可以尽量规避rebalance的出现,降低恢复的比例。
使用小资源粒度task manager(2core cpu,8GB memory,2 slot):同等资源规模下,tm数量变多,单tm挂掉影响程度明显变低。
针对高优作业冗余task manager:冗余一个tm,当单个tm挂掉情况下,流量几乎没受影响
基于zookeeper实现job manager ha:在开启jm ha后,jm挂掉任务未断流
针对checkpoint连续失败的场景,我们引入了regional checkpoint,以region(而不是整个topology)作为checkpoint管理的单位,防止个别task的ck失败造成整个作业的失败,可以有效防止在个别task的ck连续失败的情况下需要回溯的数据量,减小集群波动(网络,HDFS IO等)对checkpoint的影响
经过上述优化,经过测试一个(50core,400GB memory,50 slot)规模的作业,优化效果如下:
6.4 kafka流量动态failover能力
为了保证数据及时上报,Lancer对于数据缓冲层的kafka的发送成功率依赖性很高,经常遇到的case是高峰期或者流量抖动导致的kafka写入瓶颈。参考Netflix Hystrix 熔断原理,我们在网关层实现了一种动态 kafka failover机制:网关可以根据实时的数据发送情况计算熔断率,根据熔断率将流量在normal kafka和failover kafka之间动态调节。
基于滑动时间窗口计算熔断比例:滑动窗口的大小为10,每个窗口中统计1s内成功和失败的次数。

熔断器状态:关闭/打开/半开,熔断率=fail_total/sum_total , 为避免极端情况流量全切到 failover,熔断率需要有一个上限配置。熔断后的降级策略:normal kafka 熔断后尝试切 failover,failover kafka 如果也熔断的话就切回 normal
判断逻辑:

6.5 全链路流控、反压、降级
从端上上报到数据落地的整个流程中,为了保证稳定性和可控性,除了前述手段,我们还引入了整体流控、反压、降级等技术手段,下面综合介绍下。

从后向前,分为几个环节:
1. 数据分发层:
如果出现消费延迟,数据反压到数据缓冲层kafka
单作业内部通过backlog反压做subtask之间的流量均衡
2. 数据网关层:
如果写入kafka延迟,直接返回流控码(429)给数据上报端
数据网关层和数据分发层之间通过 kafka tp级别流控调度适配局部tp处理延迟。
3. 数据上报层:
适配数据网关的流控返回:做退避重试
基于本地磁盘进行数据的堆积
配置动态推送生效主动采样/降级堆积
6.6 开发阶段质量验证
为了在开发阶段保证整体服务的正确性和稳定性,开发阶段我们设计了一套完整的测试框架。
新版本上线之前,我们会同时双跑新旧两条作业链路,将数据分别落入两张hive表,并且进行全分区的条数和内容md5校验,校验结果以小时级别/天级别报表的形式发出。此测试框架保证了版本迭代的过程中,端到端的正确性。
同时为了保证异常极端情况下数据的准确性,我们也引入了混沌测试,主动注入一些异常。异常包括:job manager挂掉,taskmanager挂掉、作业随机重启、局部热点、脏数据等等。
07 未来展望
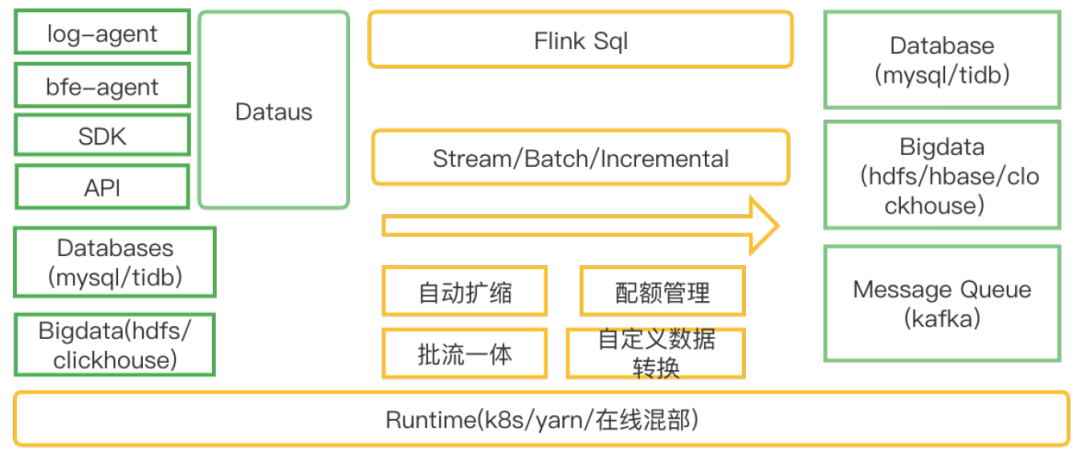
链路架构升级,接入公司级的数据网关(Databus),架构统一并且可以涵盖更多的数据上报场景。
云原生,拥抱K8S,面向用户quota管理,并且实现自动资源AutoScale。
拥抱批流一体,强化增量化集成,覆盖离线批集成场景,打造统一基于Flink的统一化集成框架。
