作者: 杨亚强 来自:美图数据技术团队
本文系美图互联网技术沙龙第 11 期嘉宾分享内容
大数据技术和应用系统目前已经在各个行业中发挥着巨大的作用,各种各样的开源技术也给大数据从业人员带来了很大的便利。Bitmap 作为一种大数据需求下产生的计算体系,有着计算速度快、信息密度高、支持海量数据等众多优势。
美图拥有海量用户数据,每天都有大量数据计算任务。而 Bitmap 技术能大幅度减少计算的开销,节省数据存储的成本,尽管有不少公司做过 Bitmap 的相关尝试,但是到目前为止还没有一个相对成熟的分布式 Bitmap 开源应用,因此美图研发了自己的分布式 Bitmap 系统,应用于美图各个场景下的相关数据计算任务。
/ Bitmap简介 /
Bitmap 作为被各种框架广泛引用的一门技术,它的原理其实很简单。
bit 即比特,而 Bitmap 则是通过 bit 位来标识某个元素对应的值(支持 0、1 两种状态),简单而言,Bitmap 本身就是一个 bit 数组。
举个简单的例子,假设有 10 个用户(ID 分别为 1~10),某天 1、3、5、7、8、9 登录系统,如何简单的表示用户的登录状态呢?如图 1,只需要找到用户对应的位,并置 1 即可。

图 1
更多地,如果需要查看某用户当天是否登录系统,仅需查看该用户 ID 位对应的值是否为1。并且,通过统计 Bitmap 中 1 的个数便可知道登录系统的用户总数。Bitmap 已支持的运算操作(如 AND、OR、ANDNOT 等)可以使维度交叉等计算更加便捷。
Bitmap两个重要的特性
高性能
Bitmap 在其主战场的计算性能相当惊人。在美图,早期的统计主要基于 Hive。以美图系某 APP 数据为基准进行了简单的留存计算(即统计新增用户在次日依然活跃的用户数量),通过 Hive(采用 left out join)耗时 139 秒左右,而 Bitmap(交集计算)仅需 226 毫秒,Hive 的耗时是 Bitmap 的 617 倍左右。如图 2 所示,其中,Hive 基于 4 节点的 Hadoop 集群,而 Bitmap 仅使用单节点单进程。
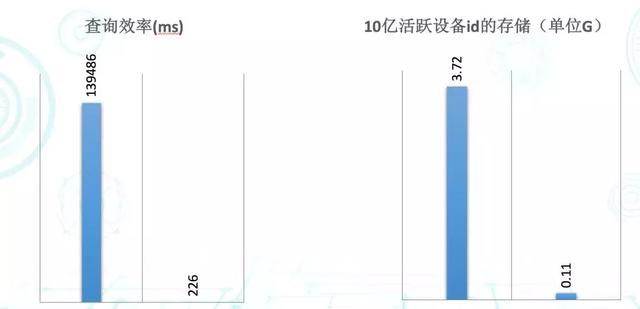
图 2
存储空间小
由于 Bitmap 是通过 bit 位来标识状态,数据高度压缩故占用存储空间极小。假设有 10 亿活跃设备 ID(数值类型),若使用常规的 Int 数组存储大概需 3.72G,而 Bitmap 仅需 110M 左右。当然,若要进行去重、排序等操作,存储空间的节省带来的性能红利(如内存消耗等)也非常可观。
美图 Bitmap 应用
美图公司拥有众多 APP,如美图秀秀、美颜相机、美拍、美妆相机、潮自拍等。大家熟知的美图秀秀和美颜相机都拥有千万级别的日活,历史累积的用户量更达几十亿。
大部分主要日常统计功能均基于 Bitmap,如新增、活跃、留存、升级、回访等。 同时,我们还支持时间粒度(比如天、周、月甚至年)及 APP、渠道、版本、地区等多种维度,以及各维度的交叉计算等。

图 3
Bitmap 原理简单,但是仅通过 Bitmap 服务来支撑海量数据和需求比想象中更复杂。从 2015 年至今,从单机版到分布式,从单 APP 到各种各样 APP 的接入,从少量指标的「少量」数据到目前的海量数据和需求,我们在 Bitmap 的实践过程中也遇到了不少的挑战,其中较典型的有:
百 T 级 Bitmap 索引。这是单个节点难以维护的量级,通常情况下需要借助外部存储或自研一套分布式数据存储来解决;
序列化和反序列化问题。虽然 Bitmap 存储空间占用小、计算快,但使用外部存储时,对于大型 Bitmap 单个文件经压缩后仍可达几百兆甚至更多,存在非常大的优化空间。另外,存储及查询反序列化数据也是非常耗时的;
如何在分布式 Bitmap 存储上比较好的去做多维度的交叉计算,以及如何在高并发的查询场景做到快速的响应
/ 美图分布式 Bitmap—Naix /
Naix,即美图 Bitmap 服务的终形态,是美图自主研发的通用分布式 Bitmap 服务。为了使 Naix 适用于各种场景,我们在设计时都尽可能让相关组件和结构通用化。
Naix 的名字来源于 Dota,在美图数据技术团队有各种「Dota 系列」的项目,如 Kunkka、Puck、Arachnia 等。将分布式 Bitmap 称作 Naix 的原因十分简单,其谐音 Next 寓意着下一代 Bitmap。
Naix系统设计
整个 Naix 系统如图 4 所示主要分为三层:外部调用层、系统核心节点层、依赖的外部存储层。
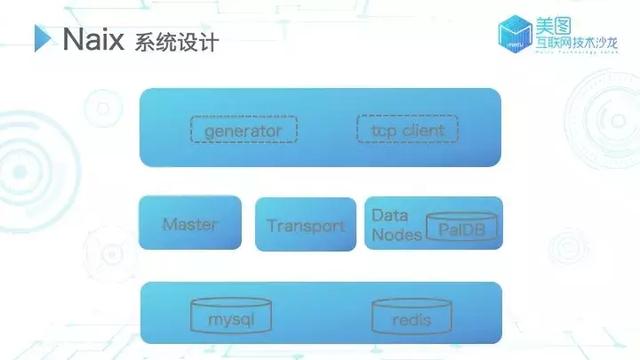
图 4
外部调用层
外部调用层分为 generator 和 tcp client。generator 是负责生成 Bitmap 的工具,原始数据、常规数据通常存储在 HDFS 或者其他存储介质中,需要通过 generator 节点将对应的文本数据或其他数据转化成 Bitmap 相关的数据,然后再同步到系统中。tcp client 主要负责客户端应用与分布式系统的交互。
核心节点层
核心节点层主要包含三种:
Master 节点,即 Naix 的核心,主要是对集群进行相关的管理和维护,如添加 Bitmap、节点管理等操作;
Transport 节点是查询操作的中间节点,在接收到查询相关的请求后,由 Transport 对其进行分发;
Data Nodes(Naix中核心的数据存储节点),我们采用 Paldb 作为 Bitmap 的基础数据存储。
依赖的外部存储层
Naix 对于外部存储有轻量级的、依赖,其中 mysql 主要用于对元数据进行管理,并维护调度中间状态、数据存储等,而 redis 更多的是作为计算过程中的缓存。
Naix 数据结构
index group

图 5
如图 5 所示 index group 是 Naix 基本的数据结构,类似于常规数据库中的 DataBase,主要用于隔离各种不同的业务。比如在美图的业务中,美图秀秀和美拍就是两个不同的 index group。每个 index group 中可以有多个i ndex,index 类似于常规数据库中的 table,如新增和活跃的 Bitmap 就属于两个不同的 index。
index
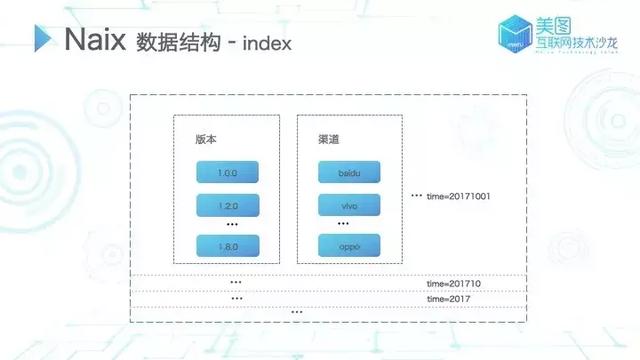
图 6
在每个 index 中,都有一个固化的时间属性。由于 Bitmap 数据可能涉及不同的时间周期,通过格式化的时间方式将不同时间周期的数据放入同一个 index。对应时间段内的 index 涉及多个维度,如版本、渠道、地区等,每个维度涉及不同的维度值(如 v1.0.0、v1.2.0 等),而我们所指的 Bitmap 文件则是针对具体的维度值而言的。
数据信息字典管理
Bitmap 用于标识某个用户或元素的状态通常是指 ID,但在现实业务应用中往往并非如此。如果需要对 imei、idfa 进行统计,则需要将设备标识通过数据字典的映射转化为 ID 后再生成 Bitmap 并完成相关统计。同时,为了方便数据的维护和使用,我们对维度、维度值也做了字典映射管理。
Naix genertor
对于 Bitmap 原始数据通常指是类似于 Mysql 记录数据、HDFS 文本文件等,而 Naix generator 的作用是将原始数据转化成 Bitmap 相关数据并同步到 Naix 系统,generator 以插件的方式支持各种不同场景的 Bitmap 生成,再由业务方基于插件开发各自的业务逻辑。
simple plugin 是简单的方式,也是我们早使用的插件。在美图,大部分的数据都是 HDFS 的原始数据,通过 Hive Client 过滤相关数据到处理服务器,再通过插件转换成 Bitmap 数据。
由于美图数据量大、业务复杂,在之前的某个阶段,每天的数据生成需要消耗近 3 小时。如果中间出现问题再重跑,势必会影响其他的统计业务而造成严重后果。因此我们研发了 mapreduce plugin,期望通过分发自身的优势,加快数据生成的速度。
实践证明,使用 mapreduce plugin 终可将接近 3 小时的 generate 过程压缩至 8 分钟左右(基于 4 节点的测试集群)。基于 mapreduce 的特点,在业务和数据量持续增加的情况下我们也可以通过节点扩容或者 map、reduce 数量调整很容易的保持持续快的 generate 速度。
第三个插件是 bitmap to bitmap plugin,针对各种时间周期的 Bitmap 数据,用户可以通过我们提供的 plugin 进行配置,在系统中定期地根据 bitmap 生成 bitmap。类似周、月、年这样的 Bitmap,该插件可以通过原生的 Bitmap 生成周期性的 Bitmap(例如通过天生成周、通过周生成月等),用户仅需提交生成计划,终在系统中便会定期自动生成 Bitmap 数据结果。
Naix 存储
分片
如何将海量数据存储到分布式系统中?通常情况下,常规的分布式 Bitmap 都是依赖于一些类似 hbase 之类的外度存储或者按照业务切割去做分布式的存储,在计算过程中数据的查找以及数据的拷贝都是极大的瓶颈。经过各种尝试,终我们采取分片的方式,即通过固定的宽度对所有的 Bitmap 做分片;同一分片、相同副本序号的数据存储至相同节点,不同分片的数据可能会被存放在相同或者不同的节点。
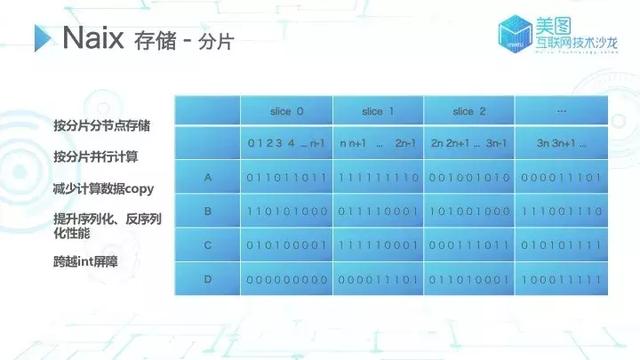
图 7
分片的设计带来了不少的好处:
百 T 级别的数据分布式存储问题迎刃而解;
并行计算:Bitmap 结构十分特殊,基本上的 Bitmap 操作都可以按分片并行计算,再汇总整合。对于巨大的 bitmap 数据,也可按此方式提升速度;
数据 copy 问题:通常情况下,在未分片前大部分 Bitmap 实践会按照业务将数据分开,但当数据量大时,单个业务的数据在单节点也无法存储。当涉及到跨业务的计算时,必然需要进行数据 copy。但进行分片后,天然就将这些计算按照分片分发到不同节点独自进行计算,避免了数据 copy;
序列化和反序列化的问题:通常会出现在大型 Bitmap 中,但分片后所有 Bitmap 大小基本可控,便不再有序列化和发序列化的问题;
跨越 int 屏障:通常 Bitmap 实现仅支持 int 范围,而随着美图业务的发展,其用户增长很快便会超过 int 范围。采取数据分片的方式,通过分片内的 id 位移,可以轻易地将分片进行横向叠加从而支持到 long 的长度。
replication
replication 是常规的分布式系统极其重要的特性,防止由于机器宕机、磁盘损坏等原因导致的数据丢失。在 Naix 中,replication 支持 index group level。
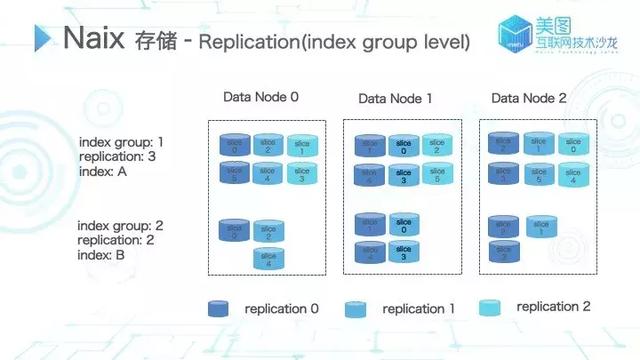
图 8
如图 8 所示,用深蓝色标识主分片,浅蓝色和蓝绿色标识剩下的副本分片。通过两个不同 replication 数量设置的 index group,以及两个 index 内部对应的两个 index,在图中我们可以看到对应同一个 replication 下标的同一个分片,都会被存储在相同数据节点。而对于同一个分片的不同副本则必然是存储在不同节点中。
空间和文件碎片相关的优化
空间和文件碎片的优化是 Bitmap 实践中尝试多的一部分。Bitmap 基于 Long 数组或其他数字型数组实现,其数据往往过于密集或稀疏,有很大的优化空间。大部分Bitmap的压缩算法类似对齐压缩,通过压缩节省空间并减少计算量,在美图 Bitmap 中,早期使用 ewah(采用类似 RLE 的方式),后续切换为 RoaringBitmap,这也是目前 Spark、Hive、Kylin、Druid 等框架常用的 Bitmap 压缩方式中。对 ewah 和 RoaringBitmap 进行性能对比,在我们真实业务场景中测试,空间节省了 67.3%,数据耗时节省了 58%。在 query 方面,实际场景测试略有提升,但不及空间和 generate 耗时性能提升明显。
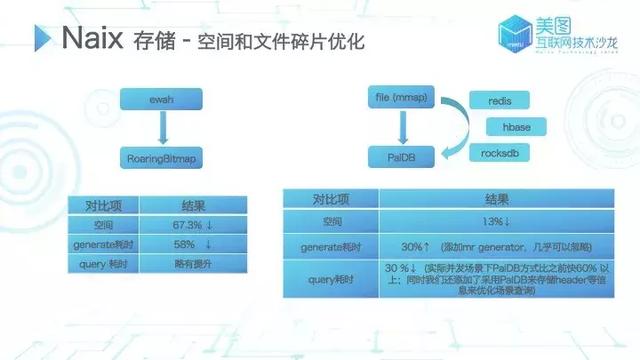
图 9
早期 Bitmap 采用文件存储,在读取时我们进行了类似 mmap 的优化。但日常业务中存在很多细粒度维度拆分的Bitmap(比如某个渠道的新增用户较少),而处理分片操作会将这些小型 Bitmap 拆分得更小。小文件对于操作系统本身的 block 和 inode 利用率极低,尝试通过优化存储方案来解决小文件碎片的问题。主要调研了以下几个方案:
Redis
Redis 本身支持 bitset 操作,但其实现效果达不到期望。假设进行简单的 Bitmap 数据 kv 存储,以 200T 的数据容量为例,每台机器为 256G,保留一个副本备份,大概需要 160 台服务器,随着业务量的增长,成本也会逐步递增;
HBase
在美图大数据,HBase 的使用场景非常多。若采用 HBase 存储 Bitmap 数据,在读写性能上优化空间不大,且对 HBase 的依赖过重,很难达到预期的效果;
RocksDB
RocksDB 目前在业界的使用较为普遍。经测试,RocksDB 在开启压缩的场景下,CPU 和磁盘占用会由于压缩导致不稳定;而在不开启压缩的场景下,RocksDB 在数据量上涨时性能衰减严重,同时多DB的使用上性能并没有提升;
PalDB
PalDB 是 linkedin 开发的只读 kv 存储,在官方测试性能是 RocksDB 和 LevelDB 的 8 倍左右,当数据量达某个量级。PalDB 的性能甚至比 java 内置的 HashSet、HashMap 性能更优。PalDB 本身的设计有利有弊,其设计导致使用场景受限,但已基本满足 Naix 的使用场景。PalDB 源码量少,我们也基于具体使用场景进行了简单调整。经测试,终存储空间节省 13%,query 耗时在实际并发场景中,使用 PalDB 会有 60%以上的提升。generator 耗时略长,但由于增加了 mr 的 generator 方式故此影响可忽略;
Naix query
在 Naix 系统中,整体的交互是在我们自研的 rpc 服务基础上实现的(rpc 服务基于 Netty,采用 TCP 协议)。在 rpc 底层和 Naix 业务端协议都采用了 ProtoBuf。
图 10
分布式计算的过程包括节点、分片、数据存储等,而针对查询场景,我们该如何找到相关数据?如何进行计算呢?
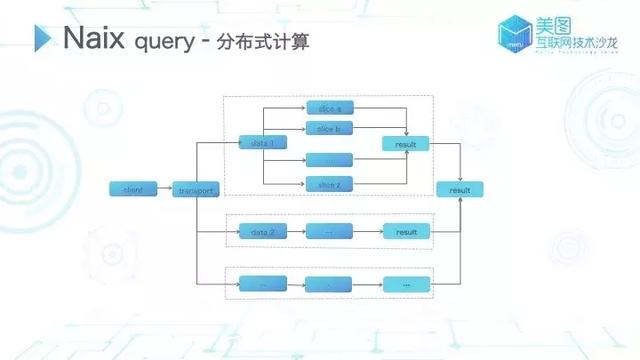
图 11
在 Naix 中,当 client 发起查询请求到 transport 节点,transport 节点通过查询条件选择优的节点分发请求。在对应的节点中根据请求条件确定分片的选择,每个节点找到对应分片后进行计算,将计算完成的结果结点进行聚合并返回 client,类似于 fork-join 叠加 fork-join 的计算过程。
Naix 系统以通用的方式支持查询:支持操作符 ∩ ∪ - ( ) 组合表达式;用户根据使用场景选择所需的查询 Tuple 和操作符组装查询表达式即可,当然,我们也封装了查询表达式的组装转换工具由于 Naix 支持的查询本身与业务无关,用户可以通过组装表达式做各种查询操作。

图 12
举几个简单的例子:
简单的设备或用户定位,比如查询某个是否是某天的新增用户或者活跃用户;
多维度的组合分析,比如查看某天美拍 vivo 这个渠道新增用户在第二天的留存情况;
多维度的局部组合交叉分析(数据分析常见场景),比如统计某天美拍在百度、vivo 渠道对应的 v6.0 和 v8.0 版本的活跃用户数,这就涉及两个渠道和两个版本交叉共 4 个组合的查询。这种操作通常用于数据分析。包括前面两种,这些简单的查询操作平均响应仅需几毫秒;
多维度的全交叉计算,类似于需要知道某天美拍中的渠道和版本所有信息做交叉,产出这么大量级的数据结果。类似操作的性能主要看查询计算的维度数量以及涉及的数据量,通常是在秒到分钟级的响应。
