本文是腾讯云工程师李巍在腾讯云Techo开发者大会现场的演讲实录,演讲主题是《腾讯自研HTAP数据库TBase的应用实践》。

今天给大家分享的主要内容包括两部分:
TBase概述;
TBase在保险公司的应用实践。
TBase概述
TBase是腾讯自主研发的新一代分布式NewSQL国产数据库,具备业界领先的HTAP能力,在提供NewSQL便利性的同时还能完整支持事务并保持SQL兼容性,现已开源,详情请点击☞微信支付用的数据库开源了
首先我们来看看TBase的发展历程,TBase是从社区的PostgreSQL发展而来,早就是替换Oracle的部分场景,发展到今天成为一个功能完备的企业级分布式HTAP数据库。
从2011年到现在,八年的时间TBase走过了3个时代。

2011-2013单机时代,作为离线的TDW大数据平台的一个互补,提供小数据量的实时展示。重要的特性就是跟大数据平台互联互通。
2013-2016 OLTP时代,随着业务发展单机计算瓶颈逐渐凸显,促使我们进行集群化,早期集群化的过程主要是侧重OLTP型业务,在这个阶段我们做到了单集群超过200台,日请求量达到10亿。
2016年进入了HTAP时代,TBase跟随腾讯云一起,面对更多的客户,了解到企业对OLAP类场景需求迫切,促进了我们在OLAP领域的成长。
TBase依托内外部客户实践,一直专注于提升数据库的通用性,对客户屏蔽分布式的细节。TBase在兼容SQL标准、提供完整的分布式事务能力的同时,保证了金融级数据容灾,在数据安全、分布式执行器的优化以及读写分离等方面也做了很多工作。
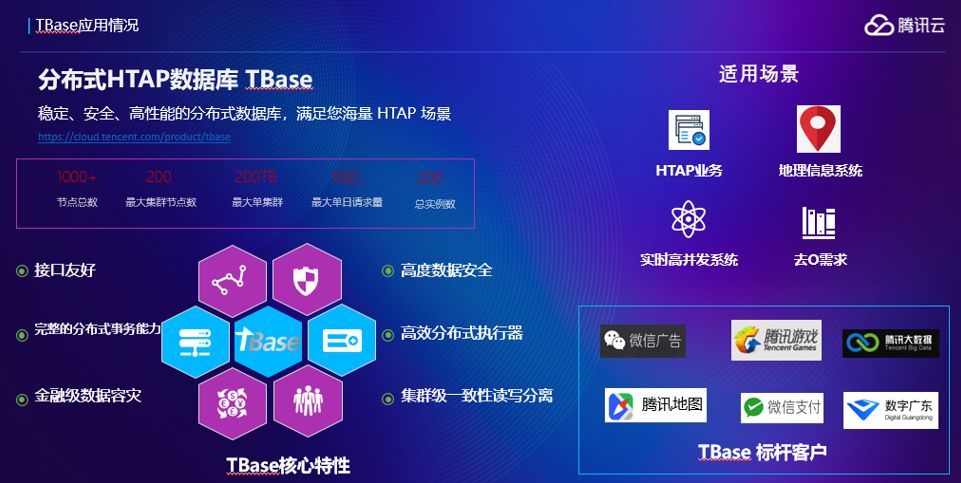
截至2019年10月,TBase在HTAP、地理信息系统、实时高并发等场景有了多个标杆客户,例如内部的腾讯大数据,微信广告,腾讯地图,腾讯游戏等,线上实例数超过200,节点规模突破1000,大单集群存储超过200TB,单日请求量超过10亿。
TBase在保险公司的应用实践
在我们早期跟保险公司做交流的时候,客户有五个基本需求:
1. 高扩展性。保险公司大家都知道比如寿险、车险、财产险,业务量都很大,随着业务规模的扩大,需要数据库为它的快速发展提供支撑。
2. 分布式事务。数据一致性是金融行业的核心诉求。
3. 高可用性。比较容易理解,要求7×24小时的服务保障,RTO秒级,RPO为0。
4. 多业务隔离。因为保险公司是分业务的,业务又可能是分省的,每一个业务都有不同的集群,会带来比较大的成本支出,所以要求业务既能共享,又需要做隔离,这里我们是怎么做的,下面会详细介绍。
5. 易运维。保险行业非常重视安全性,客户要求我们系统私有化部署,终上线之后运维会交给客户,是否易运维是一个很大的考量点。
1
高扩展性
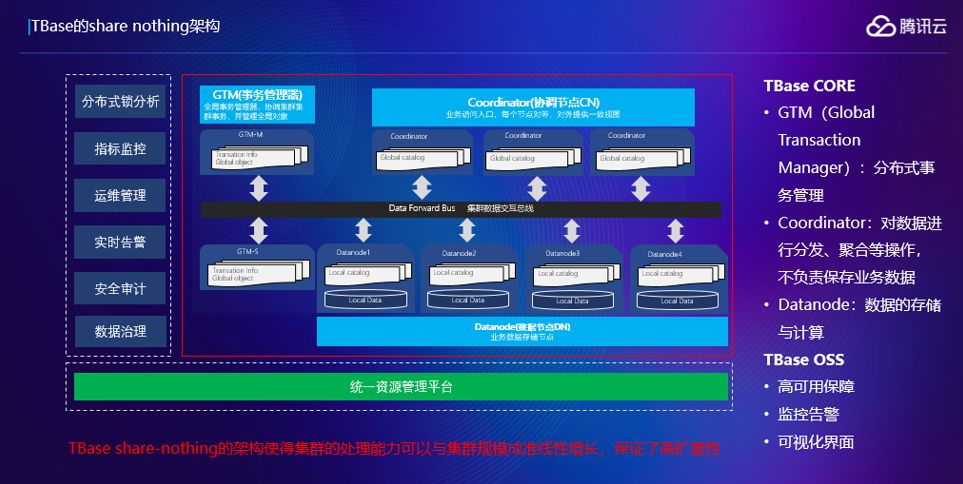
首先看一下高扩展性,大家看一下TBase的架构就明白了,红框是TBase的内核,内核分三类主要的节点,类是GTM的节点,这个节点保证分布式事务的一致性,第二类节点是协调节点,是用户访问的一个接口层,用户查询访问我们协调节点会翻译成查询计划,在数据节点做数据计算,把结果返回到协调节点,做汇总,再返回给应用。第三类就是数据节点,负责数据计算和存储。这里可以看到:如果你觉得当前的集群支撑不了业务,加一些机器过来就可以提升你的处理能力,集群的处理能力与TBase的规模呈准线性的增长。
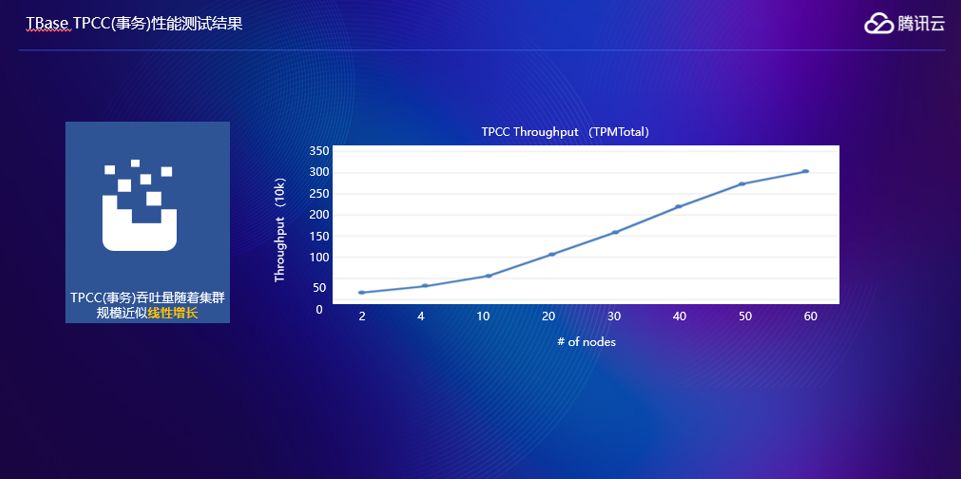
这里我们做了一个测试,横坐标是机器的台数,纵坐标是吞吐量,可以看到是集群处理能力跟集群规模是准线性的增长关系。
2
分布式事务
再看一下分布式事务对金融业务的重要性。
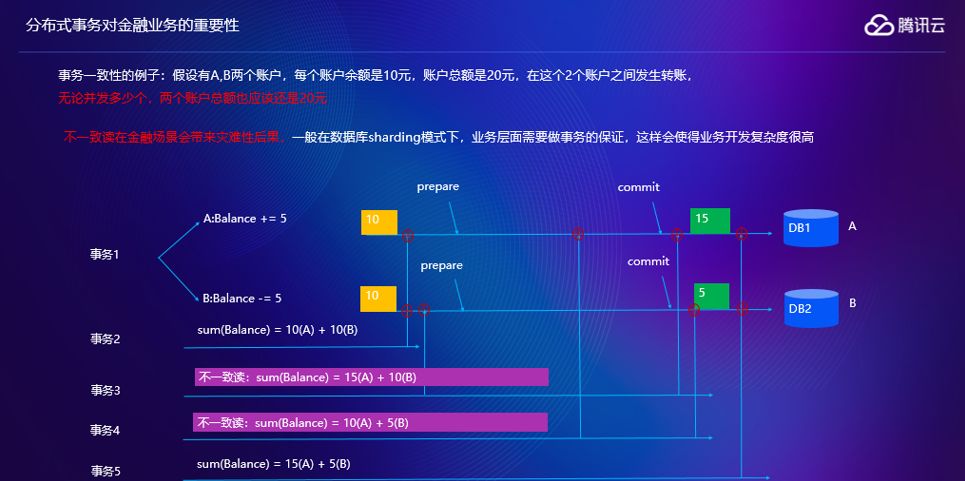
举一个例子,转帐场景下,从B账户转5块钱给A账户,假如说用分库分表的模式考虑这个问题。有另外一个事务,是查询这两个账户的和,如果在前面两个转帐事务之前可以查到账户余额是10+10是20块钱,这个是没有问题的。如果有一个事务3,这里面会出现一个情况,首先在B转出账户提交之前,另外一个查询是在A转入的提交之后,到达节点时间的差异,这里面会出现一个问题,就是说两个的和会多出5块钱出来,就出现读不一致。
还有一种场景,假设我在个账户转入之前,在第二个账户转出之后,这里面会有一个问题,就会发现会少5块钱,分库分表的模式下读一致性不是能时刻保持的。假如说还有一个事务,在两个事务都提交之后再去读的话,就会发现两个账户和是OK的,是没有问题的。这说明一个问题,就是在分布分表的场景下不能保证任意时刻的读一致性,这在金融场景是很严重的后果。业务一般会在业务逻辑上来规避这个问题,这就导致业务开发复杂度会变高。
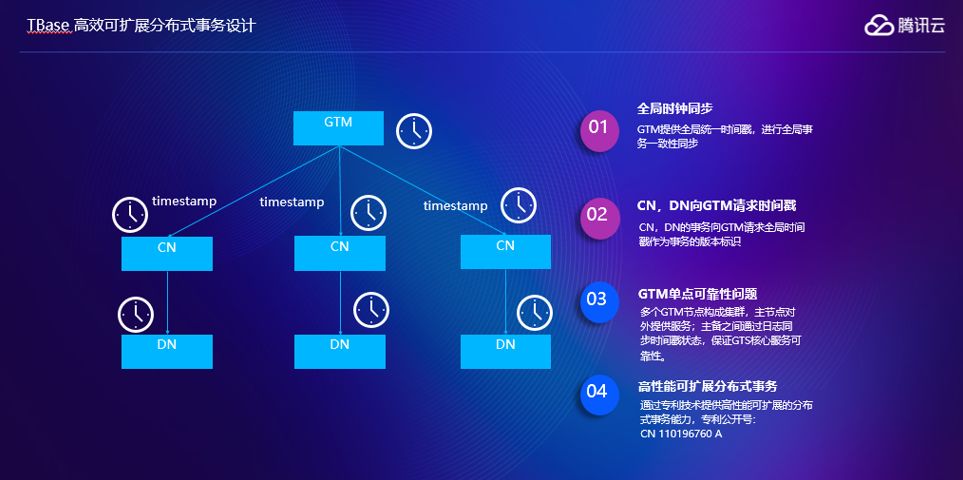
TBase做了一些事情来减轻业务开发的复杂度,引入一个全局时钟的节点,就是上面的GTM,提供全局统一时间戳,进行全局事务的一致性同步,通过TBase MVCC机制可以保证任意时间的一致性。
可靠性和性能是需要同时考虑的问题,可靠性我们采用GTM时间戳来保证可靠。扩展性上,因为GTM做的事情非常少,我们做过测试,在腾讯内部,一个256G内存64CPU的机器的GTM下,在集群规模比较大的场景下,可以跑到千万级别的TPS,这里有一个国际上的专利号,大家有兴趣可以查阅一下。
3
高可用
我们这个部署图是基于某保险公司,因为只有北中心跟南中心,所以我们是采用了两地两中心的部署,这个可以扩展成两地三中心的部署模式。
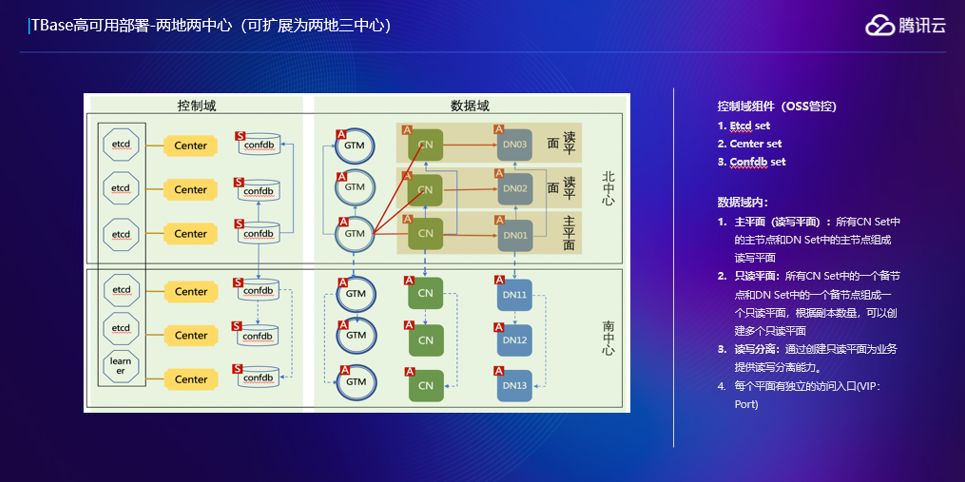
这张图显示的不仅仅是我们的数据域,也就是前面说的TBase内核模块,还有我们的控制域,就是我们的OSS管控系统,包括Etcd set, Center set和Confdb set,etcd set保证我们的管控系统都是可靠的。这里提一点,TBase集成了一个读写平面的特性,如果你对数据的实时性要求没那么高,可以通过我们的读平面进行数据读取,比如说数据的抽取,可能抽取出去,到其他系统做一些离线的计算。
这里面基于刚才说的部署模式,可以做一个故障场景的分析,还是分南北中心部署,通过VPC访问我们的服务,如果各个平面出现故障, TBase是怎样来保障服务的延续性。
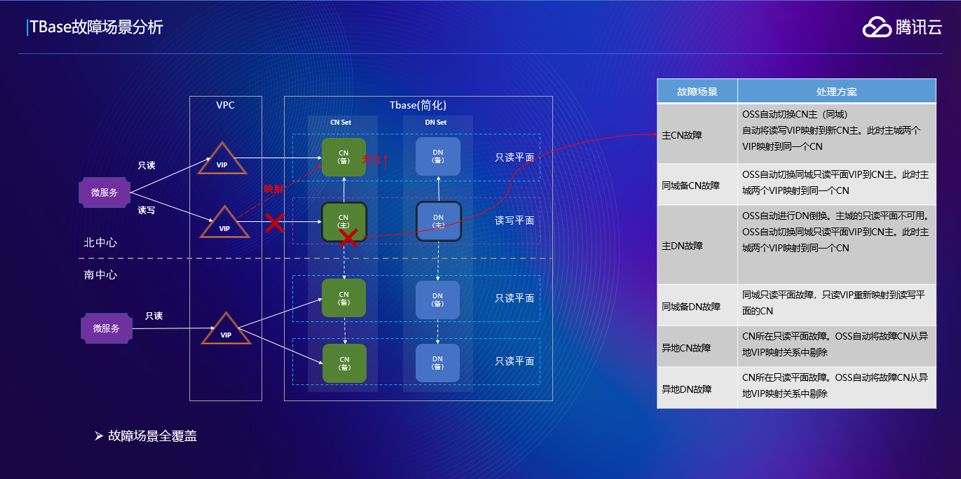
首先来看重要的读写平面的主CN故障之后会怎么做,假设说读写平面的主CN宕掉了,OSS会把同城的备CN升主,备CN升主会有一个问题,就是备平面不可用。我们的OSS系统会做一个事情,把读写层面的VIP映射到主CN,这样读写面和只读面会转向一个平面,会给主平面带来一些开销,但是保证了可靠性。
第二个场景是同城的备CN故障,会出现什么情况?这里备CN只会影响读请求但是不影响写请求,这里面只做一个操作,把只读VIP指向写VIP,这里面读写平面会承担之前只读平面的那部分压力,但是保证了只读业务不受影响。
假设主DN挂掉是什么情况,这里面也会把备DN做一个升主,如果备DN 升主之后,之前备平面不能用了,会把备DN所在平面的VIP做一个切换,转到读写上面去,就保证只读平面可以正常运行。
如果是跨城故障场景呢?假设说跨城的CN挂掉了,可以看到跨城的VIP其实指向两个CN,只需要做一件事情把这个VIP对应的故障CN删掉就可以了,不会影响只读,原来两个可以选一个,切换之后只是没得选。
4
多业务隔离
TBase具备了多租户隔离能力,满足了保险机构要求按照业务、省份、分公司等多个维度进行资源隔离的诉求。

分为三个层级,从上至下是:系统管理层,通过租户来发起资源的申请,释放,或者是查看等;第二层是租户层,管理租户内部的权限;第三层是资源管理层,真正的将节点按照资源划分到服务器内。
在租户基础上,第二层对租户做权限分层,一个租户只有一个项目,只能看到这个项目,如果第二个租户有两个项目,可以看到这两个项目,但是个租户是看不到这两个项目的。租户管理这层,租户申请一些实例,终会体现到物理资源里面去,这里面对物理资源可以简单说一下。我们对服务器的资源做了一个切分,比如说有一个比较强劲的物理机,比如说有100个核500多G的内存,一般的应用比如说一个测试库用不了这么大的一些资源,我们可以把这些资源做一些切分,通过租户对集群规模的申请,会智能的把这些资源分配到对应机器上去。终会达到资源共享,可能租户1的实例的节点会分布到多台机器上,但是在多个实例之间又是相互隔离的。
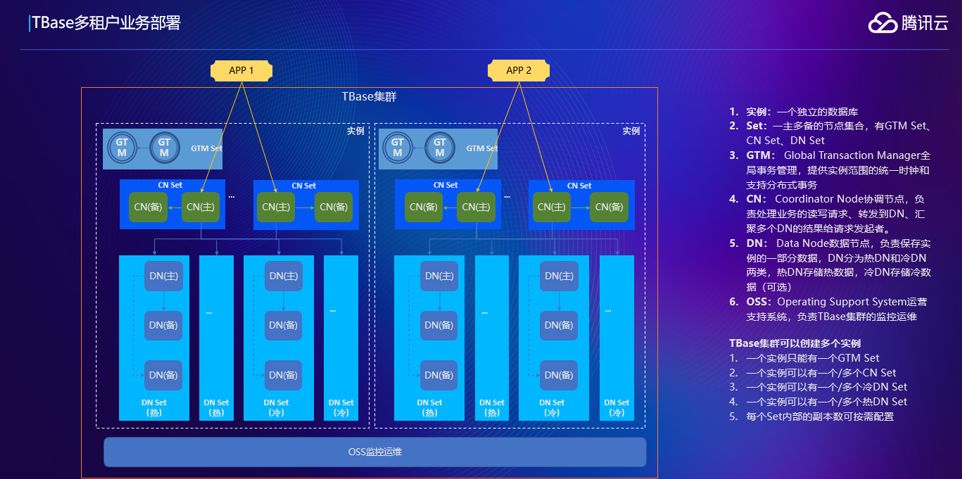
上图是多租户在真实业务部署的案例,假设每个APP对应的就是其中一个服务实例,多租户这里面重要的就是底下这层OSS管控系统,所有的实例,对TBase来说,是同一套管控系统管控的。一个管控系统可以管控多个实例,这样运维起来很方便。假设一个管控系统管理一个集群,这样运维人员处理的时候会非常的麻烦,管理多个集群可能要登录多个OSS。TBase这样一套OSS管理所有的实例,资源都是通过这一套管理系统做分配,也减轻了运维的工作。
5
易运维
通过TBase OSS管控系统,可以实现监控数据展示、告警配置以及告警记录查询、日常运维操作(集群扩容,主备切换,配置更改、多活配置等)、数据库备份与恢复、慢查询分析、性能巡检等一系列功能,极大的提升了运维效率以及问题定位的效率。

在自动化运维上,我们做了一个可视化的界面,主要是监控数据的展示、告警配置、扩缩容、数据库的备份恢复、慢查询、性能巡检报告,这个页面展示的我们节点分布的情况,还有可以查看运行状态、进行各种操作等。备份管理页面,TBase的备份目前是备到HDFS上,存量可以选几天备一次。数据恢复,涉及到多个结点怎么协调,恢复到什么时候才是一致的状态,因为每个节点的数据提交时间是不一样的,假设说所有的结点都恢复到十点,就可能会出现一个不一致的事务,TBase恢复系统会帮你智能选择一个一致的状态,提供给你一些可选择时间点;或者我们还提供另外一个选择,如果你了解这块的话,可以选择自己把时间的点算出来,这样会更。
