1. Introduce
对于大规模分布式系统来说,故障异常是常态,如何确保系统在面对各种异常情况下,仍然可以满足对用户承诺的高可靠和高可用,是当前系统设计和开发者面临的挑战。随着Chaos Engineering[1]的普及,当前分布式系统的开发者开始通过fault inject的手段将故障异常常态化的引入到系统的测试中,期望通过提前预演所有可以预见的故障来验证系统的鲁棒性。

通常引入到测试中的故障有:crash异常、hang异常、网络丢包乱序、磁盘故障等,通过Fault inject工具,随机的将这些异常注入到系统节点中,通常刚开始的时候,会尝到一些甜头,能够发现一些系统异常处理的问题。很快,伴随着这些bug的fix,系统开始趋于一定的“稳定”,但是这并非说明系统就真的稳定,新的bug随着后续的线上运行,还是在不停的冒出来,而且它们很多和异常处理相关。其原因也很简单,简单的随机故障注入测试,其效率某种程度上是很低的,例如多副本数据复制,其整个流程可能涉及了多个成员的多次message传递和状态变更,很多时候,bug往往隐藏在一些特定的时间和空间条件下才能被触发(不全是corner case),所以简单的随机Fault inject可能并不能很好的触发这些问题,就如上图随机乱射的镖,很难正中靶心。所以如何有效的来做Fault inject,来提升测试的效率,发现更多的bug,是现在大家都开始尝试实施Chaos engineering之后比较关心和需要思考的问题。
接下来将为大家简单介绍SOSP 2019的一篇文章:CrashTuner: Detecting Crash Recovery Bugs in Cloud Systems via Meta-info Analysis[2],思考如何提升fault inject的效率,发现更多的bug,提升系统的鲁棒性,增加信心
2. CrashTuner
CrashTunner主要的工作就是如何发现分布式系统中Crash-recovery相关的bug,基本的动机就是:
- 基于随机的Fault inject这种测试方法效率并不理想
- 基于Mode check的这种方式会有state explosion的问题
通过分析以往crash-revovery相关的bug,发现了一个规律,大体这类bug可以分为两种场景:
- The pre-read scenario: Node N crashes before its metainfo is read by another node M. Node M is not aware of the crash and keeps using the stale information of N, leading to aborts and job failures.
- The post-write scenario: Node N crashes after N updates the system state (i.e., stores to meta-info variables). In the recovery process, intermediate updates of N need to be discarded and rolled back. The recovery process may mis-handle the corrupted state, leading to failed (or incorrect) recovery attempts.
meta-info variables: variables referencing high-level system state information.
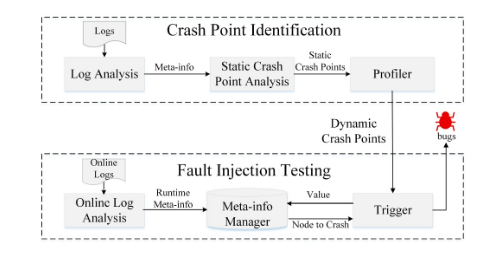
其基本的思路:就是将pre-read:也就是read meta-info variable之前和post-write:也就是write meta-info variables之后这2个点作为crash-point,注入crash fault进行测试,并且在Hadoop2/Yarn, HBase, HDFS, ZooKeeper,and Cassandra系统上测试了,运行17.39 hours,发现了21个新bug,如下Table 5。
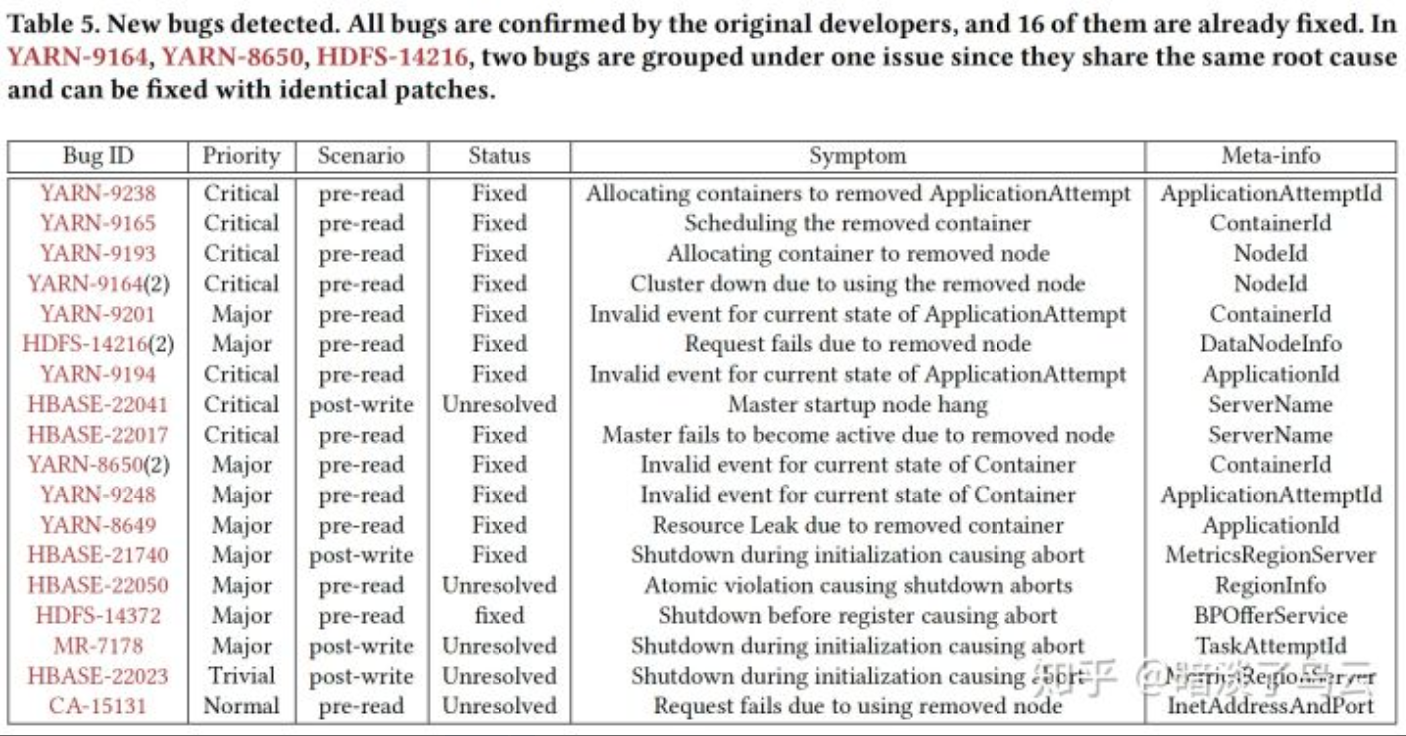
当然,其所有的crash point都是通过log和静态代码分析的计数,自动提取出来的,感兴趣的可以参考论文的细节。这里不做过多的展开。
3. Thinking
CrashTuner重要的一点可能就是给出了一个很好的abstract:meta-info,她告诉我们在meta-info的read和update周边都是非常好的crash-point。那什么是meta-info?想必系统所有较高层级的state都是meta-info,尤其是那些会被持久化的state,例如数据复制里面的leader角色信息,raft里面term信息,I/O路径上数据复制里面的committed,apply状态等等。所以,对于分布式系统的开发者而言,可在fault inject的point选择上,做到更加和高效。所有的系统都是一个一个的流程组起来(例如I/O流程、选举流程、恢复流程等等),随着流程的推进,系统的状态也在发生着变化,典型的就是一个多副本数据复制系统的I/O路径,从收到用户request,到leader排队,写wal,复制给其他follower,然后committed,再apply;在这个流程中,可以梳理出多个状态,然后的选择给每个state变更前,变更中,变更后注入故障,这将大大提升Fault inject的效率。而实际上,这对系统的开发者而言,也并非难事。
Random fault inject有其必要性,但远远不够,对系统状态深入理解下的fault inject,将成为分布式系统bug finding的有利抓手。
Notes
限于作者水平,难免在理解和描述上有疏漏或者错误的地方,欢迎共同交流;部分参考已经在正文和参考文献列表中注明,但仍有可能有疏漏的地方,有任何侵权或者不明确的地方,欢迎指出,必定及时更正或者删除;文章供于学习交流,转载注明出处
参考文献
[1]. Rosenthal C, Hochstein L, Blohowiak A, et al. Chaos Engineering[M]. O'Reilly Media, Incorporated, 2017.
[2]. Lu J, Liu C, Li L, et al. CrashTuner: detecting crash-recovery bugs in cloud systems via meta-info analysis[C]//Proceedings of the 27th ACM Symposium on Operating Systems Principles. ACM, 2019: 114-130.
[3]. SOSP‘2019——SJTU-IPADS的集体见闻 (Day-1). "https://mp.weixin.qq.com/s/IQbBD_RxbeecrlPUiKcLjQ"
