前言
用 Python 处理Excel表格的几个常规库:
这些库都不如 OpenPyXL 强大,OpenPyXL 即可以读也可以写 Excel 2010+ 的 xlsx xlsm xltx xltm 文件。不过, OpenPyXL 库也是比较吃内存的,大约是原始文件的50倍左右。例如,一个50M大小的Excel文件,需要2.5G大小的内存运行。关于以上几个库的性能比对,请移步 OpenPyXL性能测试。
安装
在终端中输入命令,如下:
pip install openpyxlopenpyxl 在保存Excel表格时候会丢失原文件的图片和图表。如果要操作图片,则需要 pillow 库,安装如下:
pip install pillow
由于近军运会要在天朝举行,因此必须翻-墙才能安装。
使用方法
新建Excel表格
新建Excel表格,默认有一个名为 Sheet 的表格,如下:
from openpyxl import Workbook
wb = Workbook() #创建文件对象
ws = wb.active #获取默认sheet
wb.save("sample.xlsx")
打开已有的Excel表格
对已有的Excel表格进行操作,如下:
from openpyxl import Workbook, load_workbook
wb = load_workbook('sample.xlsx')
wb.save("sample.xlsx")
新建/获取Sheet表格
使用 Workbook.create_sheet() 方法新建Sheet表格。个参数是sheet名称,若不填,则默认以 Sheet1 Sheet2 Sheet3 ...方式命名;第二个参数是插入Sheet表格的位置,以 为个位置,若不填,则置于后。如下:
ws1 = wb.create_sheet("Mysheet") #默认在后插入
ws2 = wb.create_sheet("Mysheet", 0) #在个位置插入
wb.remove(ws1) #删除sheet
也可以后期随时修改sheet的名字,如下:
ws.title = "New Title"
修改sheet标签颜色,如下:
ws.sheet_properties.tabColor = "1072BA"
若知道sheet的名字,可以用如下方式获取sheet :
ws = wb.get_sheet_by_name("New Title")
ws = wb["New Title"]
也可获取全部sheet的名字,遍历sheet名字,如下:
sheets = wb.sheetnames
for sheet in sheets:
print(sheets)
for sheet in wb:
print sheet.title
['Sheet1', 'New Title', 'Sheet2']
也可以定位到相应sheet页,[0]为sheet页索引,如下:
sheet_names = wb.sheetnames # 获取所有sheet页名字
ws = wb[sheet_names[0]]
复制Sheet表格
仅能复制 单元格的值 样式 超链接 注释块 等,而 图片 和 表格 等是无法复制的,如下:
source = wb.active
target = wb.copy_worksheet(source)
操作单元格
由 worksheet 获取单元格,或直接给单元格赋值,如下:
cell = ws['A4'] #获取第4行第A列的单元格
ws['A4'] = 4 #给第4行第A列的单元格赋值为4
ws.cell(row=4, column=2, value=10) #给第4行第2列的单元格赋值为10
ws.cell(4, 2, 10) #同上
获取区域内的单元格,如下:
cell_range = ws['A1':'C2'] #获取A1-C2内的区域
colC = ws['C'] #获取第C列
col_range = ws['C:D'] #获取第C-D列
row10 = ws[10] #获取第10列
row_range = ws[5:10] #获取第5-10列
如果得到单元格,可以赋值,如下:
cell.value = 'hello, world'
或
cell = ws.cell(row=i, column=j, value="金额")
获取单元格的值,如下:
cellValue = ws.cell(row=i, column=j).value
获取行列数,如下:
row = ws.max_row #大行数
column = ws.max_column #大列数
一行行的获取数据,如下:
>>> for row in ws.iter_rows(min_row=1, max_col=3, max_row=2):
... for cell in row:
... print(cell)
<Cell Sheet1.A1>
<Cell Sheet1.B1>
<Cell Sheet1.C1>
<Cell Sheet1.A2>
<Cell Sheet1.B2>
<Cell Sheet1.C2>
一列列的获取数据,如下:
>>> for col in ws.iter_cols(min_row=1, max_col=3, max_row=2):
... for cell in col:
... print(cell)
<Cell Sheet1.A1>
<Cell Sheet1.A2>
<Cell Sheet1.B1>
<Cell Sheet1.B2>
<Cell Sheet1.C1>
<Cell Sheet1.C2>
因为性能的原因, Worksheet.iter_cols() 方法不能在只读模式下使用。
获取所有的列或行,如下:
rows = ws.rows
columns = ws.columns
因为性能的原因, Worksheet.columns 方法不能在只读模式下使用。
如果只想从worksheet中获取值,可以使用 Worksheet.values 属性,如下:
for row in ws.values:
for value in row:
print(value)
Worksheet.iter_rows() 和 Worksheet.iter_cols() 方法都可以添加 values_only 参数来达到仅获取值的目的,如下:
for row in ws.iter_rows(min_row=1, max_col=3, max_row=2, values_only=True):
print(row)
保存文件
使用 Workbook.save() 方法保存workbook,这个方法会不加提示的覆盖原文件,如下:
wb = Workbook()
wb.save('balances.xlsx')
获取单元格类型
from openpyxl import Workbook, load_workbook
import datetime
wb = load_workbook('sample.xlsx')
ws=wb.active
wb.guess_* = True #开启获取单元格类型
ws["A1"]=datetime.datetime(2010, 7, 21)
print ws["A1"].number_format
ws["A2"]="12%"
print ws["A2"].number_format
ws["A3"]= 1.1
print ws["A4"].number_format
ws["A4"]= "中国"
print ws["A5"].number_format
wb.save("sample.xlsx")
# 执行结果:
# yyyy-mm-dd h:mm:ss
# 0%
# General
# General
# 如果是常规,显示general,如果是数字,显示'0.00_ ',如果是百分数显示0%
# 数字需要在Excel中设置数字类型,直接写入的数字是常规类型
使用公式
from openpyxl import Workbook, load_workbook
wb = load_workbook('sample.xlsx')
ws1=wb.active
ws1["A1"]=1
ws1["A2"]=2
ws1["A3"]=3
ws1["A4"] = "=SUM(1, 1)"
ws1["A5"] = "=SUM(A1:A3)"
print ws1["A4"].value #打印的是公式内容,不是公式计算后的值,程序无法取到计算后的值
print ws1["A5"].value #打印的是公式内容,不是公式计算后的值,程序无法取到计算后的值
wb.save("sample.xlsx")
合并单元格
from openpyxl import Workbook, load_workbook
wb = load_workbook('sample.xlsx')
ws1=wb.active
ws.merge_cells('A2:D2')
ws.unmerge_cells('A2:D2') #合并后的单元格,脚本单独执行拆分操作会报错,需要重新执行合并操作再拆分
# or equivalently
ws.merge_cells(start_row=2,start_column=1,end_row=2,end_column=4)
ws.unmerge_cells(start_row=2,start_column=1,end_row=2,end_column=4)
wb.save("sample.xlsx")
插入一个图片
需要 pillow 库,安装如下:
pip install pillow
from openpyxl import load_workbook
from openpyxl.drawing.image import Image
wb = load_workbook('sample.xlsx')
ws1=wb.active
img = Image('1.png')
ws1.add_image(img, 'A1')
wb.save("sample.xlsx")
隐藏单元格
from openpyxl import load_workbook
wb = load_workbook('sample.xlsx')
ws = wb.active
ws.column_dimensions.group('A', 'D', hidden=True) # 隐藏A到D列
ws.row_dimensions.group(1, 10, hidden=True) # 隐藏1到10行
ws.row_dimensions[2].hidden # 获取第二行是否隐藏了
wb.save("sample.xlsx")
优化模式
在处理非常大的 XLSX 文件时,openpyxl 的常规模式无法处理这种负载。幸运的是,有两种模式可以在(几乎)恒定内存消耗的情况下读写无限量的数据。
只读模式
from openpyxl import load_workbook
wb = load_workbook(filename='large_file.xlsx', read_only=True)
ws = wb['big_data']
for row in ws.rows:
for cell in row:
print(cell.value)
只写模式
from openpyxl import Workbook
wb = Workbook(write_only=True)
ws = wb.create_sheet()
# now we'll fill it with 100 rows x 200 columns
for irow in range(100):
... ws.append(['%d' % i for i in range(200)])
# save the file
wb.save('new_big_file.xlsx') # doctest: +SKIP
- 与普通工作簿不同,新创建的只写工作簿不包含任何工作表;必须使用
create_sheet()方法专门创建工作表。 - 在只写的工作簿中,只能使用
append()添加行。使用cell()或iter_rows()在任意位置写(或读)单元格是不可能的。 - 它能够导出无限数量的数据(甚至比Excel实际能够处理的更多),同时将内存使用量保持在10Mb以下。
插入/删除行/列,移动区域单元格
插入行/列
在第7行之上插入一行,如下:
ws.insert_rows(7)
在第7列的左边插入一列,如下:
ws.insert_cols(7)
删除行/列
从第6列开始,删除3列,即删除6、7、8列,如下:
ws.delete_cols(6, 3)
移动区域单元格
将 D4:F10 区域向上移动一行向右移动2列,如下:
ws.move_range("D4:F10", rows=-1, cols=2)
如果区域内包含 公式 ,则如下方法可以连同公式一起挪动:
ws.move_range("G4:H10", rows=1, cols=1, translate=True)
使用 Pandas 和 NumPy
详情请移步 Working with Pandas and NumPy
图表
图表由至少一个系列的一个或多个单元格区域数据点组成。更多内容请移步 图表介绍
注释
openpyxl 可读/写注释,但格式信息会被丢失。在 只读模式 下不支持操作注释。注释必须包括 内容 和 作者 。
读注释,如下:
comment = ws["A1"].comment
comment.text # 注释内容
comment.author # 注释作者
写注释,如下:
comment = Comment("Text", "Author")
comment.width = 300 # 设置宽度
comment.height = 50 # 设置高度
ws["A1"].comment = comment
ws["B2"].comment = comment
表格样式
字体样式
字体名称、字体大小、字体颜色、加粗、斜体、纵向对齐方式(有三种:baseline,superscript, subscript)、下划线、删除线,如下:
from openpyxl.styles import Font
font = Font(name='Calibri',
size=11,
color='FF000000',
bold=False,
italic=False,
vertAlign=None,
underline='none',
strike=False)
ws['A1'].font = font
cell2.font = Font(name=cell1.font.name, sz=cell1.font.sz, b=cell1.font.b, i=cell1.font.i)
字体颜色可以用 RGB 或 aRGB ,如下:
font = Font(color="FFBB00")
font = Font(color="FFFFBB00")
继承并重写样式,如下:
ft1 = Font(name='Arial', size=14)
ft2 = copy(ft1)
ft2.name = "Tahoma"
填充样式
详情请移步 填充样式
from openpyxl.styles import PatternFill
# fill_type 的样式为 None 或 solid
cell2.fill = PatternFill(fill_type=cell1.fill.fill_type, fgColor=cell1.fill.fgColor)
边框样式
详情请移步 边框样式
from openpyxl.styles import Border, Side
border = Border(left=Side(border_style=None, color='FF000000'),
right=Side(border_style=None, color='FF000000'),
top=Side(border_style=None, color='FF000000'),
bottom=Side(border_style=None, color='FF000000'),
diagonal=Side(border_style=None, color='FF000000'),
diagonal_direction=,
outline=Side(border_style=None, color='FF000000'),
vertical=Side(border_style=None, color='FF000000'),
horizontal=Side(border_style=None, color='FF000000')
)
对齐样式
horizontal 的值有:distributed, justify, center, left, fill, centerContinuous, right, general
vertical 的值有:bottom, distributed, justify, center, top
from openpyxl.styles import Alignment
alignment=Alignment(horizontal='general',
vertical='bottom',
text_rotation=0,
wrap_text=False,
shrink_to_fit=False,
indent=0)
保护样式
锁定、隐藏
from openpyxl.styles import Protection
protection = Protection(locked=True, hidden=False)
整行或整列应用样式
col = ws.column_dimensions['A']
col.font = Font(bold=True)
row = ws.row_dimensions[1]
row.font = Font(underline="single")
更改合并的单元格样式
合并的单元格可以想想成为左上角的那个单元格来操作。
筛选和排序
from openpyxl import Workbook
wb = Workbook()
ws = wb.active
data = [
["Fruit", "Quantity"],
["Kiwi", 3],
["Grape", 15],
["Apple", 3],
["Peach", 3],
["Pomegranate", 3],
["Pear", 3],
["Tangerine", 3],
["Blueberry", 3],
["Mango", 3],
["Watermelon", 3],
["Blackberry", 3],
["Orange", 3],
["Raspberry", 3],
["Banana", 3]
]
for r in data:
ws.append(r)
ws.auto_filter.ref = "A1:B15"
ws.auto_filter.add_filter_column(, ["Kiwi", "Apple", "Mango"])
ws.auto_filter.add_sort_condition("B2:B15")
wb.save("filtered.xlsx")
生成的Excel表格,有筛选排序的操作,但是没有实际表现出效果,如下图:
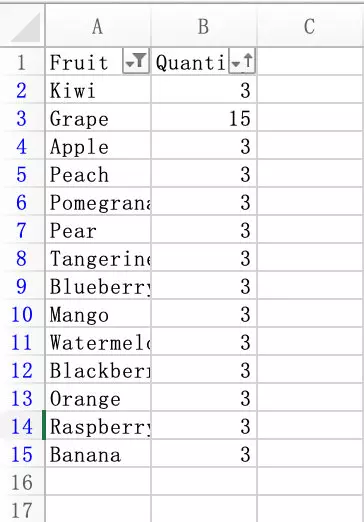
需要手动点击 重写应用 才能显示出效果,如下图:
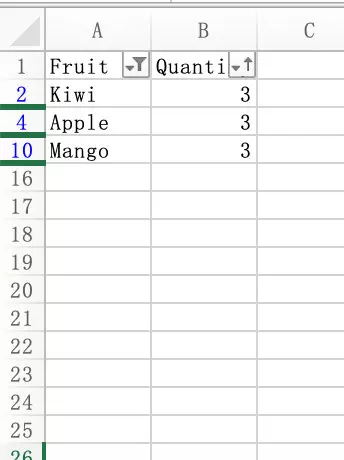
密码保护
该功能仅能提供一个很基础的密码保护,没有进行加密处理,网上普通的破解软件都可以破解password。不过,日常使用还是可以的。
该功能仅可用于新建excel表格,不能用于已存在的excel表格。
workbook工作薄保护
防止查看隐藏sheet,避免增加、移动、删除、隐藏或重命名sheet等操作,可以保护workbook的结构,如下:
wb.security.workbookPassword = '...'
wb.security.lockStructure = True
worksheet保护
worksheet保护不需要密码,如下:
ws = wb.active
wb.protection.sheet = True作者:潘高
链接:https://juejin.im/post/5cae014c6fb9a0686c0186df
来源:掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
