Linearizability
Linearizability并不是一个数据库专属的概念,Linearizability原本指的是在并发系统中,进程可以同时访问一个共享对象。由于多个进程正在访问单个对象,因此可能会出现这样一种情况,即当一个进程正在访问该对象时,另一个进程会更改其内容。使系统可线性化是解决这个问题的一种方法。在可线性化的系统中,尽管操作在共享对象上重叠,但每个操作似乎都是瞬间发生的。线性化是一个很强的正确性条件,它限制了当多个进程同时访问一个对象时可能的输出。它是一种安全属性,可确保操作不会以意外或不可预测的方式完成。如果系统是可线性化的,它允许程序员对系统进行推理。也就是说我们可以将并发的程序历史重新排序成一个或多个没有并发的顺序发生的历史,原始历史只能等效于其中的一个重排的历史则称其为可线性化的。
例1
thread1 : IA1----------RA1
thread2 : | IB1---|-----RB1 IC2--------RC2
| | | | | |
| | | | | |
real-time order: IA1 IB1 RA1 RB1 IC2 RC2
--------------------------------------------------->timeI代表invoke调用,R代表response响应,其对应的history为
H: IA1 IB1 RA1 RB1 IC2 RC2我们该如何判断结果是正确的呢?需要对h1进行所谓的推理,也就是重排,重排的规则为如果响应在原始历史记录中的调用之前,它必须在顺序重新排序中仍然在它之前。也就是说重排后的C一定是发生在A,B之后的,但是A,B的顺序谁在前谁在后都是可以的,因为C是在A,B响应后调用的,而A,B被看作是并发的。所以以下两个history都是正确的,h1符合任何一个结果都是可线性化的。
H_R1: IA1 RA1 IB1 RB1 IC2 RC2
H_R2: IB1 RB1 IA1 RA1 IC2 RC2说回数据库,类比重排的规则,一个符合linearizability的数据库应该满足如果一个事务 T1 在另一个事务T2开始之前提交,那么T1的提交的时间戳就比T2的小。这是spanner论文中对于“外部一致性”( external consistency,等同于linearizability)的定义,即两个在事务在数据库上能看到的顺序完全遵守客观现实中的发生顺序。
Serializability
串行化作为 ANSI SQL 标准提供的高隔离级别。它保证事务中的读和写就好像该事务在其执行期间被授予对数据库的独占访问权限,保证没有事务相互干扰。在非分布式数据库中,可串行化意味着事务的线性化,因为单个节点具有单调递增的时钟。如果事务 T1 在开始事务 T2 之前提交,则事务 T2 只能在以后提交。
但在分布式数据库中,如果系统中的节点具有不同步的时钟,则会出现违反 “因果相关”(因果关系并不是只有两个事务涉及重叠的key,才是有因果的,这是个宽泛的概念,只要一个事件发生在另一个之后,我们就可以说这两个事件是有因果关系的) 事务的顺序。假设有两个节点 N1 和 N2 ,以及两个事务 T1 和 T2 ,分别在 N1 和 N2 提交。因为我们没有参考单一的全局时间源,所以事务使用节点本地时钟来生成提交时间戳。假设 N1 有一个准确的时钟,但 N2 有一个时钟滞后 100ms。T1 在 ts=150ms 时提交。外部观察者(可以理解为上帝视角,从客观真是时间观察)看到 T1 提交,因此在 50 毫秒后(在ts=200 毫秒)开始 T2 。由于 T2 使用从 N2 的滞后的时钟,因此它在 N2_ts=100ms 时“在过去”提交。现在,任何在 N1 和 N2 上读取键的观察者都会看到相反的顺序,T2 的写入(在 ts=100ms 时)似乎发生在 T1 的(在 ts=150ms)之前。
Strict Serializability
Linearizability和Serializatbility是两个层面上的概念。
- Linearizability:单操作、单对象、实时排序
线性化是对单个对象的单个操作的保证。它为单个对象(例如分布式寄存器或数据项)上的一组单个操作(通常是读取和写入)的行为提供实时(即真实时间上的)保证。一旦写入完成,所有后续读取(在客观时间上后续发生)应该返回该写入的值。
- Serializatbility: 多操作、多对象、任意全序
可序列化性是对事务或对一个或多个对象的一个或多个操作组的保证。它保证在多个项目上执行一组事务(通常包含读取和写入操作)等效于事务的某些串行执行。
可串行化是ACID中传统的“I”或隔离。如果用户的事务每个都保持应用程序的正确性(“C”或 ACID 中的一致性),那么可序列化的执行也保持正确性。因此,可串行化是保证数据库正确性的一种机制。
与线性化不同,可串行化本身不会对事务的排序施加任何实时约束。可序列化性也不是可组合的。可串行化并不意味着任何类型的确定性顺序——它只是要求存在一些等效的串行执行。
Strict Serializability结合了Serializability和Linearizability:事务行为相当于串行执行,串行顺序对应实时。
cockroachDB一致性模型:小于Strict Serializability,大于Serializability
cockroachDB在事务隔离级别上实现了可串行化,并且做到了无陈旧的读(No stale-read),那么这能达到严格可串行化的标准吗?答案是否定的,因为No stale-read只能保证事务一定能读到已经提交的数据。尽管这个保证已经可以使分布式数据库达到CAP中的“C”了,但是仍然无法达到严格可串行化的标准。
例2:
T1 : select * from account;
T2 : insert into account values(1,100); commit;
T3 : insert into account values(2,200); commit;
T1 : commit;符合Strict Serializability标准的结果集如下:
- T1没有读到T2,T3插入的新值
- T1只读到T2,没有读到T3
- T1读到了T2,T3
然而No stale-read是允许出现非线性化的结果的:
- T1只读到T3,没有读到T2
因为T3真实时间上是发生在T2后的,所以在线性化下T1只能读到T2或者T1和T2。只读到T3的情况被视作不合符线性化的异常,crdb允许了这种不符合客观事实的异象,那么这种非线性化的异象会导致什么问题呢?
例3,张三正在网上冲浪逛论坛,此时李四在论坛发了条帖子,然后通知王五去看,王五看后觉得李四的观点不对,发了条反对李四观点的帖子,而此时张三却只看到了王五的反对帖,没有看到李四的原帖,不禁心中升起疑问,“你在和空气对线?”
解决方式:spanner vs cockroachDB
spanner和cockroachDB解决时钟偏差问题的方式不太一样,但本质上大同小异。
spanner 在写后等待, cockroach读时重试
spanner中所有的写事务都会延迟7ms后返回给客户端,而不阻塞读,7ms为true time的大不确定时间窗口,回看例3,如果使用了spanner的机制,李四的帖子写入后会等待7ms才被王五看到,所以王五的写时间戳一定是大于李四的。这个机制使spanner可以保证有因果关系的两个事务的时序,而cockroach只能保证有重叠key上读写事务的时序。spanner靠true time硬件技术的支持,使得每个写事务延迟一小会儿对性能不造成太坏的影响,而cockroach使用hlc时间,理论上的大大时间偏差上限500ms,无法也这么做。
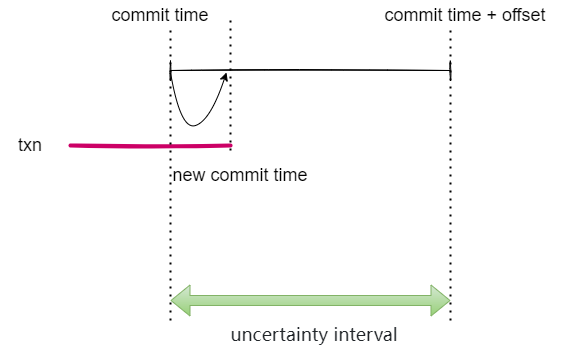
cockroach选择了在读时做检查,从这个读事务的临时提交时间戳向后扫描,读事务读到一个key的已提交版本时,会检查这个版本的提交时间戳是否落在了[commit timestamp, commit timestamp + maximum clock offset],这个区间就是不确定时间窗口。我们无法确定遇到的值是否在我们的事务开始之前提交。在这种情况下,我们只需执行 不确定性重新启动即可,使临时提交时间戳刚好高于遇到的时间戳。不确定性区间的上限在重启时不会改变,因此不确定性窗口会缩小。从许多节点读取不断更新的数据的事务可能会被迫多次重启,但永远不会超过不确定间隔,每个节点也不会超过一次。
补充:为什么每个节点多只会重启一次?如果在read发现有commit落在不确定时间戳窗口重启事务后,如果又有别的txn的commit在窗口内写入是否需要再次重启?实际上不会发生这种情况,因为crdb 的timestamp cache机制:在次不确定时间戳窗口重启后,timestamp cache更新到 >commit time + offset,再有冲突的写,时间戳一定会比它大。
