й“ҫжҺҘпјҡhttps://www.zhihu.com/question/312293421/answer/2294311618
across leadersйҮҢзҡ„leadersжҢҮзҡ„жҳҜиҝҷдёӘpaxosз»„зҡ„дёҚеҗҢд»»жңҹзҡ„leaderпјҢе®ғ们зҡ„lease intervalд№ҹдёҚдјҡеҸ‘з”ҹйҮҚеҸ пјҢе…¶е®һжҠҠиҝҷеҸҘиҜқиҝһиө·жқҘзңӢе°ұйҖҡйЎәдәҶпјҡ
within each Paxos group, Spanner assigns timestamps to Paxos writes in monotonically increasing order, even across leaders.
еңЁдёҖдёӘpaxosз»„дёӯпјҢSpannerз»ҷеңЁиҝҷдёӘpaxosдёӯеҸ‘з”ҹзҡ„еҶҷж“ҚдҪңпјҲpaxos writeпјүеҲҶй…Қзҡ„ж—¶й—ҙжҲідҝқжҢҒеҚ•и°ғйҖ’еўһпјҢеҚідҪҝиҝҷдёӘpaxosз»„еҸ‘з”ҹleaderеҲҮжҚўгҖӮ
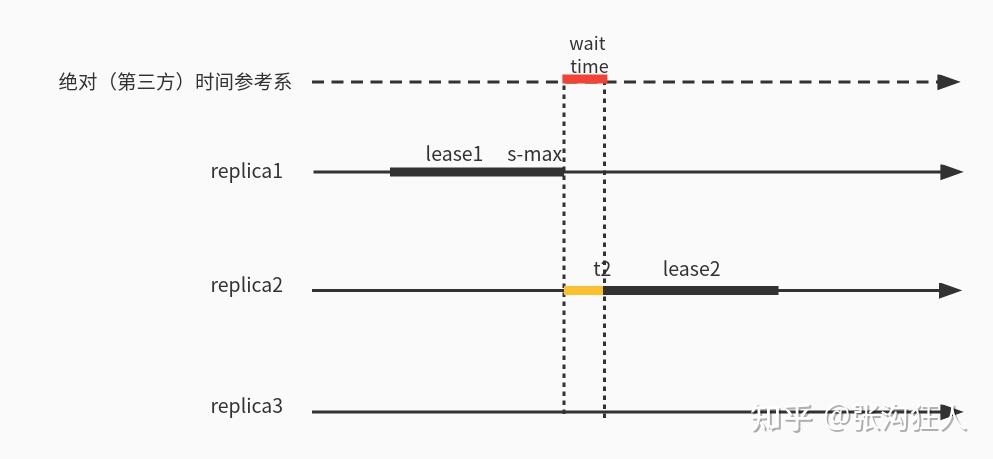
дё»иҰҒеҺҹеӣ жҳҜз”ұдәҺеҗ„дёӘжңәеҷЁзҡ„ж—¶й’ҹеҒҸ移пјҢеңЁеҸ‘з”ҹleaderеҲҮжҚўеҗҺпјҢеүҚдёҖдёӘleaderе’Ңж–°leaderзҡ„lease intervalеҸҜиғҪдјҡйҮҚеҸ пјҢе°ұеғҸдёӢйқўиҝҷж ·пјҡ
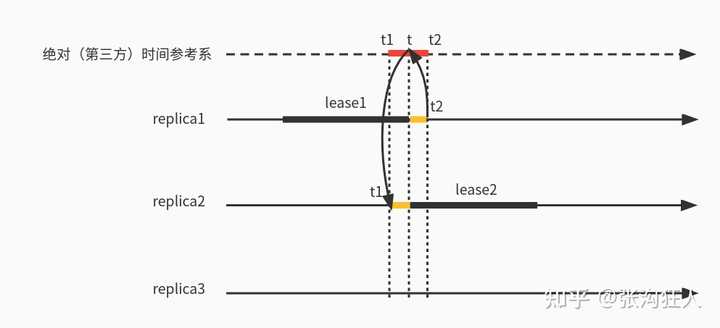
еңЁеҸ‘з”ҹйҮҚеҸ д№ӢеҗҺпјҢеӯҳеңЁзҡ„й—®йўҳе°ұжҳҜпјҢеңЁжҹҗдёӘж—¶й—ҙж®өпјҢдёҖдёӘpaxosз»„дёӯеӯҳеңЁдёӨдёӘleaderпјҢжҜ”еҰӮдёҠйқўзҡ„[t1, t2]пјҢиҝҷе°ұе·Із»ҸиҝқеҸҚдәҶpaxosеҚҸи®®гҖӮ
жүҖд»Ҙspannerи®©жҜҸдёӘleaderйғҪз»ҙжҠӨе·Із»ҸеҲҶй…ҚиҝҮзҡ„еӨ§зҡ„ж—¶й—ҙжҲі пјҢеңЁеҸ‘з”ҹleaderиҝҒ移时пјҢеҺҹleaderйҖҡиҝҮwaitпјҢи®©TT.now.earliest >
пјҢиҝҷж ·еңЁж–°зҡ„leaderдёҠеҲҶй…Қзҡ„ж—¶й—ҙжҲіе°ұз®—еңЁжһҒз«Ҝзҡ„ж—¶й’ҹеҒҸ移д№ҹдёҚдјҡе’ҢдёҠдёҖдёӘleaderзҡ„lease intervalеҸ‘з”ҹйҮҚеҸ пјҡ