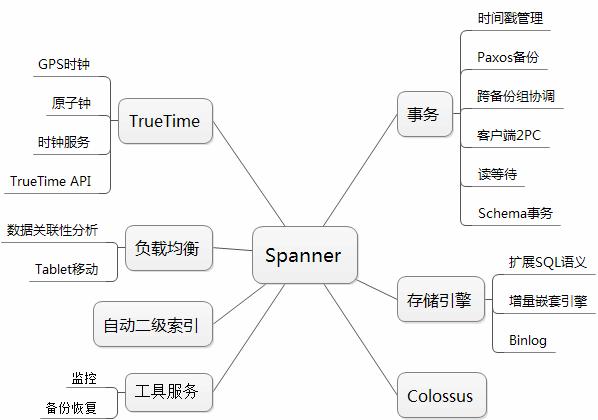
1 Spanner模型
1.1 部署模型
Spanner有一套复杂的数据部署模型,以下是论文中描述的一些关键单元
- directory(目录),是具有连续键值的数据集合
- fragment(目录片),是对directory按键值区间的切分,目的是防止directory过大,是指定部署分布的基本单元
- tablet,通过元数据进行管理多个不连续的directory,是副本管理的基本单元,即同一tablet中的数据具有相同的副本分布配置
- server,即spanner的物理服务器,存储多个tablet
- group,副本组,包含分布在多个server上的具有相同元数据的tablet,通过paxos达到数据一致。
- zone,是由同一数据中心中服务器组成的小范围集群,用于配置不同业务的物理隔离
- data center,数据中心,可看作集中部署的多个zone的物理集合
- universe,zone的逻辑集合,可能跨多个data center,Google使用universe分隔测试环境和线上环境
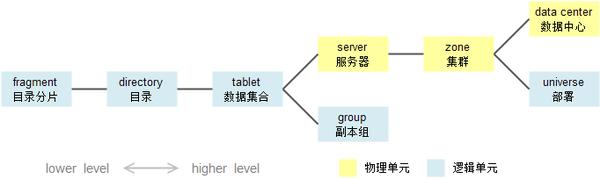
其中directory和fragment是由数据模型逻辑自然产生的(参见1.2节),Spanner使用后台进程(Movedir)不断重新调整directory和fragment在tablet中的部署,目的是使频繁同时查询的数据尽可能聚合在一起,因此一个tablet的元数据是可能发生变化的。
Spanner的另一套机制决定group中的tablet如何在server上分布,这套机制考虑的通常是全球容灾和用户访问延时问题,例如约束某个表的数据在北美保存2个备份、亚洲2份、欧洲1份。
1.2 数据模型
Spanner使用一种有Schema的嵌套数据模型,同时使用类SQL的语法作为访问接口,用论文中的例子来解释
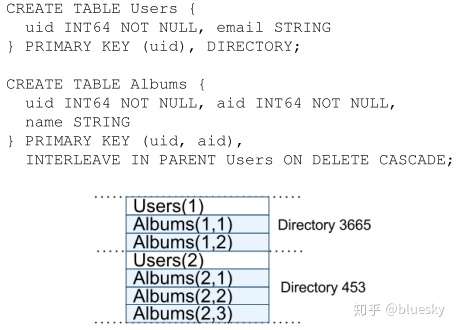
上面的两个SQL语句看似创建了两张表:Users和Albums,但实际上Spanner将它们合并存储。注意第二张表的建表语句使用了多主键:uid和aid,并且通过“INTERLEAVE IN PARENT …”语句表示uid与Users中的主键uid一致。这意味着,Album中的多条uid相同的记录,是嵌套在Users表的一条uid记录之下的。同一个user之下的所有子数据,就构成了一个directory。论文并没有描述表中的非主键如何存储,因此只能推测它们存储在所对应主键之后,即如下结构:
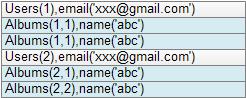
使用嵌套的数据结构,Spanner实现了相关联数据的合并存储,并且对于前面部署模型提到的后台directory迁移机制十分友好,属于同一Users下的所有记录可以同时取出。另外对于需要频繁使用两表主键join的操作,这种模型也能够大幅降低磁盘IO开销。论文中并没有具体说明,这样的嵌套模型是否具有层次深度是否仅限于2层,即是否能创建另一张表interleave in parent Albums。不过这在技术上并没有什么障碍。
关于存储模型,Spanner论文并没有给出具体的说明。考虑到时间戳和多版本的设定,个人推测Spanner采用了与BigTable和LevelDB类似的增量模型(毕竟它们都是由Jeffery Deam等几位大牛牵头的),该模型的特征是数据以增量的方式写入到存储介质,而非在原有存储空间上进行修改。至于如何基于增量模型实现嵌套型数据存储,也并不是一件简单的事情,开源NoSQL数据库还没有一个类似的产品,以后有机会专门写文章详细介绍。
2 TrueTime
2.1 分布式事务和时序
全球分布式和一致性事务,在现有架构下通常很难共存。前者要求读操作可以在任何一个节点进行(通常会选择里客户端近的节点),后者要求无论客户端链接到哪个节点,读取的数据都是一致的。我们列举2个场景说明同时实现两个要求是如何困难,以及为什么这些困难都与时序问题有关。
场景1:主备一致
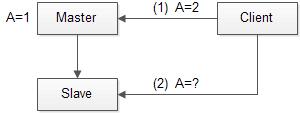
上图是主备一致问题的一个具体示例,客户端向Master节点提交(A=2)更新后,转向Slave节点查询A的值,此时Slave可能尚未写入更新的数据。要解决这个问题有两个思路:
- 强制要求写入是同步备份的
- 对Slave节点的读操作,能够判断数据是否足够新,否则阻塞读操作
已有的数据库经验表明,实现个思路的代价是巨大的。因为:1)有些的数据库写操作的代价较大,Slave节点强制同步写入会导致写延时增加。2)主备节点的连接并不可靠(全球部署和备份的系统更是如此),Master向Slave两阶段提交的任何时刻都可能发生故障。
而第二个思路,需要解决的问题是,数据写入和查询的新旧顺序如何确定?进一步,Master、Slave、Client三个分布式节点如何统一的描述一个具有顺序的逻辑?
场景2:跨库(或分区)事务原子性
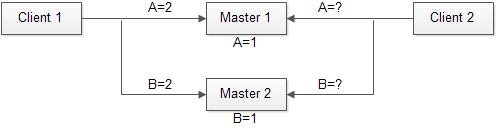
上图是跨库事务原子性问题的一个示例,Client 1节点提交一个写事务,向两个跨库或分区的Master节点分别提交对记录A和B的写操作。同时Client 2节点希望查询A和B的值。
在传统方法中,Client 2 的对A、B的读取必须封装到一个读事务中。这是因为:由于缺乏分布式的时序,Master 1和Master 2对数据的加锁必须是有次序的,如果来自Client 2的两个读请求不尝试也获得锁,它们就无法保证这两个读操作都发生在写事务之前或之后。有些场景下,读事务对性能可能造成严重影响。假设该模型描述的是一个商品数据,A和B是同一个商品的两个属性,但分布在两个表中,Client 1代表了商品的成交,Client 2则代表商品信息的查询。当查询的频率远高于成交操作,成交操作的性能将受到严重影响。
分布式数据中的Schema变更操作,可能更能说明跨库(分区)中的事务操作多么依赖分布式锁。传统分布式数据库需要对所有有关表加DDL锁,阻塞读写操作。在没有时序逻辑的系统中,一次全局加锁操作的时间代价是巨大的。就是说一旦需要更新Schema,传统分布式数据库就必须忍受一次长时间的全网业务中断。
2.2 TrueTime的技术基础
TrueTime是一套保持Spanner全球服务器的时钟“近似同步”的基础服务。它基于已有的全球精准计时技术:GPS时钟和原子钟。Spanner同时使用两种校时技术是有原因的。解释这个问题,需要先简单介绍两种时钟的原理:
- 原子钟利用原子的波长测量时间,科学领域通常使用的铯原子时钟,但成本也很高。而商用领域则使用精度和成本都较低的铷原子钟。无论哪种原子钟,都存在误差累积问题,即原子钟自然产生的误差是单调变化的,两个不同的原子钟授时差异会越来越大。
- GPS时钟的技术基础,仍然是每个GPS卫星上的两个互相校时的原子钟。GPS时钟终端可以通过连接多颗GPS卫星,通过算法屏蔽电磁波传输时延计算出相对时间。因此GPS时钟产生的误差是随机误差,即全球不同GPS时钟的时间虽然会呈现动态不一致,但误差不会越来越大。然而,GPS毕竟是第三方服务,并不能确信它在任何情况下都可用(例如发生大范围的卫星故障、电磁干扰等)。
综合以上原因,Spanner决定同时采用GPS时钟和原子钟,并且以GPS时钟为主。这样可以既避免计时误差问题,又保证了GPS失效时的可用性。 此外Google在论文中也透露了,原子钟与GPS时钟的成本在相同数量级,所以成本问题并不是Spanner选择的一个关键因素。
既然是工程角度的探讨,就需要再引申介绍一下,如何搭建基于GPS时钟(原子钟)的服务器。目前的校时商用设备,按授时的物理接口可分为以下几类:
- RS232,即9 pin口,现在的主机已经很少有这种接口了。
- PCI,插到服务器主板上即可,缺点是需要为每台服务器配置一个。
- 以太网,使用PTP/PTPv2(IEEE1558)作为校时协议,目前的商用设备的精度已经能够达到0.1us
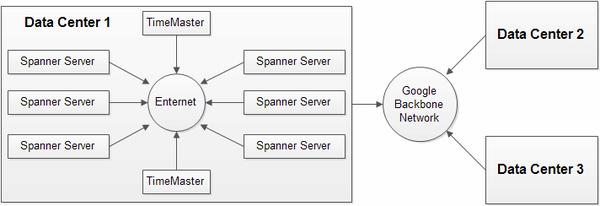
可以简单推测Spanner采用的是以太网PTP方式进行的网络校时,形成如下组网架构:
2.3 Time Master服务
Spanner的每个数据中心里都有一定数量的时钟服务器,其中多数是GPS时钟服务、少数是原子钟服务,它们被统称为time master。提供数据服务的主机称为spanner server。spanner server会周期性的选择若干time master进行网络校时。
- 同时链接不同距离的数据中心的多个time master,计算时间参考值
- 使用防欺骗算法,侦测和过滤撒谎的time master
- 若频繁出现本地时钟在校时周期内产生的误差过大,则主动退出Spanner服务
spanner server会周期性的将本地时钟调整到全球一致的值(时钟本身和校时产生的误差范围内)。但在相邻校时周期中间,它完全依赖本地时钟读取时间,在此期间由于本地时钟的不性,从而积累误差。Google提供的经验值是,一般情况下本地时钟每秒积累的误差不会超过200us,相当于1/5000的误差。以此经验值为前提,TrueTime可以通过调整spanner server的校时周期,保持这种误差小于一个特定的值。例如Spanner的周期设定为30秒,误差上限值被设置为7ms(大于30*0.2ms)。这个值被成为”误差参考值“,记作ε
可以简单的这样理解,Spanner保证每个服务器在任何时刻获取的时间,与“全球标准时间”相差不超过7ms。或者说任意两个Spanner服务器之间的时间误差不超过14ms。后面的分析会说明,这个大误差值越小,Spanner的事务性能将越高。Google在论文中也提到,缩短校时周期可以有效改善误差时间,个人推测目前使用的30秒周期可能是PTP服务本身的并发性能限制有关,因此增加Time Master的数量可以间接缩短该误差值。
由于定义了误差参考值ε,就可以定义TrueTime API三个接口
- now()
- 返回一个时间区间(tearliest, tlatest),使得tearliest<tabs<tearliest
- 论文中没有具体描述上下界的计算方法,显然若定义tearliest=tlocal-ε,tlatest=tlocal+ε是满足要求的。
- after(t)
- 当确定当前全球时间大于输入的时间记录时返回true,否则返回false
- before(t)
- 当确定当前全球时间大于输入的时间记录时返回true,否则返回false
举一个例子描述如何使用TrueTime控制分布式系统的时序,要求”节点A上执行事件e1的时间早于节点B上执行事件e2“
不使用TrueTime API的方法如下
- A执行e1
- A通知B
- B执行e2
使用TrueTime的方法如下:
- A、B协商时间戳t1、t2,其中t2-t1>2ε
- A根据本地时间在t1执行e1
- B根据本地时间在t2执行e2
证明:用tabs(e)表示时间e的执行时间,根据误差参考值定义,tabs(e1) < t1+ε, tabs(e2) > t2-ε,又因为t2-t1>2ε,所以tabs(e1)<tabs(e2)
3 分布式事务
3.1 时间戳
Spanner是一个具有多版本特征的数据库。它的每个小粒度的数据都具有一个时间戳属性。时间戳在数据写入时生成,并且遵循以下规则:
- 大于等于写操作起始时间 ,即ts>=t(eserver),其中eserver是节点接收到写操作的事件
- 小于等于写操作commit时间,即ts<=t(ecommit)),其中ecommit是写操作提交commit的事件
- 同一次写事务生成的时间戳保持一致
3.2 快照读和只读事务
Spanner读写操作的类型包括三种:快照读、只读事务、读写事务。
快照读是对历史数据的查询,的流程如下:
- 客户端指定一个时间戳ts
- 根据读请求和数据分布信息,选择与本次查询有关的副本组
- 客户端在每个group选择一个副本节点,分别发起查询请求,等待至全部完成
- 在每个所选副本节点上:
- 阻塞流程,直到时间戳ts同时满足以下条件
- 小于该节点在所有正在执行的读写事务中产生的时间戳(参见2.2节步骤6.2)
- 小于该节点paxos同步时间戳(参见2.3节)
- 执行读操作,执行成功后返回客户端,否则重试直到超时
快照读使用时间戳对数据进行筛选,客户端可以指定(过去、当前或未来)任意时刻时间戳进行查询,因此查询结果与请求提交的时间无关。Spanner具备查询过去某个版本数据的能力。
快照读引入了读等待所机制(步骤4.1),副本节点达到足够新的状态之后才完成读取,因此即使数据复制是异步执行的,也可以保证跨副本节点的读写一致性。正是由于快照读的事务一致性与副本选择无关,步骤1.2可以根据业务需要自行制定副本选择策略,不限于以下几种:
- 优先选择ping低的节点,保证通信延时小化
- 优先选择负载轻的节点,保证多副本节点负载均衡
- 优先选择leader节点,保证读流程阻塞小化
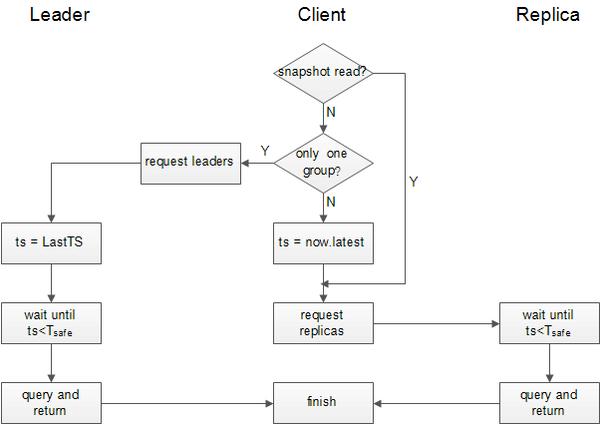
只读事务针对客户端没有指定时间戳的情况,默认含义是查询当前时刻数据,具体流程如下:
- 选择查询节点,同快照读步骤1
- 客户端判断读操作是否只在一个group内部
- 如果是
- 客户端请求该group的Leader节点,发起查询请求并等待完成
- Leader节点将读操作时间戳ts指定为LastTS
- 如果否
- 客户端将读操作时间戳ts指定为now.latest
- 客户端在每个group选择一个副本节点,分别发起查询请求,等待至全部完成,同快照度步骤3
- 被查询的节点执行读操作并返回,同快照读步骤4
只读事务区分读操作是否在一个group的意义在于,面向多节点读操作需要统一时间戳,这种情况下,由客户端指定时间戳的消息通信代价是小的。而对于只需要在一个节点上执行的读操作,LastTS(接受消息时刻后的写事务时间戳)会比now.last要小,特别是该tablet近一段时间没有写入数据的情况,Spanner针对这种场景将生成时间戳的权利交给Leader节点,能够很大概率降低读阻塞时间。
由于spanner服务端节点引入了读阻塞机制,只读事务和快照读不需要使用锁。
3.3 读写事务
读写事务的流程如下:
- 获取相关Leader节点的读锁
- 如果需要读操作,快照读(仅选择leader节点)
- 客户端确定写操作的所有副本组,选择一个coodinator-leader
- 论文并没有给出选择方法,因此流程对任意的选择方法都是兼容的。
- 如果客户端只确定了一个副本组,则该副本组的leader即为coodinator-leader,以下流程跳过步骤5.2和6
- 客户端生成需要写入的数据,分别发送给所选择副本组的leader节点(消息中包含所选coodinator-leader的信息)
- coodinator-leader节点执行以下操作:
- 获取写锁
- 等待所有非coordinator-leader的消息
- 确定本次事务终的时间戳ts,遵循以下三个规则
- 大于所有其他leader消息中的时间戳
- 大于收到它收到客户端消息时的now().latest(为了满足时间戳规则1)
- 大于本节点所有已使用的时间戳
- 将客户端提交的数据,通过paxos写入到副本binlog日志
- commit等待:阻塞流程直到after(ts)==true(为了满足时间戳规则2)
- 本地并通知slave节点提交commit
- 释放写锁
- 通知客户端写操作完成,同时通知非coordinator-leader进行commit
- 非coodinator-leader节点执行以下操作:
- 获取写锁
- 确定准备时间戳,大于本节点所有已使用的时间戳
- 将客户端提交的数据,通过paxos写入到副本binlog日志
- 通知coordinator-leader
- 等待coordinator-leader的消息
- 讲binlog时间戳改为coordinator-leader确定的时间戳ts(为了满足时间戳规则3)
- 本地并通知slave节点提交commit
- 释放写锁
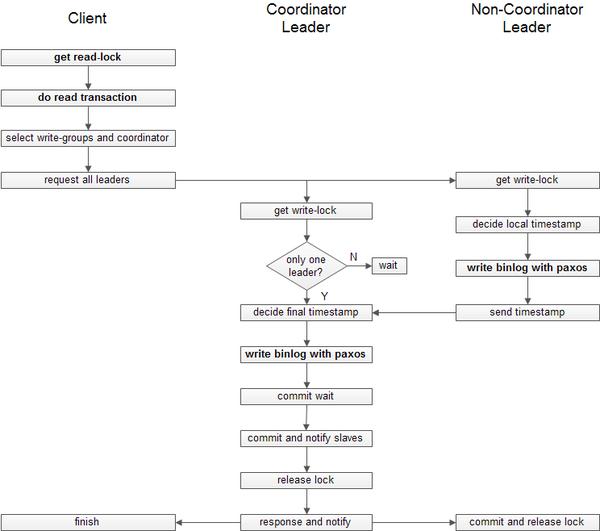
Spanner论文对读写事务中锁的描述比较简略,遗留了许多问题需要填补:
- 锁的粒度是如何的?
- 论文暗示锁粒度小于tablet大于单行记录,但具体是directory、fragment或者其它粒度,文中并没有具体解释,我们暂时按粒度为fragment理解
- 如何选择加锁对象?
- (基于推测)客户端会分析读写操作,判断本次操作涉及哪些主键区间,然后计算出所对应Leader节点上的fragment,然后加锁。注意步骤1的读锁和步骤5、6中的写锁加锁对象可能是不同的,但加读锁的fragment集合必须包含加写锁的fragment集合。
- 死锁问题?
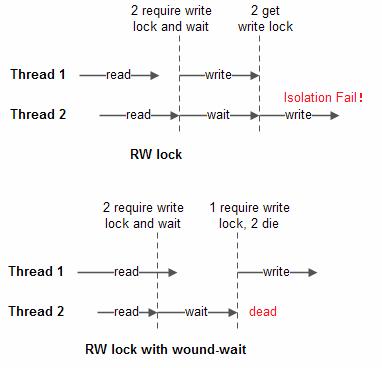
- Spanner论文中提到了使用”wound-wait“(受伤-等待)策略防范死锁。简单回顾wound-wait策略:1)当较新的任务尝试获得锁,等待直到锁释放。2)当较老的任务尝试获得锁,结束较新任务。(基于推测)Spanner使用读写事务中读操作的时间戳比较任务的新旧。因此当客户端尝试为分布在多个节点上的fragment加锁时,可通过本次时间戳比较任务的新旧,从而决定该读写事务是否等待或这终止。
- 使用读写锁,如何保障事务的隔离性?
- 回顾以下读写锁机制:1)读锁之间不互斥、2)读锁与写锁,以及写锁之间互斥。对于仅仅是简单的读写锁方案,如下图a所示,当线程1和线程2先后启动读写操作且并行执行,在阶段两个线程同时获得了读锁,读到相同版本的数据,第二阶段由于写锁互斥先后执行。线程2的写操作出现了“脏读”,将了线程1的数据,破坏了事务的隔离性?
- 不过wound-wait策略除了解决死锁之外,实际上该机制也保证了前面描述的脏读现象不会发生。如下图b所示。当线程2完成读操作尝试获得写锁,此时线程1仍然持有写锁,因此进入等待。当线程1开始写操作,尝试获得写锁,线程2由于任务较新则直接终止了任务(并不是终止线程)。
读写事务的步骤5.4和6.3是一个复合步骤,涉及Leader节点与Slave节点之间交互,参见3.5节。
3.4 Leader租约
在一个group中tablet备份分布在不同节点上,其中一个称为Leader节点,其余称为Slave节点,它们都称为副本节点(replica)。为了降低开销,Spanner采用Multi-Paxos协议进行数据备份。但这个协议会产生一个问题,当Leader节点需要重新选举的时候,可能多个节点同时认为自身是Leader,这将破坏Spanner读写事务中的其它一些设定。因此Spanner必须作出更严格的约束,任何时刻只有一个节点认为自己是Leader。
为了保证异常状况下的Leader及时重新选举,以及避免选举造成过重的开销,Spanner采用有租约的Leader管理机制,时长默认是10秒,即一个节点确认获得授权之后10秒可以认为自己是Leader节点。为了避免Leader节点闪断后重新回到group时出现新旧Leader共存,在一个Leader租约时间内,重新选举新的Leader也是不允许的。另一个问题是,不同节点对于租约起止时刻的判断误差,也可能造成短暂的新旧Leader共存,Spanner使用TrueTime API避免这一点。具体流程如下:
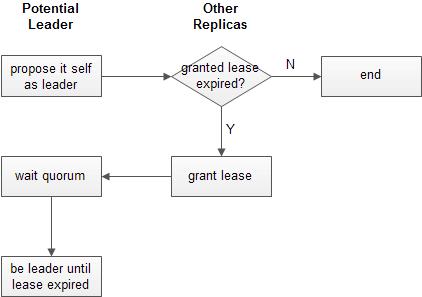
- 一个Replica试图成为Leader时,向所有replica节点r发送租约请求,每次消息发送之前调用TrueTime,记录tleader,r=now().latest
- 当节点r接收到租约请求消息,判断上一次发出的租约投票是否超期,如果未超期则流程结束,否则执行步骤3
- 返回一个租约投票,并记录租约起止时间为now().latest到now().latest+10秒
- 当发起租约请求的节点接收到多数replica节点的租约投票,则成为leader,它所记录的租约时间起止时间为now().latest到minr(tleader,r)+10秒,并使用before(minr(tleader,r)+10)判断是安全的判断当前时刻是否在租约之内。
上述流程中,不同节点维护的租约时间不同,而leader节点则取了大多数节点租约投票时间的交集,从而保证不与前后产生的leader节点产生租约时间的重叠。具体的证明可以参见原文附录A。
Spanner还引入了租约延长机制,进一步避免leader重新选举代价,包含显式和隐式两种方法(具体的流程并未说明):
- 当发生一次写操作,隐式延长租约
- 租约即将结束时,显式延长租约
注意到Leader节点延长租约所需的多数节点并不需要是固定的,也就是说当它拥有任意多数节点的租约投票,即可延长Leader租约。
另外,Leader选举流程可能存在活锁问题,即多个replica节点同时试图成为leader时,由于没有一个达到多数replica投票,流程反复启动和终止。特别是步骤2要求投票后的租约时间内不再进行投票,产生一次活锁将导致10秒内Leader无法选举产生。不过虽然论文中没有提及,相信Spanner已经采用了其它机制规避该问题。
3.5 Paxos数据复制
Spanner Leader利用Paxos进行binlog数据复制,每个paxos实例中决议的对象是下一条binlog记录,流程如下:
- Leader将数据写入自身的binlog
- Leader将数据发送给Slave
- 接收到消息的Slave将数据写入自身的binlog,并返回消息
- Leader等待直到超过半数的Slave返回
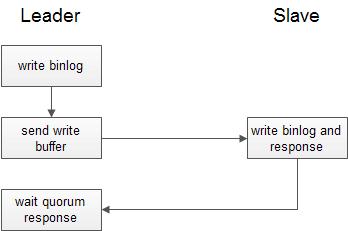
上述数据复制过程仅仅保证binlog数据的主备一致性,因此不涉及数据commit和commit wait,它们交由读写事务流程完成。
3.6 Schema变更
Spanner的Schema变更事务流程如下:
- 确定一个未来时间戳t,显式大于所有server的收到并确认执行的时间
- 将schema事务发送到所有节点,
- 每个节点根据schema事务,生成新版本的schema(与旧的schema并存),按照如下方式执行读写操作
- 对于时间戳小于t的读写操作,使用就版本schema执行
- 对于时间戳大于等于t的读写操作,阻塞直到需要after(t)为true,然后使用新的schema执行
Spanner不再需要接收到DDL操作之后开始逐步阻塞所有节点上的读写操作,直到确认所有节点进入阻塞状态再确认执行schema变更。TrueTime保证了,在时刻t所有节点都处于阻塞读写操作状态,而小于2ε时间之后所有节点自行恢复读写,从而将节点阻塞读写操作的时间降至低。
来源 https://zhuanlan.zhihu.com/p/270606437
