
作者介绍
钱芳园,专注数据库和数据库自动化领域的工程师,擅长MySQL、Redis运维以及基于go语言的数据库自动化开发。
一、背景
所谓 MySQL 慢查询,是指在 MySQL 中执行时间超过指定阈值的语句将被记录到慢查询文件中,它是我们 DBA 经常讨论的话题。
但在慢查询方面,做得更多的工作,基本都是集中做一个慢查询平台,可以很好的把慢查询收集起来,然后管理起来,方便查看各种信息,方便和开发沟通,方便看慢查询的发展趋势等等。但这些工作,对于解决慢查询来讲,作用比较小,因为久而久之,当我们成功地把慢查询平台变为慢查询海洋时,不管是开发,还是 DBA ,都不知道我应该要去解决哪个慢查询了,再加上,解决一个慢查询,本身其周期非常长,比如涉及到发现慢查询、分析并优化慢查询、测试优化效果、修改业务代码、发布上线以及观察效果等等。这么长的流程,这么长的周期,很明显给我们解决慢查询造成了非常大的阻力。
慢查询太多,对于业务而言,是有很大风险的,可能随时都会因为某种原因而被触发,并且根据我们的经验,数据库常出现的问题,都是因为慢查询导致数据库慢了,进而导致整个实例雪崩,从而导致了线上故障。
从另外一个角度来考虑,解决慢查询,是业务和 DBA 双方面的问题,但通常情况下,业务并不关心自己使用的数据库是不是有慢查询,只关心数据库是不是能返回正确的数据,对数据库造成什么影响,并不太关注。而这个时候, DBA 只能去“被动接受”,并且只能是在问题出现之后,再去讨论解决相应的问题。
可能有人会问,有慢查询,难道 DBA 不知道吗?为什么不提前解决,非要等到出了问题才解决,这个问题,就是本文今天的主题,我们如何把被动解决,变为主动。
二、分析
根据上面的背景讲述,我们其实知道,为什么不能提前把问题发现并解决呢?主要原因是, DBA 面对慢查询的海洋时,并不能有效地知道,每个慢查询对业务影响的严重程度,再加上解决慢查询的周期很长,可能针对一个慢查询,从开始到解决完成,需要跟踪半个月都不止,从而造成了慢查询的被动解决,成为 DBA 内心的痛。
所以,其实根本的原因是慢查询太多,同时慢查询没有明确的优先级,不知道我们先应该要解决哪个慢查询,业务同学也是不知道的。虽然有平台可查,但他们在面对大量的慢查询时,解决的意愿就不是太高,终慢查询也越积来越多,直到后影响业务运行。
所以,有效的解决办法就是,需要建立一种评分机制,将当前慢查询系统中的慢查询进行评分,按照分数给出优先级,然后根据优先级,将慢查询信息推送给对应的业务方,要求他优先解决可能会对线上产生严重问题的慢查询,再逐步解决次优先级的慢查询,以此类推。
三、解决思路
通过建立一套评分的模型,给定任何一个慢查询,根据慢查询的关键属性,计算出分数。假定总分数为100,分数越高则风险指数越高。
评分模型可以简单描述为:
score=func(x)选取评分项
慢查询主要因素是由查询次数( QueryCount )和查询其他各项指标(例如锁等待时间、扫描行数、查询时间、发送数据等)组成。
查询次数
一个慢查询如果执行时间为 1s ,查询次数(QueryCount)为 1 和查询次数为 1000 时,对系统的影响不同,次数越多危害越大,量变会引发质变。QueryCount 正确的值是这个慢查询当天执行的的大执行次数。但是预测未来并不可靠,对于线上业务没有人会准确知道下一时刻的查询次数会有多少,故我们使用昨天的数据,通过计算出单个时间窗口内的执行次数的大值,来计算出这个慢查询对当前系统的影响。单个时间窗口选取太小,比如 10s 、1min 等计算出来的 QueryCount 会太小,并不能清楚的反应指标的危害程度;如果选取太大,比如 30min,1hour 会造成计算出来的 QueryCount 太大,显得指标的危害程度非常高。故我们选取 10min 作为一个参考值,通过以 10min 为窗口,滑动计算出 QueryCount 的大值,作为慢查询评分模型的指标之一。
查询其他各项指标
慢查询各项因素主要是由慢查询日志中记录的各项指标。
mysql的慢查询说明,慢查询示例
# Time: 210818 9:54:25# User@Host: fangyuan.qian[fangyuan.qian] @ [127.0.0.1] Id: 316538768# Schema: Last_errno: 0 Killed: 0# Query_time: 3.278988 Lock_time: 0.001516 Rows_sent: 284 Rows_examined: 1341 Rows_affected: 0# Bytes_sent: 35600SET timestamp=1629251665;SELECT a.ts_min AS slowlog_time, a.checksum, SUM(a.ts_cnt) AS d_ts_cnt, ROUND(SUM(a.Query_time_sum), 2) AS d_query_time, ROUND(SUM(a.Query_time_sum) / SUM(a.ts_cnt), 2) AS d_query_time_avg, a.host_max AS host_ip, a.db_max AS db_name, a.user_max AS user_name, b.first_seen AS first_seen_time FROM mysql_slowlog_192_168_0_84_3306.query_history a force index(idx_ts_min), mysql_slowlog_192_168_0_84_3306.query_review b WHERE a.checksum = b.checksum AND length(a.checksum)>=15 AND ts_min >= '2021-06-04' AND ts_min < '2021-06-21' GROUP BY a.checksum;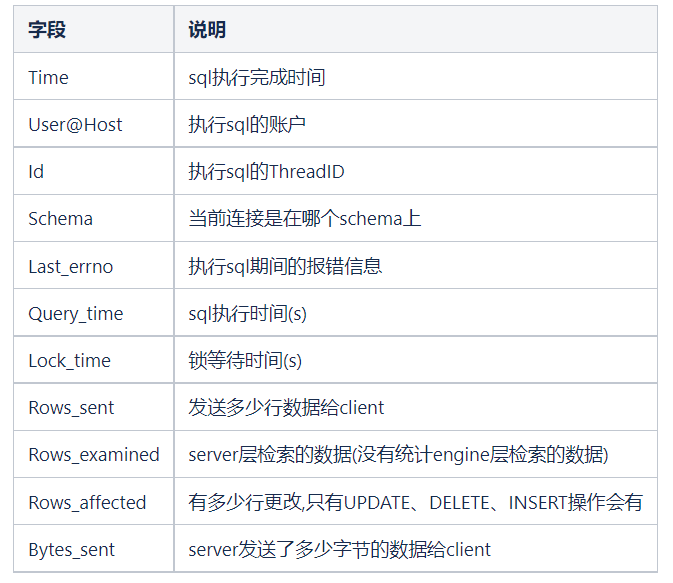
选取评分项
其中 Time、User@Host 、Id、Schema 、Last_errno 都是描述性的信息不会造成查询变成慢查询;
Query_time 是真实记录慢查询的查询时间,查询时间越长对系统的影响越大;
Lock_time 是当前查询获取数据时获取记录锁而等待的时间,等待时间越长,越可能造成慢查询;
Rows_sent 是发送多少行数据给 client ,同一个查询语句发送的数据行数越大,越可能会造成慢查询;
Rows_examined 是 server 层检索的数据,检索的数据越多,需要的IO和cpu资源也就越多,越可能造成慢查询,并影响服务稳定性;
Rows_affected 只针对修改请求,由于绝大部分慢查询都是 select ,并不会修改数据,故此值可以忽略;
Bytes_sent 是发送多少字节数据给 client ,发送的数据量越多,越可能会造成慢查询;
由于不同的表行大小不同,并且并不是所有列都需要返回,所以一个发送 10 行的数据,可能会比一个发送 100 行数据的查询更慢,Rows_sent 不如 Bytes_sent 更为直观,故我们选取 Bytes_sent ,忽略 Rows_sent 。
所以,慢查询指标中 Query_time、Lock_time 、 Bytes_sent 、 Rows_examined 作为慢查询评分模型中的指标。
综上所述,慢查询评分项共有五项,分别是QueryCount、Query_time、Lock_time、Bytes_sent、Rows_examined。
评分模型可以简单描述为:
score=sum(评分项*权重)选取评分项边界
评分模型的评分项确认之后,为了防止单项分数过高,需要对评分项进行百分化,并且所有权重总和为 100 ,根据评分项计分模型可以算出符合增长曲线的分数,这样评分模型计算出来的总分数为 100 ,故需要确认每项的分数边界、权重、计分模型。只有各项的边界、权重、计分模型确认之后,给定一个慢查询,评分模型才能计算出合理的分数。评分项的边界可以根据当前历史数据设置。计分模型和权重可以首先进行假设,测试完成之后如果不符合预期则修改权重、计分模型,并重复测试-修改过程,直至测试结果符合预期。
边界选取标准
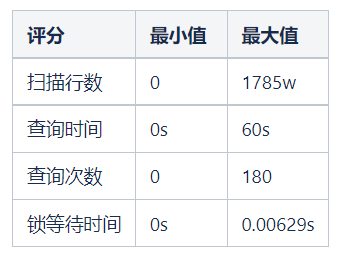
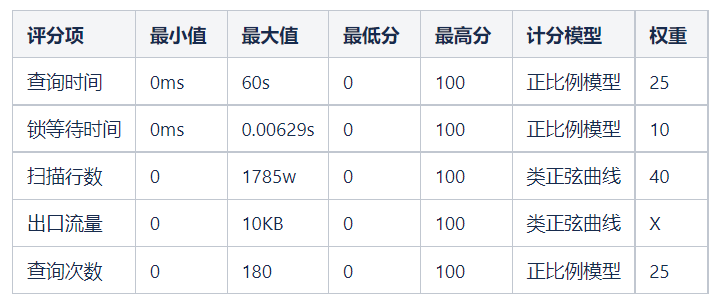
根据当前慢查询的历时记录,由于极值数据可能会存在干扰,导致真实值失真,故需要去除高部分 5% 的异常值,将 95 分位的值作为每个评分项的高边界。如果单项值超过高边界的值评分项,单项分数都将被设置为大分数。
查询时间:

95 分位的 sql 慢查询耗时约在 60s 左右
锁等待时间
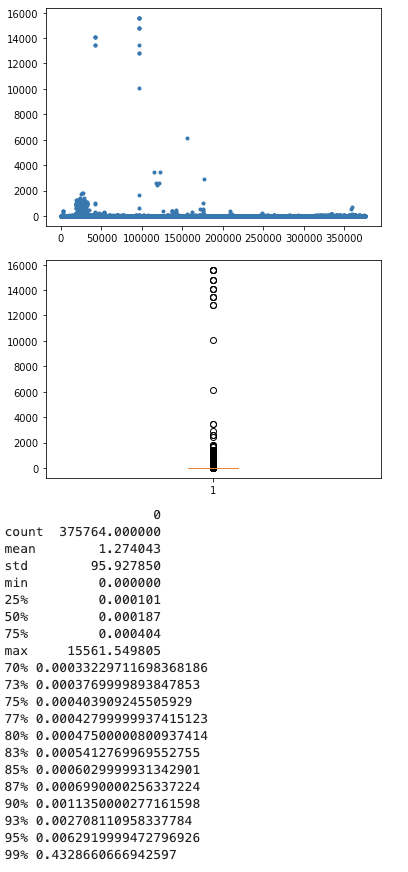
95分位的慢查询锁等待时间约为0.00629s
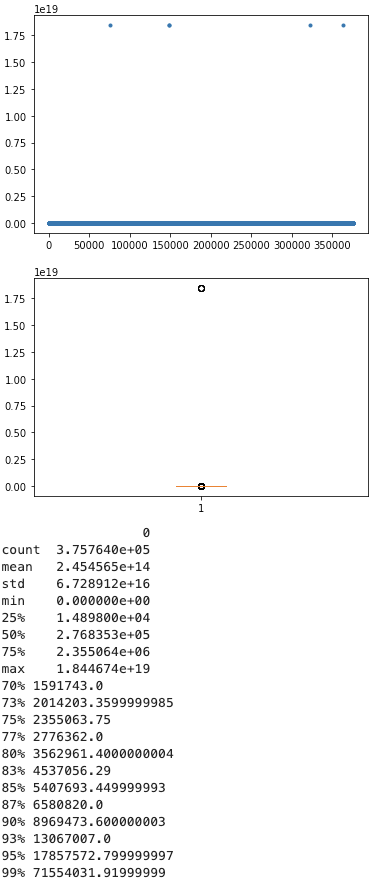
扫描行数
查询次数
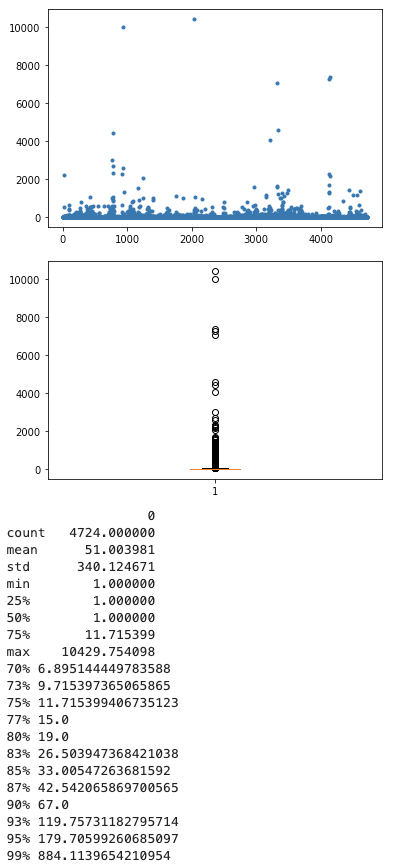
95分位的慢查询次数约为180个
发送流量
由于流量字段缺失,暂时不计入评分系统。
计分项边界值
计分模型
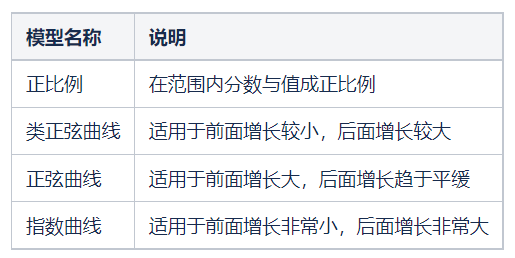
每一项计分项的边界得以确认,值越大分数越高。但是存在以下情况:
某些评分项的值对系统的影响程度并不是成正比例,超过某个临界点,对系统的压力会迅速增长。
比如:查询次数,一条超时为1s的sql,查询1次、查询10次、查询100次,对系统的压力是不一样的,量变会引发质变。
设计有一下四种计分模型:
计分代码如下:
/** * @Description: 计算单项得分,分数介于小分数和大分数之间,可选的计分模型有:类正弦模型、正弦模型、指数模型、正比例模型 * @Param val: 单项当前值 * @Param minVal: 单项小值 * @Param maxVal: 单项大值 * @Param minScore: 单项小得分 * @Param maxScore: 单项大得分 * @Param calWay: 计分模型方式 * @Return float64: 单项得分 */func calSingleScore(val, minVal, maxVal, minScore, maxScore float64, calWay string) float64 { if maxVal == { // 如果值为0则返回0 return } if val >= maxVal { // 如果值超过上边界,则设置为大分数 return maxScore } if val <= minVal { // 如果值低于下边界,则设置为小分数 return minScore } var scoreRatio float64 switch calWay { case "likeSin": // 类正弦曲线 // Y = a + b·X + c·X2 + d·X3 + e·X4 + f·X5 b := .0547372760360247 c := -.0231045458864445 d := .00455283203705563 e := -.000281663561505204 f := 5.57101673606083e-06 // 使用20个函数绘制点位拟合出来的 ratio := (val - minVal) / (maxVal - minVal) * 20 scoreRatio = b*ratio + c*(ratio*ratio) + d*(ratio*ratio*ratio) + e*(ratio*ratio*ratio*ratio) + f*(ratio*ratio*ratio*ratio*ratio) case "sin": // 正弦曲线 ratio := (val - minVal) / (maxVal - minVal) scoreRatio = math.Sin(math.Pi / 2 * ratio) case "exponent": // 指数曲线 ratio := (val - minVal) / (maxVal - minVal) a := math.Log2(maxScore - minScore) scoreRatio = math.Pow(2, a*ratio) return scoreRatio default: // 默认是正比例 scoreRatio = (val - minVal) / (maxVal - minVal) } return scoreRatio * (maxScore - minScore)}
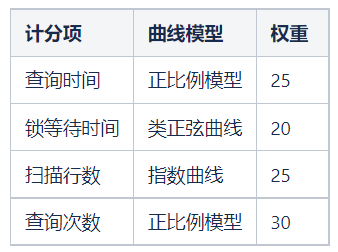
我们期望某些计分项在各个不同的阶段对分数的影响是不一样的,故首先假设计分模型和权重如下:
整体的评分模型如下:
慢查询风险指数 = sum(func(慢查询评分项) * 权重)ps:风险指数总分数上限为100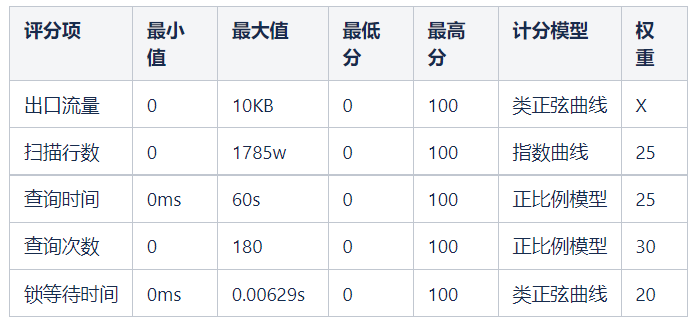
五、测试
测试一
权重分配
计算结果数据分布
样本SQL分析

不符合的原因:扫描行数越多对系统的影响越大,所需要的 IO 和 CPU 资源也就越多,系统处于无响应状态的几率越大,其影响比例应该要远高于其他评分项。我们期望扫描行数越多,分值越高,越需要关注,故需要调整各个评分项权重和计分模型。
测试二
权重分配
重新分片权重并修改计分模型之后,整体模型如下:
计算结果数据分布
样本sql分析
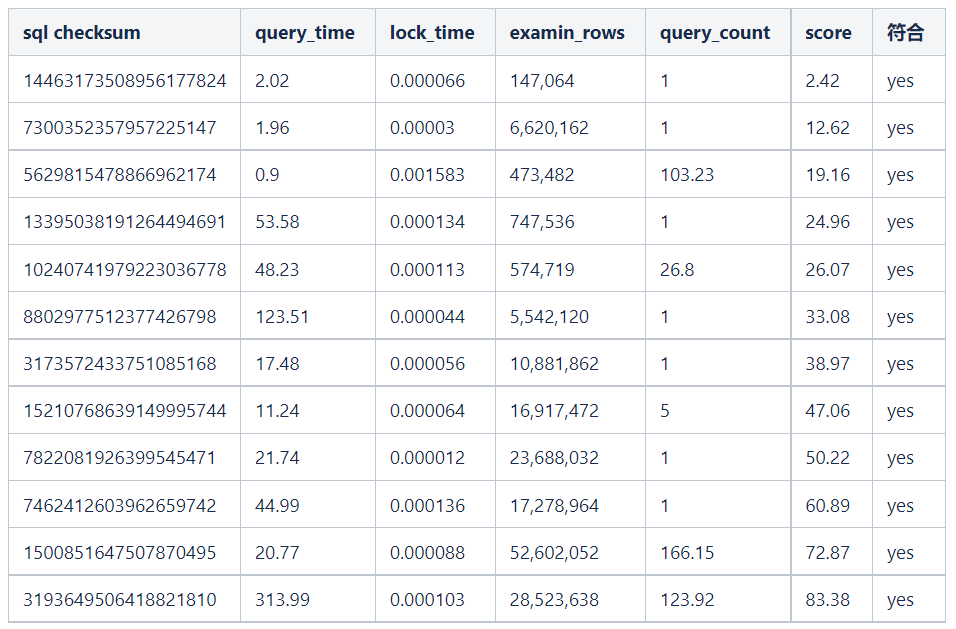
六、结论
评分模型
采用权重分配二,需要重点关注所有分数为50以上的慢查询。
七、展望
更合理的评分模型
percona sever/mariadb 版本的mysql可以有更丰富的统计项
percona server/mariadb的慢查询示例
# Time: 210818 9:54:57# User@Host: fangyuan.qian[fangyuan.qian] @ [127.0.0.1] Id: 316541341# Schema: Last_errno: 0 Killed: 0# Query_time: 2.777965 Lock_time: 0.000289 Rows_sent: 284 Rows_examined: 1341 Rows_affected: 0# Bytes_sent: 35600 Tmp_tables: 1 Tmp_disk_tables: Tmp_table_sizes: 1044920# InnoDB_trx_id: 52AFB919# QC_Hit: No Full_scan: Yes Full_join: No Tmp_table: Yes Tmp_table_on_disk: No# Filesort: Yes Filesort_on_disk: No Merge_passes: # InnoDB_IO_r_ops: InnoDB_IO_r_bytes: InnoDB_IO_r_wait: 0.000000# InnoDB_rec_lock_wait: 0.000000 InnoDB_queue_wait: 0.000107# InnoDB_pages_distinct: 1862SET timestamp=1629251697;SELECT a.ts_min AS slowlog_time, a.checksum, SUM(a.ts_cnt) AS d_ts_cnt, ROUND(SUM(a.Query_time_sum), 2) AS d_query_time, ROUND(SUM(a.Query_time_sum) / SUM(a.ts_cnt), 2) AS d_query_time_avg, a.host_max AS host_ip, a.db_max AS db_name, a.user_max AS user_name, b.first_seen AS first_seen_time FROM mysql_slowlog_192_168_0_84_3306.query_history a force index(idx_ts_min), mysql_slowlog_192_168_0_84_3306.query_review b WHERE a.checksum = b.checksum AND length(a.checksum)>=15 AND ts_min >= '2021-06-04' AND ts_min < '2021-06-21' GROUP BY a.checksum;与业务相结合
针对不同的业务,需要关注的慢查询风险指数也应该是不一样的,核心业务的慢查询风险指数应该比较低。不同的业务之间慢查询风险指数相同的其表示的影响程度也不一定相同。故引入一个「业务等级权重」,目的是将所有业务的慢查询风险指数量化为同一个标准。高优先级的业务其「业务等级权重」也会越高,低优先级的业务其「业务等级权重」也会越低。按照appCode维度,将每个appCode的慢查询TopN发送给业务方,指数越高业务应该越优先处理。同时需要设置慢查询平台的「慢查询风险安全指数」水位线,超过这个水位线的所有慢查询都需要关注。
终慢查询风险指数 = 慢查询风险指数 * 业务等级权重八、总结
通过我们的慢查询分级模型,可以很好的把一个慢查询抽象化为一个具体的数字,将其数字化,给我们的运维带来了非常大的便捷性,这个数字,我们可以称之为“慢查询业务风险指数”。
有了数字化慢查询,我们就可以很好地去界定一个慢查询是不是真的有风险,或者风险有多大,这样就可以以上帝视角的方式,来管理所有的慢查询, 这样自上而下地去解决问题,相比让DBA整天盯着一个个具体的慢查询去解决的话,效率会非常高。
根据我们抽象化出来的风险指数(慢查询业务风险指数),我们可以按照一定的周期,将风险大的慢查询,推送给对应的具体的负责人,然后不断地解决,不断地迭代,终实现解决慢查询从“被动”到“主动”的完美转换。
我们终的目标是,让所有慢查询的风险指数的中位数,或者90%、70%分位数,不断地下降,终处于一个良性的状态
