传统上建设一个博客网站需要:一个反向代理Nginx、一个应用服务、一个数据库MySQL,就能建立起来标准的WEB站。
博客现在每天新增3000多的文章量,速度已经很慢,如果后期我要做一个app数据量肯定更大,到时该怎么保证访问速度
上面的问题是博客网站在传统架构下经常遇到遇到性能瓶颈期!如果每天3000多的文章量就存在慢的问题,就要考虑架构的适量改进了。
传统架构的优化
那么是否增加并均衡负载多个应用服务可以提升并发请求响应速度。同时考虑加入Redis,提升读取性能呢?当然了,这是必经之路!

上图是我们常用的一种传统架构模式,Nginx作为均衡负载,客户端和Web容器进行无状态的请求和响应,Nginx与Web容器的负载保持IP模式,主要是满足web session。这个过程若产生Web 容器压力,增加服务器即可,但是往往压力并不在此处,而是来自数据库。因此下一步可以考虑读写分离的设计,一般常用的方式是一写两读。这样就可以减轻一台数据库的读写压力。

我们可以通过上述数据库主从分离的方式来做,这时候要注意数据库查询和更新的改造,可以通过Service层注解拦截的方式减少代码改造量。红色箭头部分是写入主库并进行从库复制,灰色箭头部分是一个WEB容器对应一个从库的方式分解查询压力。
但是读的方面依然遇到很大的并发压力时,可以进一步纳入Redis形成查询缓存,进一步提升读的性能。

对于MySQL的写入优化其实比读取优化要难得多,往往涉及到对数据的改造,例如常做的分库分表,就是典型的动数据,需要将数据表按照数据增长的一个范围形成一个表,存放在分布式中的一个MySQL数据库中,集中式的路由表协助分布式库表的注册和发现,这样写入过程就必须先从路由表中判断数据库路由地址。其实如果不到万不得已的情况,尽量不要用这种模式,因为这个过程把问题大复杂化了!至少一开始读写分离就要重新规划,跨表聚合都耦合在了上层应用程序实现。
那么写入优化步对MySQL进行分区是必要的,例如:RANGE分区、LIST分区、HASH分区、复合分区,需要注意的是根据业务需要来规划分区,例如文章写入具有明显的日期性,那么基于日期的Range分区就挺不错,但是,往往有热度的文章,互动就很频繁,那么对于文章和互动就应该打上热度标签,将热度分类标签作为LIST分区的切分项,通过复合分区的方式,将有热度的互动数据迁移在热度分区上。
混合架构的优化方案
好了,做了上面这些,要是单库压力还是巨大,那么就不能再单纯考虑关系型RDBMS的存储形式了,需要考虑引入支持K-V的NoSQL支撑写入。
先给一个黑科技吧,就将MySQL master主库引擎InnoDB做替换,尝试使用MyRocks引擎,但是这个需要进行严格的业务兼容性测试。
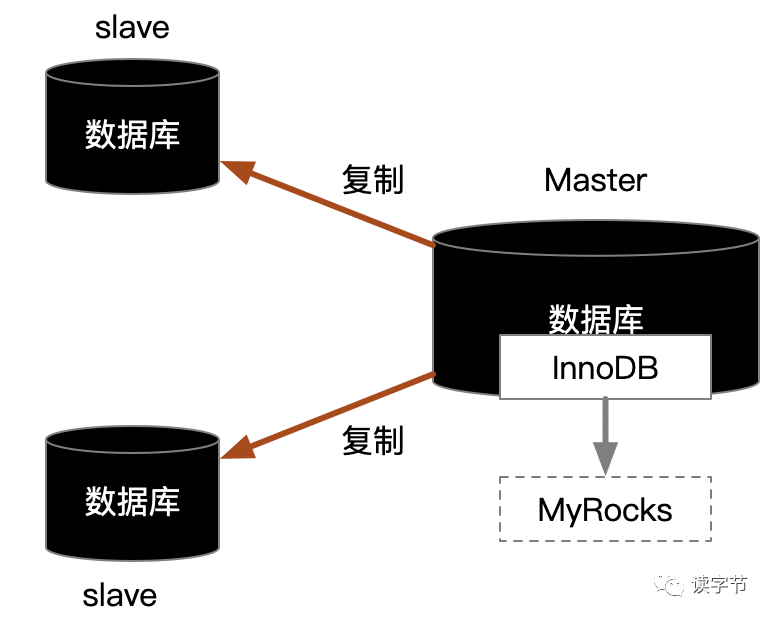
MyRocks实际上就是RocksDB,RocksDB在对写入性能上有着甩传统数据库几十条街的性能提升(前提是好上SSD固态存储),可以看看我的另一篇文章创作:为什么分布式数据库这么喜欢用kv store?,从底层数据结构的逻辑上分析,就能理解为什么K-V存储强悍的写入能力。虽然在范围查找上不如传统的RDBMS,但是读写分离机制恰恰弥补了这一点,但是这个黑科技,为不确定的就是读写复制的稳定性,这个需要——测试!测试!测试!
好,我们再去推测一下百度、知乎这些大厂在面对每天亿级甚至是几十亿级的数据记录写入怎么办?
这个时候MySQL数据库单库写基本没戏,单机I/O都撑不住,那一定会采取分布式NoSQL+关系型数据库集群的混合方案,也就是K-V存储模型的分布式数据库应对频繁地插入更新操作,但业务的完整性关系,终落地在关系型数据库集群,复杂密集的业务关系,还是需要关系表来维护比较合适。
百度、知乎这些大户,我推理猜测,他们对于实时性操作较高的业务,例如文章不断地编辑,应该是在分布式的大数据平台上进行KV存储和访问,完成临时性处理,而不着急更新密集的业务关系表,等正式提交后,一定有一个延时的排队过程才会进行rdbms数据库维护关系表的事务完整性。
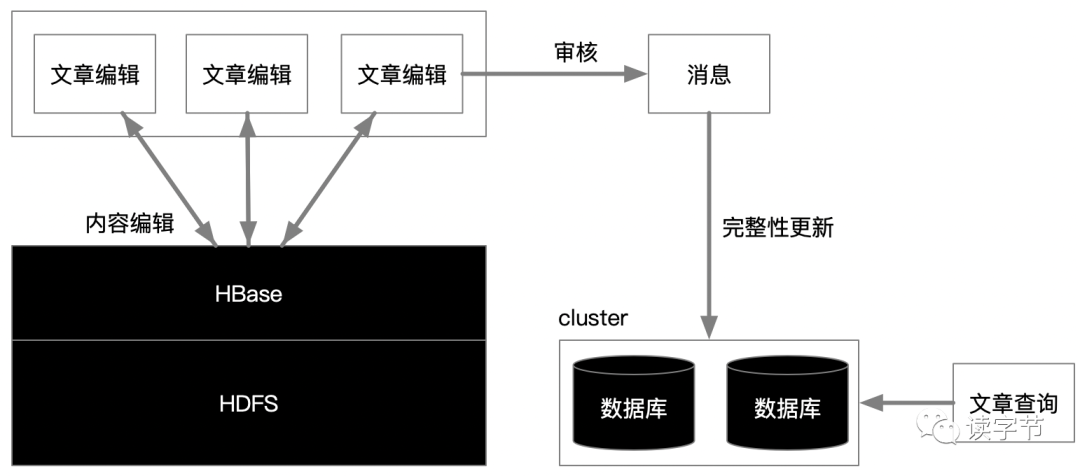
上述只是一个推理猜测图,并不一定是无误的,仅供参考。
如图我们可以看到引入了大数据平台Hadoop,主要是想利用HBase极高性能的K-V读写,尤其是对文章内容的草稿编辑,基本上属于准实时的操作,如果万人在线在MySQL数据库上这么干,数据库的写入就得崩溃了!那么对于文章可以形成一个文档的K-V关系在HBase的稀疏表上尽情写入,实际上更新也只是内容版本的一次迭代。HBase不用考虑复杂的关系问题,只关注文章内容的编辑问题。
当作者认为完成了写入,就提交文章,进入审核状态,审核过程可以充分利用消息系统,形成文字审核的事件化,对过滤敏感词、涉黄等等都问题进行实时流式处理,由订阅的管道推动给关系型数据库集群,形成完整的数据事务关系,那么就把解决高并发的写入问题转变成了队列推送的大吞吐数据计算问题。之后文章查询就针对关系型数据库集群,形成一套缓存机制、分布式查询体系,就容易得多了!
后
就说这么多吧,实际上大厂的分布式数据计算比我推理的肯定是要复杂许多许多,我只是站在技术合理性的角度,给大家一个方向性的思考,建立高并发、海量数据的网站,我们应该遵循的一个过程,说到底就是用小的成本,逐步深化,防止一开始的过渡技术。总之关系型数据库分库分表的模式除非万不得已,一定要慎用!因为一旦用开了,就很难掉头了,系统运维会淹没在数据维护的复杂性问题上。
