主从集群
1. 主从简介
LSQL在主从集群上需要启动两个LSQL,两个LSQL是在进程上的资源隔离。
在主上面可以进行数据的导入、删除以及查询。从只能负责数据的查询。
启动多个lsql集群,一主多从。
在主上面做数据写入。从做查询。
与mysql不同的是,主从共享同一份数据。
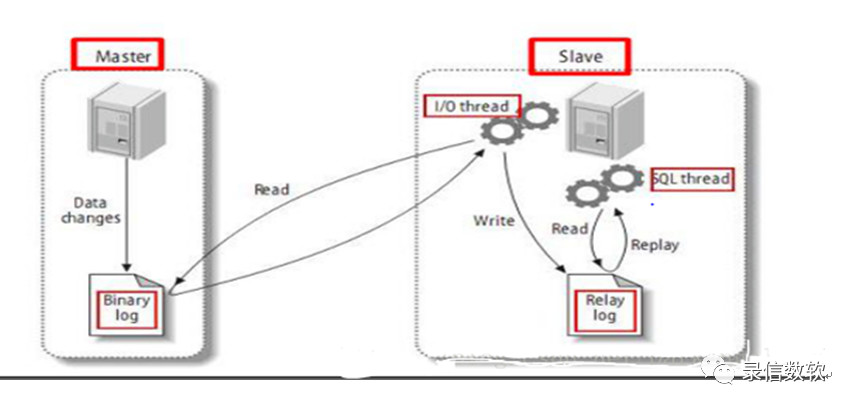
2. 配置方法
主从集群,需要在两个不同的机器上配置。
在lsql_env.sh里配置:
export CL_SERVER_ROLE=primary #为主集群,切记,主集群只能有一个,不能有多个,否则会相互冲突,有可能引起数据丢失export CL_SERVER_ROLE=standby #为只读集群--如果在从集群里,为了节省资源,有些表不希望加载,可以通过在lsql_site文件中,配置cl.partxxxxx.skip.tablelist来跳过cl.partxxxxx.skip.tablelist=.*olap.*;.*lsql.*
配置完毕后,在1210页面上可以看到集群角色为primary 或 standby。
1. 过载保护
对查询资源进行限制,如果超过设定的资源,则主动停止该SQL的运行。
2. 解决问题
*查询导致系统崩溃退出
shuffle 达到过载保护的阈值,则中断此SQL,保证系统服务正常
文件读写量的过载控制
SQL任务执行时间的控制-超时则kill
3. 开启shuffle数据倾斜自动识别
(1) 在config/spark/spark-defaults.conf里添加如下配置项(单位为byte):
spark.shuffle.io.limitSize=true #是否启用过载保护spark.shuffle.io.maxrwSize=5120000000 #原先默认过载保护的阈值spark.shuffle.io.agg.records=10240000 #新发现的聚集部分的过载保护,限制条数,此处shuffle的io 并不大,故只能采用条数进行判断。spark.shuffle.io.sort.maxrwSize=5120000000 #sort部分的过载保护的阈值spark.shuffle.io.collection.maxrwSize=5120000000 #collection部分的过载保护的阈值
(2) 在config/spark/spark-defaults.conf里修改如下配置项:
spark.sql.shuffle.partitions=256 #该参数代表了shuffle read task的并行度,该值默认是32,当机器数量增加至100台时需将该值调整为256。增加shuffle read task的数量,可以让原本分配给一个task的多个key分配给多个task,从而让每个task处理比原来更少的数据,通过提高shuffle操作的并行度来有效缓解和减轻数据倾斜的影响。4. 关闭过载保护
在config/spark/spark-defaults.conf里修改为如下配置项:
spark.shuffle.io.limitSize=false #不启用过载保护5. 过载保护其他配置项
(1) 过载保护1
配置项 | 运行时动态设置 | 默认值 | 说明 |
cl.query.multi.termquery.throw.error | 不可以 | true | 超过term允许你遍历的个数,是抛错还是直接返回数据,当用户进行*或者范围检索时,如果扫描的范围太大,影响了性能,有系统查挂的风险时,系统会进行过载保护,进行过载保护的方式false:直接返回数据而不抛错,true则中断当前查询抛错给用户 |
cl.query.multi.termquery.size | 可以 | 10240 | 当用户进行*或者范围检索时,扫描的term数量超过多少会触发系统过载保护行为,默认term允许你遍历的个数 |
cl.search.max.collect.return.break.size | 可以 | 无限制 | where检索的时候,检索命中多少条数后直接 break返回 |
cl.sql.execute.timeout.secs | 可以 | 600 | 运行时,一条SQL期望在多少秒内执行完毕,如果没有执行完毕,则会自动kill这条SQL的执行 |
cl.sql.execute.max.mb | 可以 | 102400 | 运行时,一条SQL期望的IO读取限制,默认限制每个进程1024mb |
(2) 过载保护2
配置项 | 运行时动态设置 | 默认值 | 说明 |
cl.sql.parser.auto.add.limit | 不可以 | true | 如果SQL没写limit自动是否自动补limit |
cl.sql.parser.auto.add.limit.default.rows | 不可以 | 1024 | 自动补的limit的大小,用户SQL不写limit,默认限制的返回条数 |
syskv='sys.forbid.sql.auto.limit:true' | 可以 | 在sql中动态添加该参数,可以显示禁用自动添加limit,注意这里设置false | |
cl.mdrill.max.forbid.limit.rows | 不可以 | 10000000 | 在sql中能够使用的大limit的大小,超过改值会被禁用,并报错 |
cl.mdrill.max.allow.limit.rows | 不可以 | 30000 | mdrill模式多允许的limit大小,offset+rows的和,超过了,就不能翻页,只能走spark了 |
cl.groupby.combine.max.hashmap.size | 可以 | 5000 | mdrill方式能够进行的大分组数,如果超过此值,则会通过spark进行分组 |
cl.highpriority.partition | 可以 | null | 在mdrill模式的检索里 ,按照日期分区分批次返回配置 如何分区返回 ,以及配置 cl.highpriority.facet.count 控制 数量达到多少即可停止不在继续请求 在facet逻辑里也可以 通常与cl.facet.group.max.count 组合使用,来每个分组统计值 达到多少后就不在继续统计,从而节省计算资源select s1 from common_example001 where partition like '%' and s1 like '3*'and syskv='cl.facet.fl:s1' and syskv='cl.highpriority.partition:day_1@day_4@day_16@day_64'and syskv='cl.highpriority.facet.count:30000'and syskv='cl.facet.group.max.count:5000'limit 5 |
LSQL独有的过载保护功能,使集群更稳:
支持自动释放资源:可以对集群设置一个SQL的执行时间,如果预计执行10分钟,超过10分钟,自动释放资源。且可以添加对超时SQL的处理,一个SQL可以添加超时时间,如果超过超时时间可以cancel掉。
支持过载保护功能:对耗费IO的SQL进行诊断,如果做类似1*,2*等会引起系统稳定性的查询,会自动诊断,默认每个进程超过10W个term或者IO超过10GB会自动KILL。
支持数据倾斜自动保护功能:数据倾斜一般是大数据系统稳定性的杀手,进行多表关联时,如果关联的key发生数据倾斜,很多时候会造成集群非常缓慢,甚至挂掉,而LSQL会对这种情况进行自动识别,并处理,拒绝这种SQL语句的执行。
原文链接:https://mp.weixin.qq.com/s/Q6AmJ9s4KNBjmI3dbE2Ycg
