Facet在标签分析与画像分析中是必备的功能。facet用于反映一个搜索词的小平面(或者说某一个分组),即起到标签聚合统计的功能,可以像电商类网站那样的对搜索结果聚合分类,品牌等属性。简言之,facet就是某一类型的标签统计,比如xxx年热词等等,只要有记录,都能统计出来。
这类数据一般具有这样的数据特点:
单列统计而不会交叉
标签数据重复值很高,如男与女
有很多null值。
上述场景若处于公安,交通交警与军队等行业,则面临巨大的挑战,这类行业的数据规模更大,小则几十亿,大则几万亿,常规的商业数据库以及搜索引擎满足不了这类需求,而这正是LSQL 的长处。
Facet技术优势
相对于业内常规方案,LSQL在facet上具有如下技术优势,也是实现在万亿级别能够进行秒级统计的技术基础。
(1) 在读取数据上,常规方案需要一条一条的从磁盘随机读取,而LSQL是一批一批的顺序读取,而磁盘的顺序读写的性能要远远高于随机读取。
(2) 在null值的处理上,如果null值占比很高,常规方案针对null值也要进行一次判断,如果null值可以直接跳过的话会大幅度提升计算速度。而LSQL则不需要对null值进行计算。
(3) 在异构策略上,因实际项目中考虑项目的经济性,往往将ssd硬盘、sata硬盘等多重硬盘混合在一起使用。这种策略下,通常将随机读写较多的索引部分存储在固态硬盘上,而将数据和备份存储在相对比较廉价的sata盘上。因存储机制的不同常规方案的统计实现是从sata盘上获取数据而再进行统计的,LSQL是从固态硬盘上读取,两种盘的性能截然不同。
(4) 在内存上,常规方案是将一个列的值或者ord全部构建在内存里,内存消耗大,因现实项目预算不可能提供几百tb规模的内存,故百亿以上根本不可能。而LSQL则没有这种问题,LSQL仅消耗少量内存来计算,不像常规方案那样过分依赖内存。
(5) 在实时数据导入上,常规方案会因数据的实时变动而不断的对内存映射进行重建,重建开销太大了,所以通常来说常规方案在统计模式下只能处理静态索引。而LSQL这种方法,数据可以实时导入,而且还能同时进行facet统计。
(6) 在存储上,常规方案需要同时创建索引和存储部分才能进行统计,null值也必须占用空间,而新技术仅使用索引部分,存储体积比原先能减少至少三分之二,且null不占存储。
(7) 在计算上,万亿场景针对每个分组,用户可以接受只要告诉用户这个分组的数据条数超过xxx(如5000条)即可,不必全部计算。常规方案必须要将每个分组的数据全部计算完毕才能返回,很多计算是浪费掉的,而LSQL则支持这样的操作,不用将每个组全部条数据都计算出来,达到设定的条数后,就可以直接开始计算下一组的数据。
(8) 在检索上,万亿场景没必要将匹配到的数据全部返回,用户大部分情况下看不了那么多,往往用户会设定一个阈值,系统只需要返回匹配到的前一万条即可。常规方案的检索必须要检索到全部的记录才行,即使匹配了上万亿,也要全部检索出来,常规方案不会对是否已经达到了匹配条数而进行判断,而LSQL可以通过设定一个期望返回的数据条数,如10000。在检索过程中达到期望值后直接中断返回。除此之外,LSQL是先查近几天的,如果近几天的数据能满足达到10000条的要求,则后续几天的数据就可以不必进行检索,而直接返回了。而往往近几天的数据是存储在固态上的,返回很快,通过这种方式减少计算量,从而提升整体响应时间。
(9) 在大范围扫描上,常规方案对像1* ,2*,以及大范围的range扫描这样的查询会直接查挂,系统会直接崩掉。而LSQL技术则不会,对此有较好的处理,不会查挂。
(10) 在任务管控上,常规方案针对一个已经发出去的请求无法撤销,即使SQL写错了也不行,必须执行完毕。而LSQL每个查询都有超时时间的限制,如果超过配置时间没有执行完成,会自动杀掉。可以看每个查询的执行进度,也可以直接kill掉。
Facet使用
1. cl.facet.fl的使用
--按照性别、学历进行分类统计select sex,education from facet wheresyskv='cl.facet.fl:sex,education'limit 4;
--按照性别、学历进行分类统计--cl.facet.group.max.count用来决定每个分组统计值达到200后就不在继续统计,从而节省计算资源select sex,education from facet wheresyskv='cl.facet.fl:sex,education'and syskv='cl.facet.group.max.count:200'limit 4;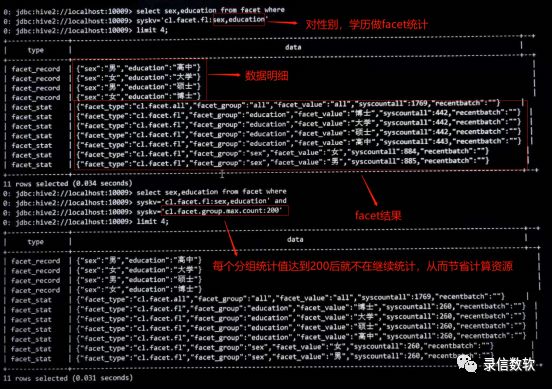
注意:
(1) 该处cl.facet.group.max.count设置为200,但在实际统计过程中为了考虑到每个executor读取的数量差异,故单 个executor的实际统计结果为设置值的1.3倍,即总的统计结果为200*1.3*1=260(本次测试软件executor数为1)。
(2) 该处cl.facet.group.max.count参数仅适用于每个executor中数据量均匀的情况。若每个executor中数据分布不均,则会导致统计结果出现错误。
--按照性别、学历进行分类统计--如果设置limit 0 则只返回facet结果,不会返回数据明细select sex,education from facet wheresyskv='cl.facet.fl:sex,education'limit ;
--按照性别、学历、去过的城市进行分类统计--多值列也可以使用facet--如果设置limit 0 则只返回facet结果,不会返回数据明细select sex,education,city from facet wheresyskv='cl.facet.fl:city'limit 4;
--按照性别、学历、去过的城市进行分类统计--多值列也可以使用facet--如果设置limit 0 则只返回facet结果,不会返回数据明细select sex,education,city from facet wheresyskv='cl.facet.fl:city'limit ;

2. cl.facet.fq的使用
--对年龄在0-18以及22-60周岁的人群进行统计-- cl.facet.group.max.count用来决定每个分组统计值达到1000后就不在继续统计,从而节省计算资源。select * from facet where syskv='cl.facet.fq:q1:age>=0 and age<18' and syskv='cl.facet.fq:q2:age>22 and age<60'and syskv='cl.facet.group.max.count:1000'limit 4;
--对年龄在0-18以及22-60周岁的人群进行统计-- cl.facet.group.max.count用来决定每个分组统计值达到1000后就不在继续统计,从而节省计算资源----如果设置limit 0 则只返回facet结果,不会返回数据明细select * from facet where syskv='cl.facet.fq:q1:age>=0 and age<18' and syskv='cl.facet.fq:q2:age>22 and age<60'and syskv='cl.facet.group.max.count:1000'limit ;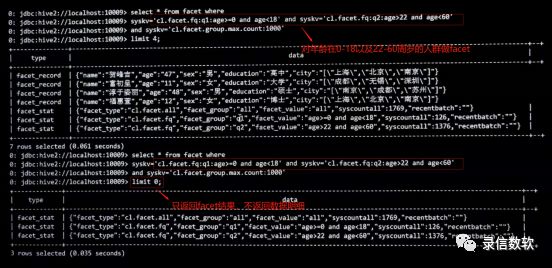
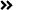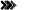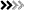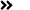
3. 组合使
--按照性别、学历进行分类统计--对年龄在0-18以及22-60周岁的人群进行统计-- cl.facet.group.max.count用来决定每个分组统计值达到1000后就不在继续统计,从而节省计算资源select sex,education,city from facet where syskv='cl.facet.fl:sex,education' andsyskv='cl.facet.fq:q1:age>=0 and age<18' and syskv='cl.facet.fq:q2:age>22 and age<60'and syskv='cl.facet.group.max.count:1000'limit 4;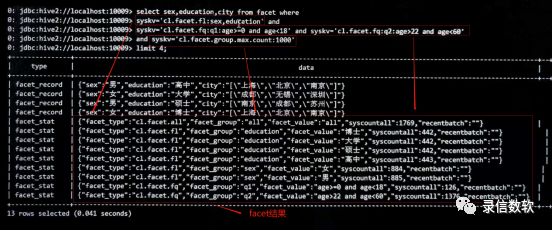
4. 按照日期分区分批次返回
配置 cl.highpriority.partition 如何分区返回 ,以及配置 cl.highpriority.facet.count 控制数量达到多少即可停止不在继续请求。
也通常与cl.facet.group.max.count 组合使用,来决定每个分组统计值达到多少后就不在继续统计,从而节省计算资源。
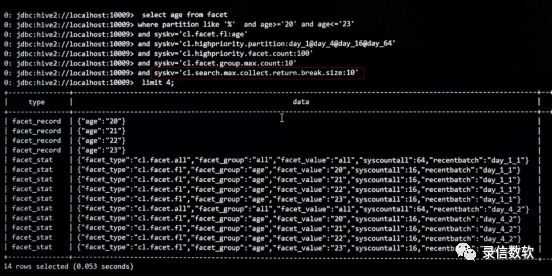
select age from facet where partition like '%' and age like '1*'and syskv='cl.facet.fl:age' and syskv='cl.highpriority.partition:day_1@day_4@day_16@day_64'and syskv='cl.highpriority.facet.count:1000'and syskv='cl.facet.group.max.count:1000' limit 5;

改小参数:


5. 限制搜索,只搜索到TOPN个结果即可

再缩小范围:
6. 限制超时时间搜索,只搜索到TOPN个结果即可
可以通过cl.search.max.collect.return.break.size、cl.sql.execute.timeout.secs来控制搜索,控制匹配到的结果数。
select count(*) from facet where partition = '20191202' and syskv='cl.search.max.collect.return.break.size:30000'; select count(*) from facet where partition = '20191202' and syskv='cl.sql.execute.timeout.secs:120'; select count(*) from facet where partition = '20191202' and syskv='cl.search.max.collect.return.break.size:30000' and syskv='cl.sql.execute.timeout.secs:120';

原文链接:https://mp.weixin.qq.com/s/PcEJxrXSSYcPTA1FIgt4BQ
