在看一个算法是否时,我们一般都要考虑一个算法的时间复杂度和空间复杂度。现在随着空间越来越大,时间复杂度成了一个算法的重要指标,那么如何估计一个算法的时间复杂度呢?
时间复杂度直观体现
首先看一个时间复杂度不同的两个算法,解决同一个问题,会有多大的区别。 下面两个算法都是用来计算斐波那契数列的,两个算法会有多大的差异。
斐波那契数列(Fibonacci sequence),又称黄金分割数列、因数学家列昂纳多·斐波那契(Leonardoda Fibonacci)以兔子繁殖为例子而引入,故又称为“兔子数列”,指的是这样一个数列:1、1、2、3、5、8、13、21、34、……在数学上,斐波那契数列以如下被以递推的方法定义:F(1)=1,F(2)=1, F(n)=F(n-1)+F(n-2)(n>=3,n∈N*)
- 种:使用递归方式
/**
* 使用递归方式计算斐波拉契数列
* @param index 计算的项数
*/
public static long fibonacciUseRecursion(int index){
if(index <= 1){
return index;
}
return fibonacciUseRecursion(index-1) + fibonacciUseRecursion(index-2);
}
- 第二种:使用非递归方式
/**
* 不使用递归方式计算斐波拉契数列
* @param index 计算的项数
*/
public static long fibonacciNoUseRecursion(int index){
if (index <= 1){
return index;
}
long first = ;
long second = 1;
for (int i = ; i < index - 1;i++){
second = first + second;
first = second - first;
}
return second;
}
对上面两种算法进行简单的运行时间统计,我们使用下面的代码进行简单的测试
public static void main(String[] args) {
// 获取当前时间
long begin = System.currentTimeMillis();
// 计算第50项斐波拉契数列的值
System.out.println(fibonacciUseRecursion(50));
// 计算时间差,算法执行所花的时间
System.out.println("time:" + (System.currentTimeMillis() - begin) / 1000 +"s");
begin = System.currentTimeMillis();
System.out.println(fibonacciNoUseRecursion(50));
System.out.println("time:" + (System.currentTimeMillis() - begin) / 1000 + "s");
}
测试结果如下:

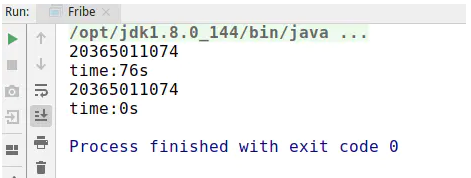
可以看到,在计算第50项的时候,种递归方式花费了48秒的时间,而第二种不到一秒,虽然这种方式不太科学,但也看出来了两者巨大的差距,并且随着计算的值越大,时间的差异越明显。由此可见,时间复杂度是决定一个算法好坏的重要指标。
如何衡量一个算法的好坏
- 正确性、可读性、健壮性。 算法必须要保证正确,不正确的算法是没有必要衡量其好坏的;算法也要保证良好的可读性,能够让阅读者明白内在实现与逻辑;健壮性为对不合理输入的反应能力和处理能力,比如非法输入,要有相应的处理,而不应该程序奔溃等。这些都是一个良好的算法必备的条件。
- 时间复杂度 时间复杂度也是一个衡量算法优劣的重要条件,不同的算法的执行时间可能会存在很大的差别。
- 空间复杂度 空间复杂度表示一个算法执行过程中,需要的空间(内存)数量,也是衡量一个算法的重要指标,尤其是在嵌入式等程序中的算法,内存是非常宝贵的,有时候宁愿提高时间复杂度,也要保证不占用太多的空间。
如何计算时间复杂度
种:事后统计法
上面我们使用了一种计算执行前后时间差的方式,直观的来看一个算法的复杂度,比较不同算法对同一组输入的执行时间,这种方法也叫作"事后统计法",但是这种方法也存在一些问题,主要问题有:
- 执行时间严重依赖于硬件已经运行时各种不确定的环境因素。 比如两个算法在不同的硬件机器上进行测试,硬件不同,运行时间也会存在差异,即使就在一台机器上执行,也会存在运行时机器的CPU、内存使用情况不同等因素。
- 必须要编写相应的测试代码。
- 测试数据的选择难以保证公正性。 比如有两个算法,一个在数据量小的时候占优,一个在大数据量的时候运行较快,这样便难以选择一个公正的测试数据。
第二种:估算代码指令执行次数
那么我们可以使用代码的每个指令的执行次数,可以简单估算代码的执行次数,一般情况下,执行次数少的肯定要比执行次数多的花的时间更少。看如下的示例:
public static void test1(int n) {
if (n > 10) {
System.out.println("n > 10");
} else if (n > 5) {
System.out.println("n > 5");
} else {
System.out.println("n <= 5");
}
for (int i = ; i < 4; i++) {
System.out.println("test");
}
}
上面这个方法,我们计算它的执行次数。
- 上面的if...else if...else这个判断,判断会执行一次、判断成立的代码会执行一次。
- 下面的for循环,i=0这句赋值会执行一次,i<4这个判断条件会执行4次,i++也会执行4次,循环体(输出语句)也会执行4次。
- 因此,整个方法的执行次数为:1+1+1+4+4+4 = 15次。
public static void test2(int n) {
for (int i = ; i < n; i++) {
System.out.println("test");
}
}
上面这个方法,我们计算它的执行次数。
- 在for循环中,i=0这句赋值会执行一次,i < n执行n次,i++执行n次,循环体执行n次。
- 因此,整个方法的执行次数为:1+n+n+n = 3n+1 次
public static void test3(int n) {
for (int i = ; i < n; i++) {
for (int j = ; j < n; j++) {
System.out.println("test");
}
}
}
上面这个方法,我们计算它的执行次数。
- 在外层for循环中,i=0这句赋值会执行一次,i < n执行n次,i++执行n次,循环体执行n次。
- 在内层循环中,j=0这句赋值会执行一次,j < n执行n次,j++执行n次,循环体执行n次。
- 因此,整个方法的执行次数为 1+n+n+n*(1+n+n+n)=3n2+3n+1 次
public static void test4(int n) {
for (int i = ; i < n; i++) {
for (int j = ; j < 15; j++) {
System.out.println("test");
}
}
}
上面这个方法,我们计算它的执行次数。
- 在外层for循环中,i=0这句赋值会执行一次,i < n执行n次,i++执行n次,循环体执行n次。
- 在内层循环中,j=0这句赋值会执行一次,j < 15执行15次,j++执行15次,循环体执行15次。
- 因此,整个方法的执行次数为 1+n+n+n*(1+15+15+15)=48n+1 次
public static void test5(int n) {
while ((n = n / 2) > ) {
System.out.println("test");
}
}
上面这个方法,我们计算它的执行次数。
- 在while循环中,每次对n取一半,相当于对n取以二为底的对数,因此n = n / 2 会执行log2(n)次,判断条件也会执行log2(n)次。
- 在循环体中,这个输出语句也会执行log2(n)次。
- 因此,整个方法的执行次数为 log2(n) + log2(n) + log2(n) = 3log2(n)次
public static void test6(int n) {
while ((n = n / 5) > ) {
System.out.println("test");
}
}
上面这个方法,我们计算它的执行次数。
- 在while循环中,每次对n取五分之一,相当于对n取以五为底的对数,因此n = n / 5 会执行log5(n)次,判断条件也会执行log5(n)次。
- 在循环体中,这个输出语句也会执行log5(n)次。
- 因此,整个方法的执行次数为 log5(n) + log5(n) + log5(n) = 3log5(n)次
public static void test7(int n) {
for (int i = 1; i < n; i = i * 2) {
for (int j = ; j < n; j++) {
System.out.println("test");
}
}
}
上面这个方法,我们计算它的执行次数。
- 在外层for循环中,i= 1执行一遍,每次i翻倍,执行次数为log2(n),因此i < n会执行log2(n)次,i=i*2会执行log2(n)次,循环体执行log2(n)。
- 在内层for循环中,j=0执行一次,j < n执行n次,j++执行n次,内层循环条件执行n次。
- 因此,整个方法的执行次数为 1+ log2(n) + log2(n) + log2(n)*(1+n+n+n) = 3nlog2(n) + 3log2(n)+1次
public static void test8(int n) {
int a = 10;
int b = 20;
int c = a + b;
int[] array = new int[n];
for (int i = ; i < array.length; i++) {
System.out.println(array[i] + c);
}
}
上面这个方法,我们计算它的执行次数。
- a=10执行一次,b=20执行一次,c=a+b执行一次,初始化数组执行一次。
- 在for循环中,i=0执行一次,i < 数组长度执行n次,i++执行n次,内层循环条件执行n次。
- 因此,整个方法的执行次数为 1+1+1+1+1+n+n+n =3n +5次。
使用这种方法我们发现计算会特别麻烦,而且不同的时间复杂度表达书也比较复杂,我们也不好比较两个时间复杂度的具体优劣,因此为了更简单、更好的比较不同算法的时间复杂度优劣,提出了一种新的时间 复杂度表示法---大O表示法。
大O表示法
大O表示法:算法的时间复杂度通常用大O符号表述,定义为T[n] = O(f(n))。称函数T(n)以f(n)为界或者称T(n)受限于f(n)。 如果一个问题的规模是n,解这一问题的某一算法所需要的时间为T(n)。T(n)称为这一算法的“时间复杂度”。当输入量n逐渐加大时,时间复杂度的极限情形称为算法的“渐近时间复杂度”。
大O表示法,用来描述复杂度,它表示的是数据规模n对应的复杂度,大O表示法有以下的一些特性:
- 忽略表达式常数、系数、低阶项。 忽略常数,常数直接为1,比如上面个方法的复杂度为15,因此直接取1,其时间复杂度使用大O表示为O(1)。 忽略系数,忽略表达式的系数,比如第二个方法的时间复杂度为3n+1,忽略系数和常数,其时间复杂度为O(n)。 忽略低阶项,比如第三个方法的时间复杂度为3n2+3n+1,忽略低阶项3n,忽略常数1,忽略系数3,则其时间复杂度为O(n2)。
- 对数阶一般忽略底数 对于对数直接的转换,一个对数都可以乘以一个常数项成为一个没有底数的对数,比如 log2n = log29 * log9n,因此可以省略底数,比如上面第五个方法的时间复杂度为log2(n),可以忽略底数2,则其时间负责度为logn。
- 大O表示法仅仅是一种粗略的分析模型,是一种估算,能帮助我们短时间内估算一个算法的时间复杂度。
常见的复杂度
| 执行次数 | 复杂度 | 非正式术语 |
|---|---|---|
| 12 | O(1) | 常数阶 |
| 2n+3 | O(n) | 线性阶 |
| 4n2+zn+2 | O(n2) | 平方阶 |
| 4log2n+21 | O(logn) | 对数阶 |
| 3n+2log3n+15 | O(nlogn) | nlogn阶 |
| 4n3+3n2+22n+11 | O(n3) | 立方阶 |
| 2n | O(2n) | 指数阶 |
复杂度的大小关系 O(1) < O(logn) < O(n) < O(nlogn) < O(n2) < O(n3) < O(2n) < O(n!) < O(nn)。
因此上面的十个方法的复杂度如下:
| 方法名称 | 复杂度 | 大O表式 |
|---|---|---|
| test1 | 15 | O(1) |
| test2 | 3n+1 | O(n) |
| test3 | 3n2+3n+1 | O(n2) |
| test4 | 48n+1 | O(n) |
| test5 | 3log2(n) | O(logn) |
| test6 | 3log5(n) | O(logn) |
| test7 | 3nlog2(n) + 3log2(n) + 1 | O(nlogn) |
| test8 | 3n+5 | O(n) |
直观对比复杂的的大小
直接看表达式,还是很难判断一些复杂度的大小关系,我们可以借助可视化的一些工具来查看比如https://zh.numberempire.com/graphingcalculator.php,通过该网站我们看到在n变化的情况下,不同表达式的变换情况。
递归斐波拉契数列计算方法的时间复杂度分析
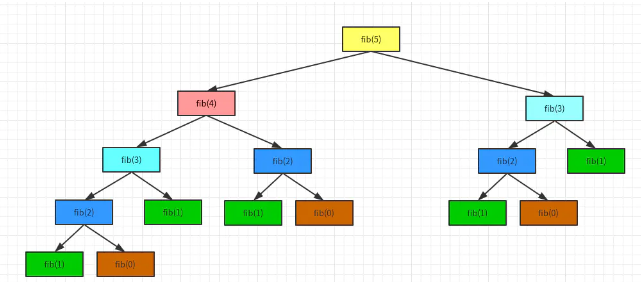
层计算5,只需要计算1次;第二层计算3和4,2次;计算第3层,4次;计算第4层,8次。所以总共计算1+2+4+8 =15= 25-1 = 1/2 * 22 -1

层计算6,只需要计算1次;第二层计算5和4,2次;计算第3层,4次;计算第4层,8次;第5层,计算10次。所以总共计算1+2+4+8+10 =25 = 25 - 7 = 1/2 * 26 - 7。 所以计算第n项,它的时间复杂度为O(2^n)。 所以开始的两个算法,个的算法复杂度为O(2n),一个为O(n)。 他们的差别有多大?
- 如果有一台1GHz的普通计算机,运算速度109次每秒(n为64)
- O(n)大约耗时6.4 ∗ 10-8秒
- O(2n)大约耗时584.94年
- 有时候算法之间的差距,往往比硬件方面的差距还要大
算法的优化方向
- 用尽量少的存储空间,即空间复杂度低。
- 用尽量少的执行步骤,即时间复杂度低。
- 一定情况下,时间复杂度和空间复杂度可以互换。
关于复杂度的更多概念
- 好、坏复杂度
- 均摊复杂度
- 复杂度震荡
- 平均复杂度
- ......
总结

链接:https://juejin.im/post/5e11a282f265da5d332ce247
来源:掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
