要讲清楚Java内存管理的林林总总,先需要搞清楚的是JVM内存的组成模块以及每个模块的运作机制。
这篇文章基于此重点介绍三个方面的内容:
1. JVM内存由哪些模块构成?
2. 这些内存模块内部分别存储的核心的数据结构是什么?
3. 这些内存模块是如何相互协作来完成一个简单的Java程序的运行的?

JVM内存由哪些模块构成?
对于Java程序员来说,这是一个入门级的问题,但是也并非每个人都能完整地说清楚。下面这张图参考周志明老师《深入理解Java虚拟机第二版》中一张图重新画了一下:
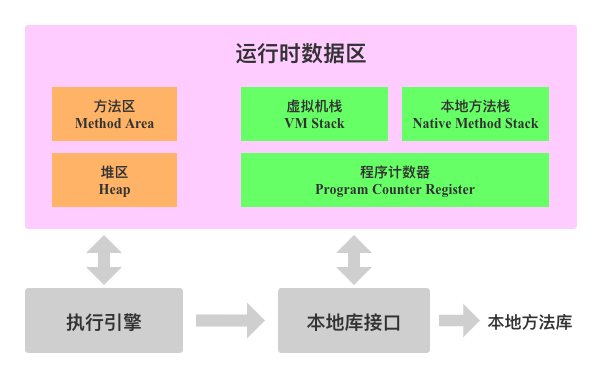
上图中运行时数据区是我们关注的重点。运行时数据区主要由虚拟机栈、本地方法栈、程序计数器、方法区以及堆等内存模块构成。其中前三个绿色模块是线程私有的,表示每个运行线程都会有自己独立的虚拟机栈、本地方法栈和程序计数器。而后两个橙色模块表示的方法区和堆区则是所有线程共享的。接下来分别简单扼要地介绍一下每个模块的核心作用:
● 虚拟机栈(VM Stack):每个运行线程都会有一个虚拟机栈,两者生命周期相同。我们知道,线程运行的本质是方法的不断调用与执行,即A方法调用并执行B方法,B方法调用并执行C方法,...。为了记录线程运行过程中所有这些方法的相关信息,JVM就使用虚拟机栈来完成这项工作。简单来说,当A方法要调用B方法,就把B方法的相关信息压入虚拟机栈,B方法一旦执行完,就将其从虚拟机栈中出栈。线程运行看起来就是方法的不断入栈和出栈。
● 本地方法栈(Native Method Stack):与虚拟机栈基本相似,区别是虚拟机栈执行的是Java方法,而本地方法栈执行的是Native方法。
● 程序计数器(Program Counter Register):和虚拟机栈一样是线程私有的一个内存区域,每个运行线程都有一个独立的程序计数器。上文中提到线程运行的本质是方法的不断调用与执行,而在Java这种多线程的运行环境中,一个线程执行一个方法的时候执行到了一半,CPU时间片就被分配给了另一个线程执行它自己的方法,等过一段时间,CPU时间片又切回来的时候,我们就需要知道上次执行到了哪里,以便接着往下执行。程序计数器就是用来记录下一个需要执行的指令的行号。
● 方法区(Method Area):和上述三个模块不同,方法区是所有线程共享的一块内存区域。这块区域主要用来存储被JVM加载进来的类信息、运行时常量池、方法、代码等信息。对于程序员来说,经常会写类文件,这些类文件会被编译为.class文件,并在用到的时候被JVM加载到内存,放到的区域就是方法区。可能有的童鞋会好奇,为什么这个区域光明正大的叫方法区?我说说我的理解,Java是一门面向对象的语言,我们在程序中不断创建并使用对象,这些对象怎么来的,是按照某个类刻画出来的,一般一个类中通常由普通字段、静态字段以及方法构成,一个类可以对应很多对象,这些对象都有各自的普通字段,并且公用静态字段和方法,而方法显然比静态字段占用内存大的多,所以这个区域主要还是存放的方法的指令信息,所以称为方法区。
● 堆区(Heap):和方法区一样,堆区也是所有线程共享的。这个区域主要存放对象实例以及数组实例。相信这个区域应该是大家熟悉的区域,在此不再赘述。

这些内存模块内部分别存储的核心的数据结构是什么?
上文从全局的视角简单介绍了构成Java运行时数据区的几个重要的内存区域以及其核心作用,接下来本小节将从细节入手重点介绍其中的方法区、堆区以及虚拟机栈区这三个内存区域内部存储的主要数据分别是什么。

方法区核心数据结构
上文提到方法区主要存放类信息,包括Java类的字段信息以及方法字节码。对于给定的类,在方法区中需要存储的信息至少包含两大类数据:类型基本描述信息和域信息。
● 类型基本描述信息主要包括:类的全限定名,类的直接超类的全限定名,类型修饰(如public、abstract、final等Java关键字)以及类实现的接口列表。
● 域信息主要包括字段域和方法域。其中字段域主要存储的信息主要有字段名、字段类型、字段描述(如public、static、final、volatile以及transient等Java关键字)。方法域主要存储的信息包括方法名、返回类型、方法参数的个数以及类型、方法描述、方法的字节码、操作数栈的大小、异常表等。
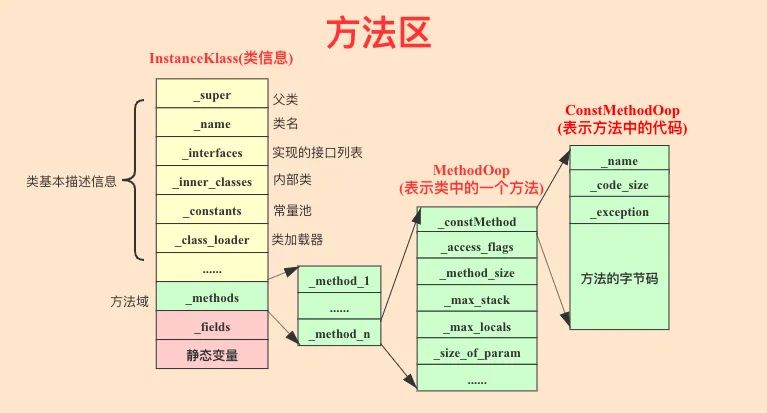
上图中InstanceKlass表示一个类的主要信息,包括黄色背景字段表示的类基本描述信息,绿色背景字段表示的方法域以及红色背景字段表示的字段域。图中重点介绍了方法域的相关细节,字段域并没有展开讲,有兴趣可以参考其他资料。_methods字段表示这个类中的所有方法(注意不包含父类方法),每个方法由MethodOop对象表示,这个对象中定义了方法名、方法参数个数、方法描述等,另外有一个非常重要的字段_constMethod指向一个ConstMethodOop对象,这个对象主要存储对应方法的字节码,是一个方法重要的部分。

堆区核心数据结构
堆区主要存放对象实例和数组实例。随着程序不断运行,对象总是源源不断的产生,并在一段时间之后消亡,堆区就需要不断的为这些对象申请内存空间,同时不断地清理已经消亡了的对象。对于堆区内存的管理,将是整个Java内存管理核心的内容,接下来整个系列的后续文章也将会围绕这个主题展开来讲。这里主要简单说明一下堆区存储的主要内容就是对象,对象的数据结构如下图所示:
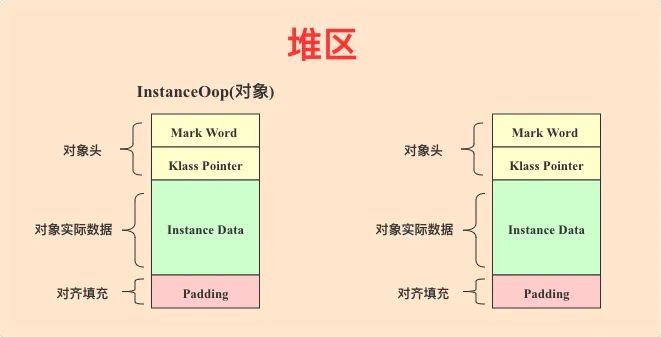
对象这个数据结构需要讲解的地方比较多,因此笔者在下一节会展开来讲。简单来说,对象主要由3部分构成:对象头,对象实际字段以及对齐填充。
● 对象头由Mark Word以及Klass Pointer两个部分构成,前者主要存储对象的一些锁、GC年龄信息等;后者是一个指针,指向方法区对应的类。
● 对象实际数据存储的是这个对象的字段信息,注意,对象中不存储任何方法相关数据,所有方法相关数据主要分布在虚拟机栈区和方法区。
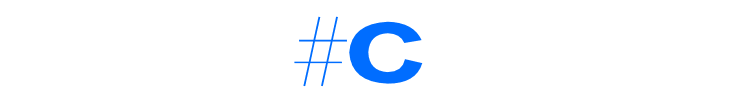
虚拟机栈区核心数据结构
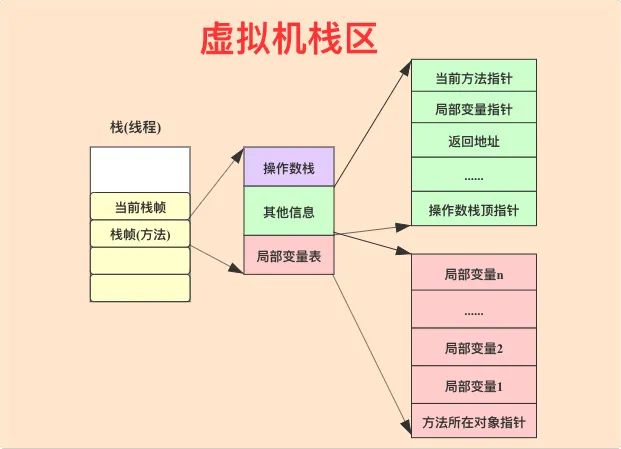
上文提到虚拟机栈主要用于线程执行过程中方法的入栈和出栈。每个运行线程都会有一个独立的栈,如下图所示,线程运行每次调用一个方法就会产生一个栈帧,栈帧表示一个方法,主要由3个部分构成,分别是局部变量表、栈帧其他信息以及操作数栈。
● 局部变量表:主要存储方法执行的入参以及方法中的局部变量。局部变量可以是基本数据类型(比如boolean、byte、char、short、int、long、float以及double等),也可以是引用数据类型(比如在方法中new出来的一个对象变量)。需要特别注意的是,如果是实例方法(非static方法),局部变量表的个元素总是该方法所在对象的指针,也就是this关键字指向的对象。
● 操作数栈:主要存储方法执行过程中的操作指令。比如方法中有一个整数加法,对应的字节码指令是iadd,执行前对应的两个整数已经存在于操作数栈接近栈顶的两个位置,执行iadd时会将这两个元素出栈并执行相加,再将相加后的结果写入栈顶。如果一个线程请求的栈深度大于虚拟机所允许的大深度,将抛出StackOverflowError异常。
● 其他信息:主要存储当前方法指针,解释起来有点复杂,简单来说就是指向方法对应字节码在方法区中的地址。

这些内存模块是如何相互协作来完成一个简单的Java程序的运行的?
上文第二节集中对运行时数据区的方法区、堆区以及虚拟机栈区存储的核心数据结构进行了介绍,让大家有一个基础的认识。这一节笔者想通过一个简单的示例来说明这三者是如何相互协作完成一个简单的Java程序的运行的。下面是一个示例程序:
public class Math { public int a; public int b; public static int c = 5;
public Math(int a, int b) { this.a = a; this.b = b; }
public int add(int x, int y) { int z = (x + y) * c; return z; }
public static void main(String[] args) { Math m = new Math(1, 1); int res = m.add(m.a, m.b); System.out.println(res); }}1. JVM启动之后会在classpath中查找main函数所在的类并加载到方法区。对应到上述代码,即会将Math类加载到方法区。具体加载过程不是本文重点,可以参考其他相关文档。加载到方法区的Math类可以通过工具HSDB查看:
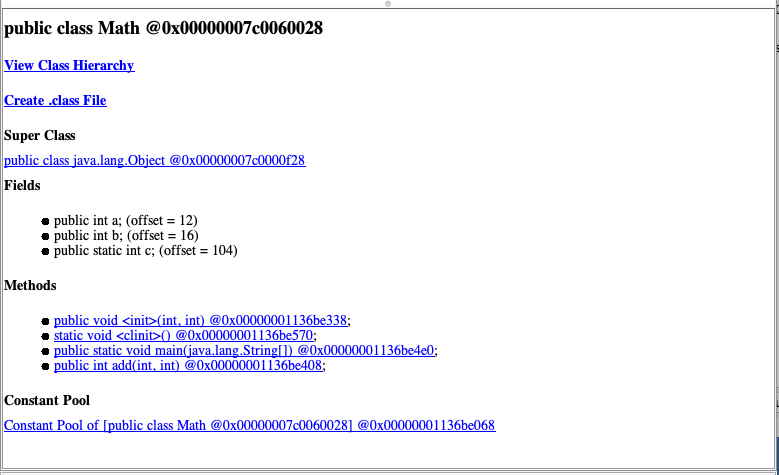
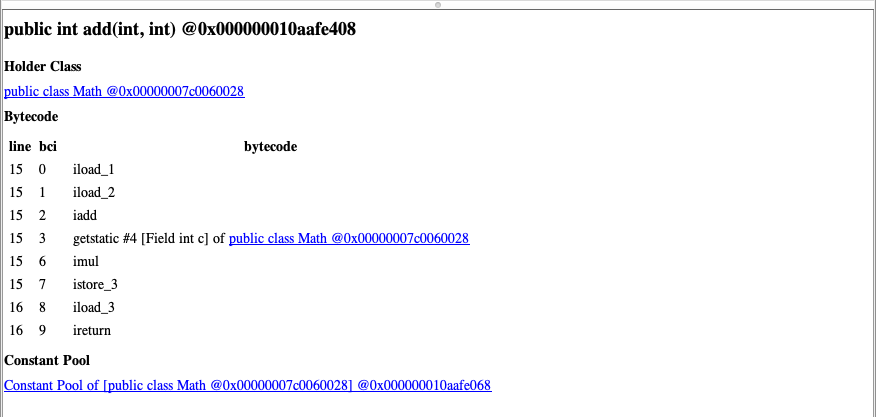
上图中主要列出了Math类的父类、Field列表、 Method列表以及常量池。其中重点看一下add方法,如下图所示,主要内容为对应的字节码:
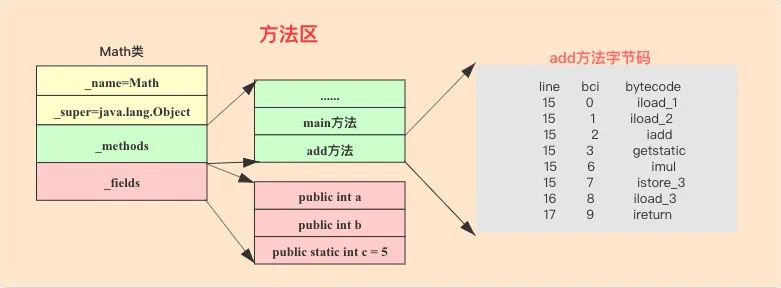
经过上述HSDB工具的指导,我们可以画出一个比较粗略的Math类结构图,如下所示:
2. 将Math类加载到方法区后,JVM会启动一个主线程以main方法作为入口执行计算,虚拟机会在虚拟机栈区将main方法入栈,紧接着执行Math p = new Math()创建一个对象,创建的对象使用HSDB查看如下图所示:
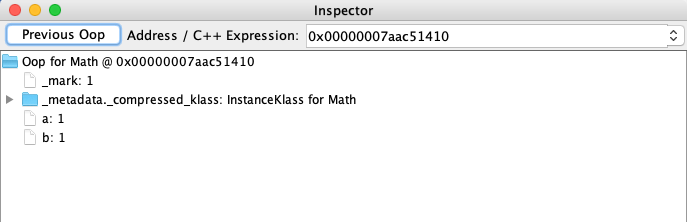
此时,Java运行时数据区的虚拟机栈区、堆区以及方法区之间的关系如下图所示:
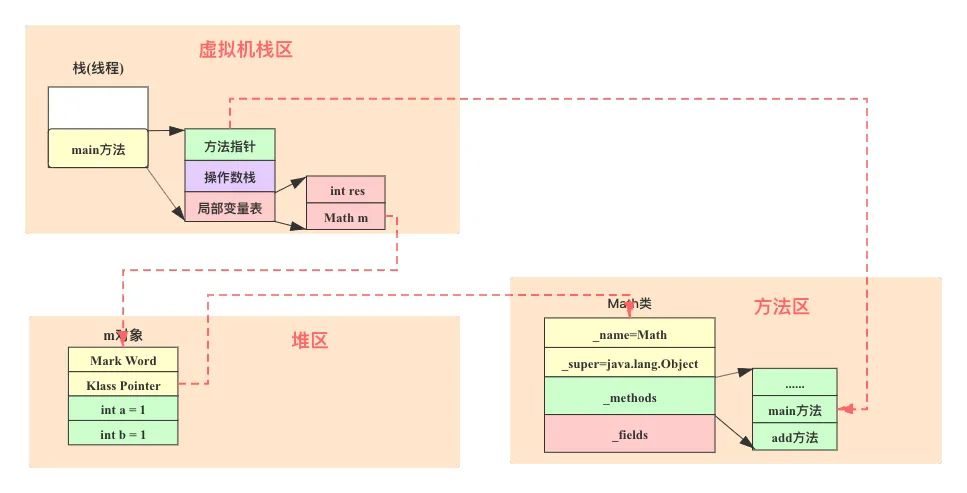
其中虚拟机栈区栈帧main方法的局部变量表中有个引用类型变量m指向堆区的m对象,m对象通过Klass Pointer指针指向方法区的Math类,同时栈区main方法的方法指针指向方法区的main方法,主要引用对应的方法字节码。
3. main方法执行完Math m = new Math之后,紧接着会调用m.add方法。此时虚拟机栈会将add方法入栈,对应的Java运行时数据区如下图,与步骤2类似,在此不再赘述。
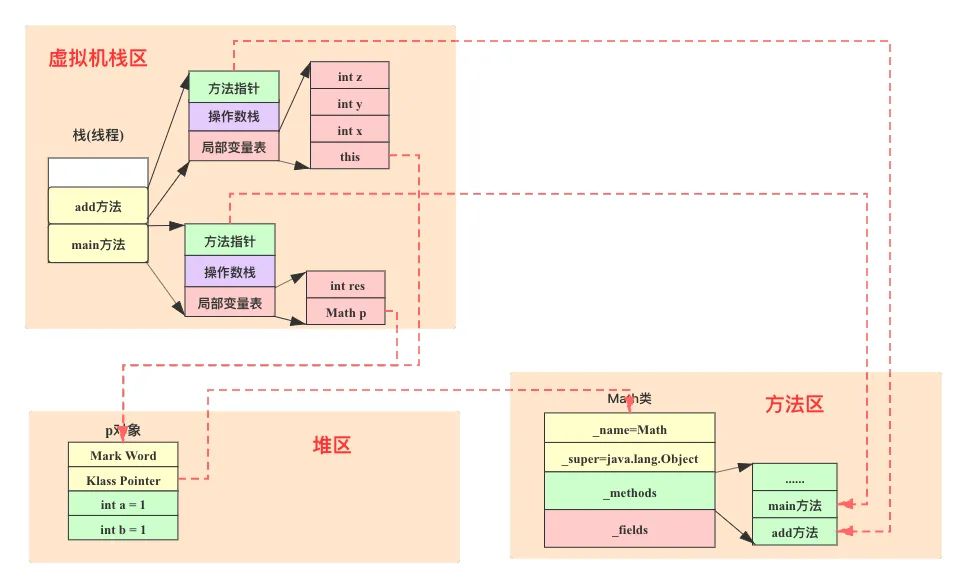
接着重点介绍一下add方法的执行是如何借用虚拟机栈中的操作数栈来完成的。下述代码为add方法的字节码,注释部分为使用操作数栈实现的逻辑:
Bytecode line bci bytecode15 iload_1 //将第1个int型本地变量(参数x=1)推送至栈顶15 1 iload_2 //将第1个int型本地变量(参数y=1)推送至栈顶15 2 iadd //将栈顶两int型数值出栈,然后相加并将结果压入栈顶15 3 getstatic //获取类静态字段(参数c=5)推送至栈顶15 6 imul //将栈顶两int型数值出栈,然后相乘并将结果压入栈顶15 7 istore_3 //将栈顶int类型数值(上一步的乘积)出栈并存入第3个本地变量16 8 iload_3 //将第3个int类型本地变量推送至栈顶17 9 ireturn //从当前方法返回int类型值「作者简介」
范欣欣
网易杭州研究院技术专家。负责网易内部Hadoop&HBase等组件内核开发运维工作,擅长大数据领域架构设计,性能优化以及问题诊断。著有《HBase原理与实践》一书。
