
图片源自 Unsplash, Florian Klauer
在数据科学项目的任何阶段,Python均可提供相关工具。所有数据科学项目都包含以下3个阶段。
- 数据收集
- 数据建模
- 数据可视化
Python可为这三个阶段提供非常巧妙的工具。

数据收集
1) Beautiful Soup
https://pypi.org/project/beautifulsoup4/

Digital Ocean
数据收集包括从网页上获取数据,python可为此提供一个名为beautifulsoup的库。
from bs4 import Beautiful
Soup soup = BeautifulSoup(html_doc, 'html.parser')该库可解析、有序存储网页内容。例如,该库将根据标题分别存储,包括存储所有<a>标签,在页面中呈现非常简洁的URL列表。
举个例子,请看《爱丽丝梦游仙境》中一个故事的简单网页。

网页截图
显然,从中存在一些可获取的html元素。
1.标题—睡鼠的故事
2.页面文本
3.超链接 — Elsie,Lacie和Tillie。
Soup可轻松提取这些信息。
soup.title
# <title>The Dormouse's story</title>
soup.title.string
# u'The Dormouse's story'
soup.p
# <p class="title"><b>The Dormouse's story</b></p>
for link in soup.find_all('a'):
print(link.get('href'))
# http://example.com/elsie
# http://example.com/lacie
# http://example.com/tillie
print(soup.get_text())
# The Dormouse's story
#
# Once upon a time there were three little sisters; and their names
were
# Elsie,
# Lacie and
# Tillie;
# and they lived at the bottom of a well.
#
# ...该工具可从HTML和XML文件中提取数据,表现出色,也因此成为导航、搜索和修改解析树的惯用方法。使用该工具通常可节省程序员的工作时间,从几小时到几天不等。
2) Wget
https://pypi.org/project/wget/

来源 : Fossmint
下载数据,尤其是从网页上下载数据,是数据科学家们的重要任务之一。Wget是一款免费的程序,以非交互式方式从网页上下载文件。由于具有非交互式特征,即使用户未登录,程序也可在后台运行。程序支持HTTP、HTTPS和FTP协议,可通过HTTP代理进行检索。因此,下次如果从网页上下载一个网站或所有图片时,可以考虑使用wget。
>>> import wget
>>> url = 'www.futurecrew.com/skaven/song_files/mp3/razorback.mp3'
>>> filename = wget.download(url)
[................................................] 3841532 /
3841532
>>> filename
'razorback.mp3'3) Data APIs
除了需要用于获取或下载数据的工具外,还需要实际数据。Data APIs在这一点上很有帮助。Python中存在许多API,供您免费下载数据。例如,Alpha Vantage可提供全球股票、外汇和加密货币的实时数据和历史数据。Data APIs拥有长达20年的数据。
例如,我们可以使用alpha vantage API,提取有关比特币每日价值的数据并进行绘制:
from alpha_vantage.cryptocurrencies
import CryptoCurrenciesimport matplotlib.pyplot as plt
cc = CryptoCurrencies(key='YOUR_API_KEY',output_format='pandas')
data, meta_data = cc.get_digital_currency_daily(symbol='BTC',
market='USD')
data['1a. open (USD)'].plot()
plt.tight_layout()
plt.title('Alpha Vantage Example - daily value for bitcoin (BTC) in US
Dollars')
plt.show()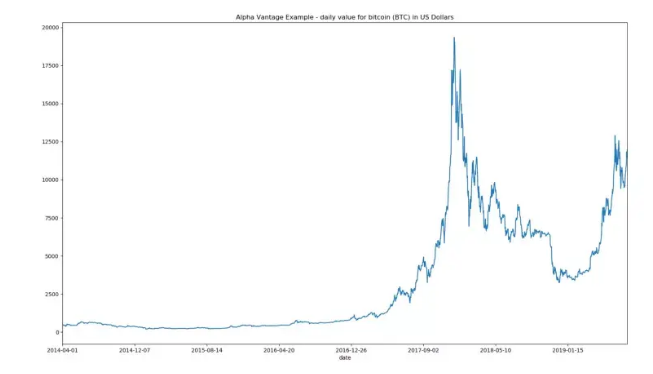
Plotted Image
API的其他用途如下:
- 开启通知API — NASA和国际空间站数据
- 汇率API — 欧洲中央银行公布的当前和历史汇率

用于数据收集的几个API

数据建模
如本文所述,数据清洗或平衡是数据建模前的重要步骤。
1)Imbalanced-learn
http://glemaitre.github.io/imbalanced-learn/index.html
Imabalanced-learn用于平衡数据集。较其他类别而言,如果同一级别或类别的数据样本差异比例较大,那么该数据集就是不平衡的。这可能导致分类算法面临巨大考验,终偏向具有更多数据的类别。
例如,来自该库的名为Tomek-Links的命令有助于平衡数据集:
from imblearn.under_sampling import TomekLinks
tl = TomekLinks(return_indices=True, ratio='majority')
X_tl, y_tl, id_tl = tl.fit_sample(X, y)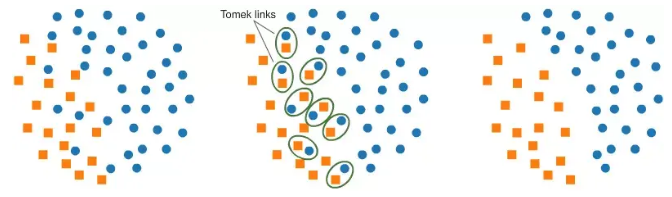
平衡失衡的数据集
2) Scipy Ecosystem — NumPy
https://www.numpy.org/
通过python的scipy堆栈,对实际数据进行处理或建模。Python的SciPy Stack是专为Pytho中的科学计算而设计的软件集合。Scipy ecosystem包含许多有用的库,但Numpy可以说是其中强大的工具。
NumPy全称为Numerical Python,是构建科学计算堆栈基础的软件包。它为矩阵操作提供了很多有用的功能。如果使用过MATLAB,就会立刻发现NumPy不仅与MATLAB一样功能强大,而且在操作上也非常相似。
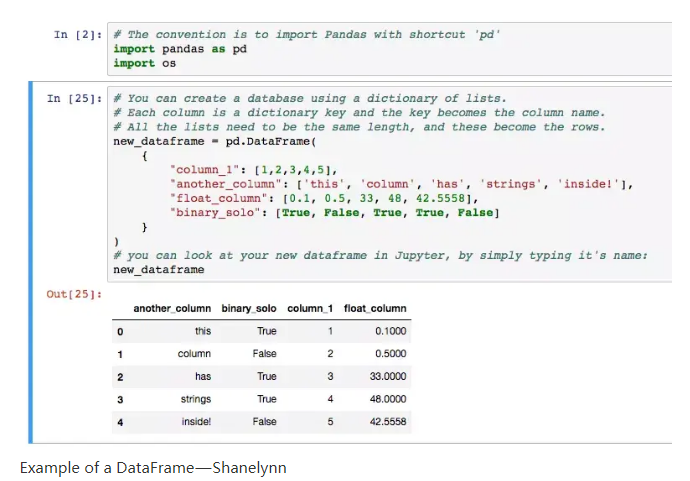
3) Pandas
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.html
Pandas可提供数据结构,处理并操纵数据。被称为dataframe的二维结构是受欢迎的结构。
Pandas是处理数据的完美工具,旨在进行快速简便的数据操作、聚合和可视化。
数据可视化
1) Matplotlib
Matplotlib是来自Scipy ecosystem的另一软件包,它可以轻松生成简单而强大的可视化。该软件是2D绘图库,可生成出版质量级别的图形,具有多种硬拷贝格式。
以下是Matplotlib输出的例子:
import numpy as np
import matplotlib.pyplot as plt
N = 5
menMeans = (20, 35, 30, 35, 27)
womenMeans = (25, 32, 34, 20, 25)
menStd = (2, 3, 4, 1, 2)
womenStd = (3, 5, 2, 3, 3)
ind = np.arange(N) # the x locations for the groups
width = 0.35 # the width of the bars: can also be len(x) sequence
p1 = plt.bar(ind, menMeans, width, yerr=menStd)
p2 = plt.bar(ind, womenMeans, width,
bottom=menMeans, yerr=womenStd)
plt.ylabel('Scores'
)plt.title('Scores by group and gender')
plt.xticks(ind, ('G1', 'G2', 'G3', 'G4', 'G5'))
plt.yticks(np.arange(0, 81, 10))
plt.legend((p1[0], p2[0]), ('Men', 'Women'))
plt.show()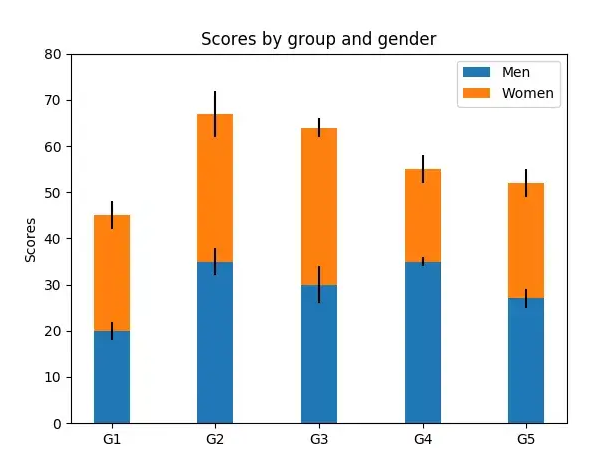
Bar Plot
其他例子
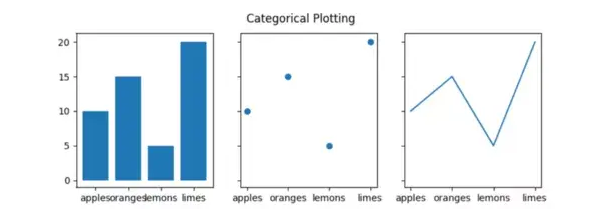

Taken from Matplotlib Docs
2) Seaborn
https://seaborn.pydata.org/
Seaborn是基于matplotlib的Python数据可视化库,主要用于绘制有吸引力且信息丰富的统计图形,提供界面。该软件主要关注可视化,如热量地图。
Seaborn docs
3) MoviePy
https://pypi.org/project/moviepy/
MoviePy是用于视频编辑的Python库,可剪切、采集、插入标题、合成、处理视频以及创建自定义效果。软件可读写所有常见格式的音频和视频,包括GIF。

https://zulko.github.io/moviepy/gallery.html
4)Bonus NLP Tool — FuzzyWuzzy
>>> fuzz.ratio("this is a test", "this is a test!")
97
>>> fuzz.partial_ratio("this is a test", "this is a test!")
100
>>> fuzz.ratio("fuzzy wuzzy was a bear", "wuzzy fuzzy was a bear")
91
>>> fuzz.token_sort_ratio("fuzzy wuzzy was a bear", "wuzzy fuzzy was a
bear")
100
作者:读芯术
链接:https://juejin.im/post/5d97f40ee51d457806260eda
来源:掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
