作者:手艺人
来源:公众号IT烂笔头
1
String基础
public final class StringString类是由final修饰的,所以是不能被继承的①,我们在对字符串进行比较时,一般是期望对比其中的字符串是否一样,所以这里我们不能用"=="进行字符串的比较,而是需要使用"equals()"方法②,因为使用==进行比较时,是比较的对象,只有指向同一个字符串对象的才会是true,否则就算字符串值相同也可能出现不相等的情况。
private final char value[];String的值实际上是以char的数组存储的,并且是final的,所以字符串对象是不可变的③,但是我们可以看到字符串的一些操作会误导我们,比如使用:
String a = "aaaa";a += "bbbb";其实这个时候a已经指向新的对象地址。
到这里为止,初级工程师都应该很熟悉。
2
String的形式
在思考String能有多长之前,我们先看下String定义的不同形式。
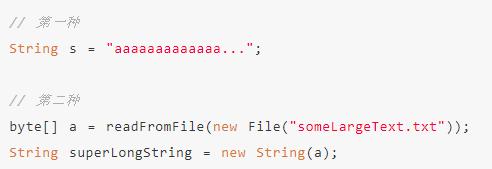
那么既然思考String的长度,那就应该想想为什么会有长度的限制,难道我在编译器里定义一个String时,有多长不是随便我们自己输入吗?还有上面两种方式有什么区别呢?
2.1 字面量的形式
对于种是字面量,Java将其存在常量池中,在Java1.6的版本中是在栈的常量池中,在1.7、1.8版本中将其放到了堆的常量池中。那就是说种这种方式中是受到常量池大小的约束了,不错,是会受到常量池的约束,但是在运行在JVM之前,被编译成字节码时就已经有了限制。
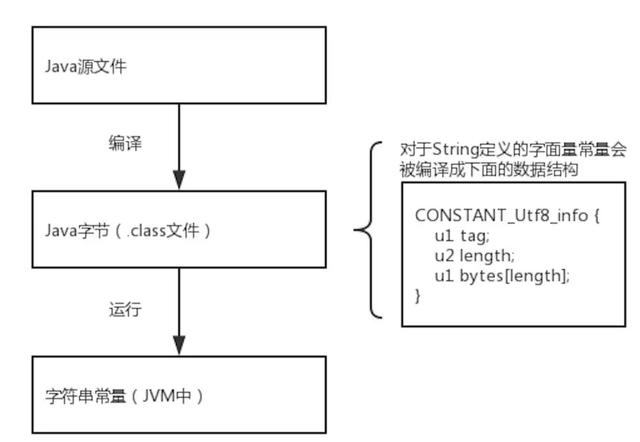
如上图所示,编译后的length的类型为u2(无符号16位),也就是讲length的大值为2^16-1 = 65535,那就是讲我们的上面的字符串s长度按MUTF-8(字节码中的编码)编码可以存储65535个字节。
到这里为止,如果你是工程师,知道这么多已经很不错了。
可是事实上呢,我们实验后发现只能存储65534个字节,这是为什么呢?网上有很多猜想,大部分不正确。我们扒一下Java编译器的源码,会发现:
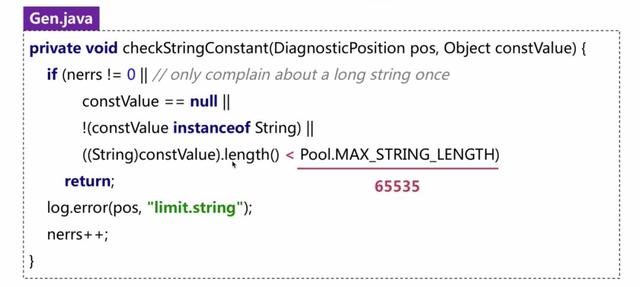
这下大家明白了吧,Java编译器在检查字符串常量时,判断的是长度只有<65535才会正常,否则报错。看起来像是编译器的Bug。如果你会修改编译器源码,你将上面的判断条件改成<=65535,这样你存一个65535个字符"a"的字符串就不会编译出错了。
我们知道上面我们是用拉丁字符"a"来测试的,a使用UTF-8编码刚好是一个字节,所以可以存储65534个,那如果存汉字呢,比如我们经常看到的"烫",它使用TF-8编码后占用三个字节,那么也就是说我们可以这样定义:
// 按照我们刚才的分析,应该可以存储65534/3个"烫"汉字String s = "烫烫烫...烫烫";
那我们尝试存储65535/3个汉字"烫"试试呢?结果是可以的,并没有报错。诶?这是为什么呢?我们继续扒下编译器的源码看到:
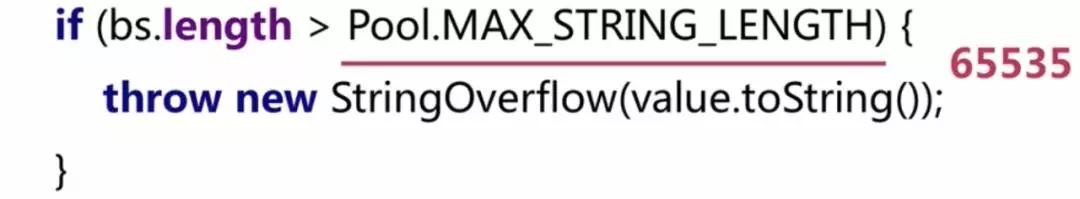
编译处理汉字这种的呢,他判断的逻辑不一样。条件是>65535才会抛异常,也就是小于等于65535是正常的。很有意思,写Java编译器的人也很有意思哈。
2.1 new的形式
对于第二种形式的,很显然只有在运行时受限于Java虚拟机了。我们知道String后保存在char数组中,Java虚拟机是如何做的呢?简单参考下源码:

虚拟机指令newarray [int],size是以整形定义的,所以它的限制其实就是int的大值,但是在有一些虚拟机上会保留一些头信息在数组中,所以就变成了Integer.MAX_VALUE - 8个char;
到这里呢,基本上你就有了工程师的思考高度了。
3
总结
3.1 字面量的形式
受字节码数据结构的限制,字符串使用MUTF-8编码后字节数不超过65535
拉丁字符,受Java编译器代码限制,多只能存储65534个字节
非拉丁字符,多存储65535个字节
3.2 new的形式
受虚拟机指令限制,字符数理论上线是Integer.MAX_VALUE,但是实际上有保留头信息的部分,所以会略小
受堆内存的限制,如果堆内存很小,那就不能超过堆内存的限制
看起来本文有点过于追求细节了,有点孔乙己的回字有几种写法的意思。实际则不然,搞技术就是要把握好细节,才能写出的代码,才能成为高阶的工程师而不是码农。
