应该注意到的是,我们创建的节点为临时节点,要想实现监控报警功能,必须要为临时节点。
5.4 监控程序
首先需要先监听zookeeper中的一个节点目录,在我们的系统中,设计是监听/ispider这个节点目录:
public SpiderMonitorTask() {
String zkStr = "uplooking01:2181,uplooking02:2181,uplooking03:2181";
int baseSleepTimeMs = 1000;
int maxRetries = 3;
RetryPolicy retryPolicy = new ExponentialBackoffRetry(baseSleepTimeMs, maxRetries);
curator = CuratorFrameworkFactory.newClient(zkStr, retryPolicy);
curator.start();
try {
previousNodes = curator.getChildren().usingWatcher(this).forPath("/ispider");
} catch (Exception e) {
e.printStackTrace();
}
}在上面注册了zookeeper中的watcher,也就是接收通知的回调程序,在该程序中,执行我们报警的逻辑:
/**
* 这个方法,当监控的zk对应的目录一旦有变动,就会被调用
* 得到当前新的节点状态,将新的节点状态和初始或者上一次的节点状态作比较,那我们就知道了是由谁引起的节点变化
* @param event
*/
@Override
public void process(WatchedEvent event) {
try {
List<String> currentNodes = curator.getChildren().usingWatcher(this).forPath("/ispider");
// HashSet<String> previousNodesSet = new HashSet<>(previousNodes);
if(currentNodes.size() > previousNodes.size()) { // 新的节点服务,超过之前的节点服务个数,有新的节点增加进来
for(String node : currentNodes) {
if(!previousNodes.contains(node)) {
// 当前节点就是新增节点
logger.info("----有新的爬虫节点{}新增进来", node);
}
}
} else if(currentNodes.size() < previousNodes.size()) { // 有节点挂了 发送告警邮件或者短信
for(String node : previousNodes) {
if(!currentNodes.contains(node)) {
// 当前节点挂掉了 得需要发邮件
logger.info("----有爬虫节点{}挂掉了", node);
MailUtil.sendMail("有爬虫节点挂掉了,请人工查看爬虫节点的情况,节点信息为:", node);
}
}
} // 挂掉和新增的数目一模一样,上面是不包括这种情况的,有兴趣的朋友可以直接实现包括这种特殊情况的监控
previousNodes = currentNodes; // 更新上一次的节点列表,成为新的节点列表
} catch (Exception e) {
e.printStackTrace();
}
// 在原生的API需要再做一次监控,因为每一次监控只会生效一次,所以当上面发现变化后,需要再监听一次,这样下一次才能监听到
// 但是在使用curator的API时则不需要这样做
}
当然,判断节点是否挂掉,上面的逻辑还是存在一定的问题的,按照上面的逻辑,假如某一时刻新增节点和删除节点事件同时发生,那么其就不能判断出来,所以如果需要更精准的话,可以将上面的程序代码修改一下。
5.5 邮件发送模块
使用模板代码就可以了,不过需要注意的是,在使用时,发件人的信息请使用自己的邮箱。
下面是爬虫节点挂掉时接收到的邮件:
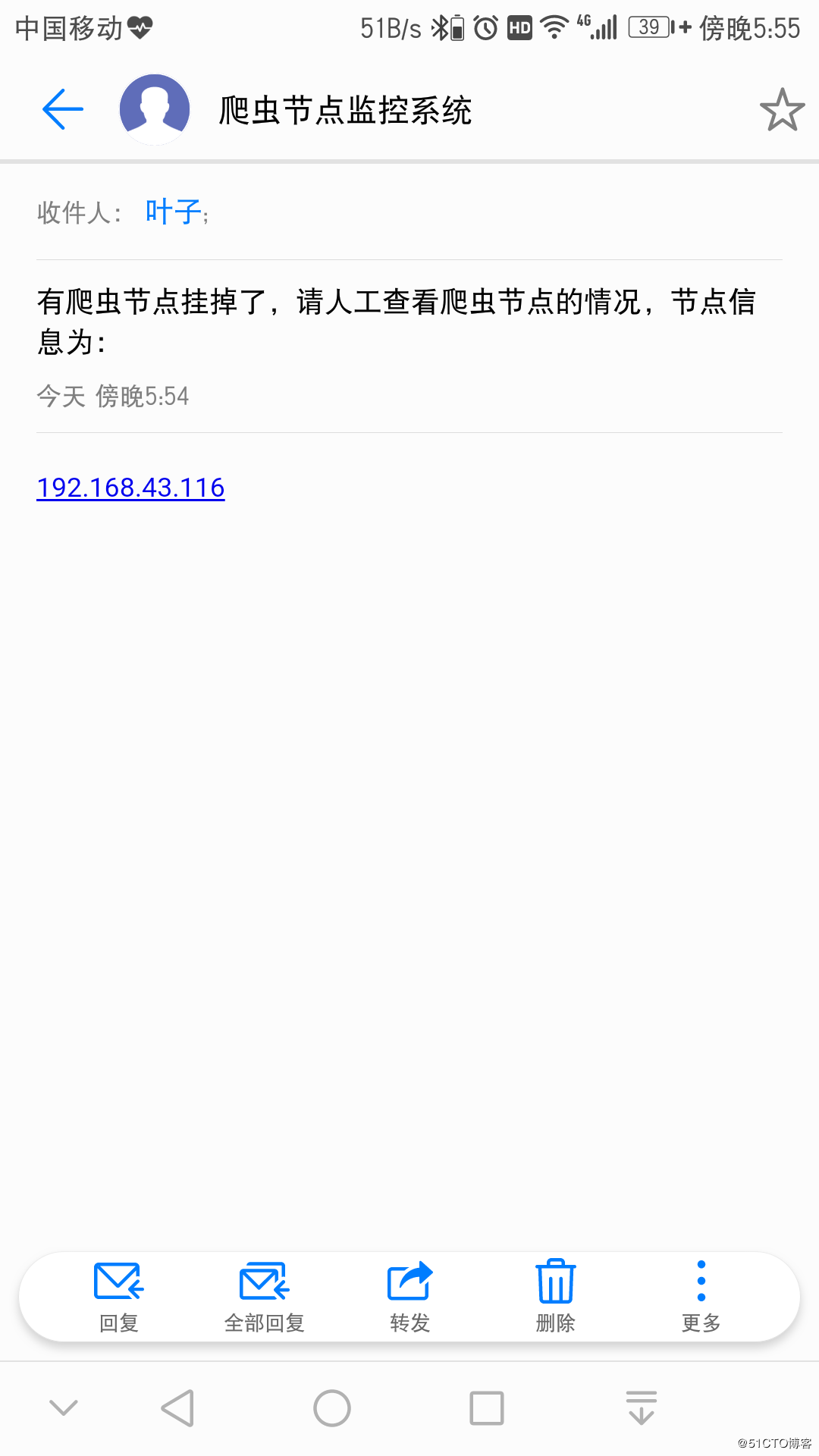
实际上,如果购买了短信服务,那么通过短信API也可以向我们的手机发送短信。
6 实战:爬取京东、苏宁易购全网手机商品数据
因为前面在介绍这个系统的时候也提到了,我只写了京东和苏宁易购的网页解析器,所以接下来也就是爬取其全网的手机商品数据。
6.1 环境说明
需要确保Redis、Zookeeper服务可用,另外如果需要使用HBase来存储数据,需要确保Hadoop集群中的HBase可用,并且相关配置文件已经加入到爬虫程序的classpath中。
还有一点需要注意的是,URL定时器和监控报警系统是作为单独的进程来运行的,并且也是可选的。
6.2 爬虫结果
进行了两次爬取,分别尝试将数据保存到MySQL和HBase中,给出如下数据情况。
6.2.1 保存到MySQL
mysql> select count(*) from phone;
+----------+
| count(*) |
+----------+
| 12052 |
+----------+
1 row in set
mysql> select count(*) from phone where source='jd.com';
+----------+
| count(*) |
+----------+
| 9578 |
+----------+
1 row in set
mysql> select count(*) from phone where source='suning
.com';
+----------+
| count(*) |
+----------+
| 2474 |
+----------+
1 row in set在可视化工具中查看数据情况: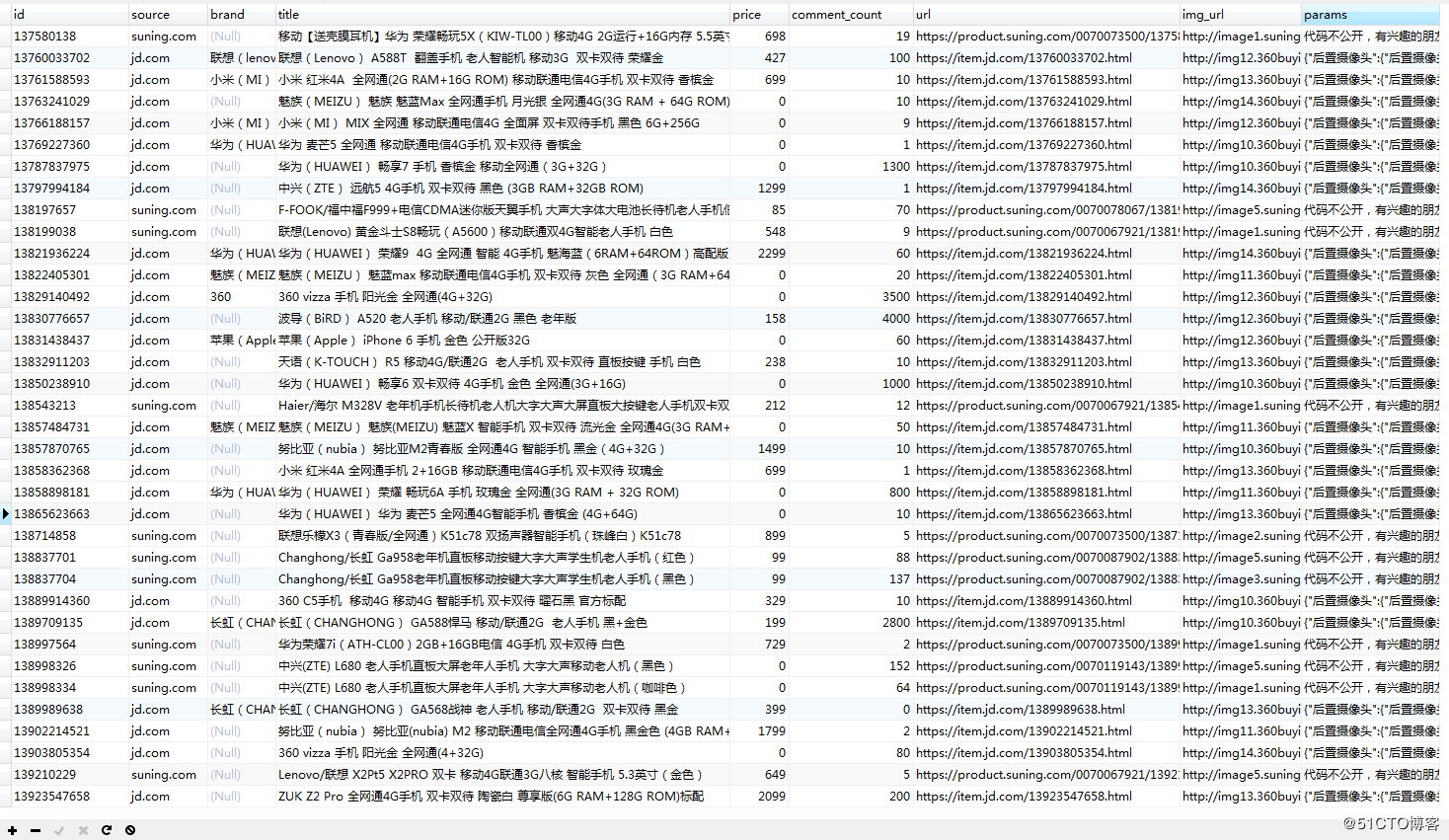
6.2.2 保存到HBase
hbase(main):225:0* count 'phone'
Current count: 1000, row: 11155386088_jd.com
Current count: 2000, row: 136191393_suning.com
Current count: 3000, row: 16893837301_jd.com
Current count: 4000, row: 19036619855_jd.com
Current count: 5000, row: 1983786945_jd.com
Current count: 6000, row: 1997392141_jd.com
Current count: 7000, row: 21798495372_jd.com
Current count: 8000, row: 24154264902_jd.com
Current count: 9000, row: 25687565618_jd.com
Current count: 10000, row: 26458674797_jd.com
Current count: 11000, row: 617169906_suning.com
Current count: 12000, row: 769705049_suning.com
12348 row(s) in 1.5720 seconds
=> 12348在HDFS中查看数据情况:
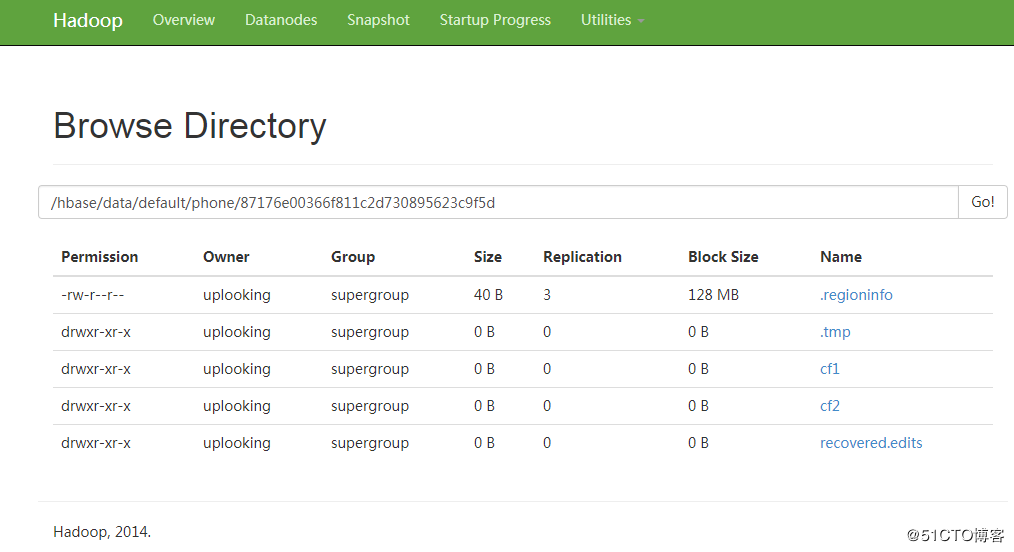
6.2.3 数据量与实际情况分析
- 京东
京东手机的列表大概有160多页,每个列表有60个商品数据,所以总量在9600左右,我们的数据基本是符合的,后面通过日志分析其实可以知道,一般丢失的数据为连接超时导致的,所以在选取爬虫的环境时,更建议在网络环境好的主机上进行,同时如果可以有IP代理地址库就更好了,另外对于连接超时的情况,其实是可以进一步在我们的程序中加以控制,一旦出现爬取数据失败的url,可以将其加入到重试url队列中,目前这一点功能我是没有做,有兴趣的同学可以试一下。
- 苏宁易购
再来看看苏宁的,其有100页左右的手机列表,每页也是60个商品数据,所以总量在6000左右。但可以看到,我们的数据却只有3000这样的数量级(缺少的依然是频繁爬取造成的连接失败问题),这是为什么呢?
这是因为,打开苏宁的某个列表页面后,其是先加载30个商品,当鼠标向下滑动时,才会通过另外的API去加载其它的30个商品数据,每一个列表页面都是如此,所以,实际上,我们是缺少了一半的商品数据没有爬取。知道这个原因之后,实现也不难,但是因为时间关系,我就没有做了,有兴趣的朋友折腾一下吧。
6.3 通过日志分析爬虫系统的性能
在我们的爬虫系统中,每个关键的地方,如网页下载、数据解析等都是有打logger的,所以通过日志,可以大概分析出相关的时间参数。
2018-04-01 21:26:03 [pool-1-thread-1] [cn.xpleaf.spider.utils.HttpUtil] [INFO] - 下载网页:https://list.jd.com/list.html?cat=9987,653,655&page=1,消耗时长:590 ms,代理信息:null:null
2018-04-01 21:26:03 [pool-1-thread-1] [cn.xpleaf.spider.core.parser.Impl.JDHtmlParserImpl] [INFO] - 解析列表页面:https://list.jd.com/list.html?cat=9987,653,655&page=1, 消耗时长:46ms
2018-04-01 21:26:03 [pool-1-thread-3] [cn.xpleaf.spider.core.parser.Impl.SNHtmlParserImpl] [INFO] - 解析列表页面:https://list.suning.com/0-20006-0.html, 消耗时长:49ms
2018-04-01 21:26:04 [pool-1-thread-5] [cn.xpleaf.spider.utils.HttpUtil] [INFO] - 下载网页:https://item.jd.com/6737464.html,消耗时长:219 ms,代理信息:null:null
2018-04-01 21:26:04 [pool-1-thread-2] [cn.xpleaf.spider.utils.HttpUtil] [INFO] - 下载网页:https://list.jd.com/list.html?cat=9987,653,655&page=2&sort=sort_rank_asc&trans=1&JL=6_0_0,消耗时长:276 ms,代理信息:null:null
2018-04-01 21:26:04 [pool-1-thread-4] [cn.xpleaf.spider.utils.HttpUtil] [INFO] - 下载网页:https://list.suning.com/0-20006-99.html,消耗时长:300 ms,代理信息:null:null
2018-04-01 21:26:04 [pool-1-thread-4] [cn.xpleaf.spider.core.parser.Impl.SNHtmlParserImpl] [INFO] - 解析列表页面:https://list.suning.com/0-20006-99.html, 消耗时长:4ms
......
2018-04-01 21:27:49 [pool-1-thread-3] [cn.xpleaf.spider.utils.HttpUtil] [INFO] - 下载网页:https://club.jd.com/comment/productCommentSummaries.action?referenceIds=23934388891,消耗时长:176 ms,代理信息:null:null
2018-04-01 21:27:49 [pool-1-thread-3] [cn.xpleaf.spider.core.parser.Impl.JDHtmlParserImpl] [INFO] - 解析商品页面:https://item.jd.com/23934388891.html, 消耗时长:413ms
2018-04-01 21:27:49 [pool-1-thread-2] [cn.xpleaf.spider.utils.HttpUtil] [INFO] - 下载网页:https://review.suning.com/ajax/review_satisfy/general-00000000010017793337-0070079092-----satisfy.htm,消耗时长:308 ms,代理信息:null:null
2018-04-01 21:27:49 [pool-1-thread-2] [cn.xpleaf.spider.core.parser.Impl.SNHtmlParserImpl] [INFO] - 解析商品页面:https://product.suning.com/0070079092/10017793337.html, 消耗时长:588ms
......平均下来,下载一个商品网页数据的时间在200~500毫秒不等,当然这个还需要取决于当时的网络情况。
另外,如果想要真正计算爬取一个商品的数据,可以通过日志下面的数据来计算:
- 下载一个商品页面数据的时间
- 获取价格数据的时间
- 获取评论数据的时间
在我的主机上(CPU:E5 10核心,内存:32GB,分别开启1个虚拟机和3个虚拟机),情况如下:
| 节点数 | 每节点线程数 | 商品数量 | 时间 |
|---|---|---|---|
| 1 | 5 | 京东+苏宁易购近13000个商品数据 | 141分钟 |
| 3 | 5 | 京东+苏宁易购近13000个商品数据 | 65分钟 |
可以看到,当使用3个节点时,时间并不会相应地缩小为原来的1/3,这是因为此时影响爬虫性能的问题主要是网络问题,节点数量多,线程数量大,网络请求也多,但是带宽一定,并且在没有使用代理的情况,请求频繁,连接失败的情况也会增多,对时间也有一定的影响,如果使用随机代理库,情况将会好很多。
但可以肯定的是,在横向扩展增加爬虫节点之后,确实可以大大缩小我们的爬虫时间,这也是分布式爬虫系统的好处。
7 爬虫系统中使用的反反爬虫策略
在整个爬虫系统的设计中,主要使用下面的策略来达到反反爬虫的目的:
- 使用代理来访问-->IP代理库,随机IP代理
- 随机域名url访问-->url调度系统
- 每个线程每爬取完一条商品数据sleep一小段时间再进行爬取
8 总结
需要说明的是,本系统是基于Java实现的,但个人觉得,语言本身依然不是问题,核心在于对整个系统的设计上以及理解上,写此文章是希望分享这样一种分布式爬虫系统的架构给大家,如果对源代码感兴趣,可以到我的GitHub上查看。

