近在Presto与Alluxio社区的通力合作下给Presto引擎带来了新的数据缓存机制,今天我们来分析一下这一部分的实现机制。
为什么
为什么Presto社区会开发这个缓存机制呢?我的理解是这样的: 在这个云计算时代,越来越流行的计算存储分离架构方式使得我们对计算需要的资源和存储需要的资源进行单独扩展,从扩展的角度这是很好的,但是副作用也是有的,它使得原本很近的计算和存储变远了。计算引擎要获取与之前同等大小的数据比之前的代价大了。在计算和存储分离的情况下,用户的数据往往保存在阿里云OSS或者AWS S3这些Blob存储上,如果要想以足够快的速度从Blob存储服务获取数据,我们需要计算引擎和存储之间有足够大的带宽,如果带宽资源不够,整个查询的性能就不会很好。那么这时缓存机制就可以发挥作用了,只要用户的查询有一定的重复性,那么部分数据就可以直接从本地缓存获取,省去从远端存储获取的时间,提高查询的性能。
Presto缓存的整体架构
Presto为缓存添加了一个新的模块: presto-cache, presto-hive 与 presto-cache 之间的交互流程大概是这样的:
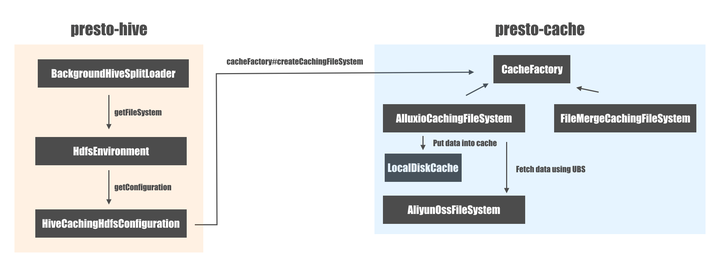
虽然presto-cache这个名字听起来好像可以作用于所有的connector,但是从实际实现来看,只有presto-hive connector会与presto-cache模块有交互。在Presto缓存被引入之前 BackgroundHiveSplitLoader 使用底层的文件系统(比如对于阿里云的OSS, 它是AliyunOssFileSystem)直接进行数据的读写;引入了Presto缓存机制之后,底层的文件系统被被CachingFileSystem 代理一层:
// HiveCachingHdfsConfiguration.java
Configuration config = new CachingJobConf((factoryConfig, factoryUri) -> {
try {
FileSystem fileSystem = (new Path(factoryUri)).getFileSystem(hiveHdfsConfiguration.getConfiguration(context, factoryUri));
checkState(fileSystem instanceof ExtendedFileSystem);
return cacheFactory.createCachingFileSystem(
factoryConfig,
factoryUri,
(ExtendedFileSystem) fileSystem,
cacheManager,
cacheConfig.isCachingEnabled(),
cacheConfig.getCacheType(),
cacheConfig.isValidationEnabled());
}
catch (IOException e) {
throw new PrestoException(GENERIC_INTERNAL_ERROR, "cannot create caching file system", e);
}
});CachingFileSystem有两个子类,根据你选用的底层缓存引擎的不同可能会是下面的两个之一:
- AlluxioCachingFileSystem: 使用Alluxio的本地缓存实现。
- FileMergeCachingFileSystem: Presto纯手工打造的缓存实现。
这里要注意的是AlluxioCachingFileSystem的实现并不会通过一个Alluxio的集群来对数据进行缓存,它是在Presto Worker本地利用磁盘进行了数据的缓存,因此Alluxio的朋友把它称为: Alluxio客户端本地缓存。
当需要读取一个数据块的时候,CachingFileSystem会首先在本地缓存检查这个数据块是否已经读取过了,如果已经读取过,那么Presto会直接从本地缓存读取;否则的就会通过底层的文件系统来从远端来读取数据,读取到数据之后再添加到本地的磁盘缓存,这样后续的数据读取就可以直接从缓存读取了。
为了启用Presto的缓存机制,你需要在你的 hive.properties 文件添加如下配置:
cache.enabled=true
cache.type=ALLUXIO
cache.base-directory=file:///tmp/alluxio
cache.alluxio.max-cache-size=1GB现在我们对于整个Presto缓存的原理有了一个整体的理解,下面我们再细挖一下下面两个问题:
- 为什么要把Hadoop的FileSystem接口扩展到ExtendedFileSystem?
- 如何保证缓存的命中率?
为什么要把Hadoop的FileSystem接口扩展到ExtendedFileSystem?
为了实现缓存的目的,Presto把Hadoop的FileSystem扩展为了ExtendedFileSystem:
public abstract class ExtendedFileSystem
extends FileSystem
{
public FSDataInputStream openFile(Path path, HiveFileContext hiveFileContext)
throws Exception
{
return open(path);
}
...
}扩展主要的目的是加入了 openFile 的方法,跟普通的 FileSystem#open 不同的是,这个方法添加了 HiveFileContext 参数,它包含如下的字段:
boolean cacheable;
Optional<ExtraHiveFileInfo<?>> extraFileInfo;HiveFileContext并不是Hadoop FileSystem标准API的一部分,Presto添加这个类是为了传递当前要读取的文件是否可以被缓存的上下文信息。如果它是可以被缓存的,那么Presto引擎会走缓存的代码路径,否则的话就走普通的代码路径。但是为什么需要传递一个文件是否可以缓存的信息呢?难度不是所有的文件都可以被缓存吗?我们下一节详细讨论。
如何保证缓存的命中率?
为了打造一个性能良好的缓存,缓存命中率是我们要追求的主要目标。而为了实现这个目标,我们需要Presto的任务分配机制有一定的亲和性(Affinity) -- 也就说对于同一个文件的读取请求,我们应该尽量把它分配给相同的Worker来进行处理,这样才能使得我们次放入缓存的数据会被后续的读取请求利用上。现在ConnectorSplit接口中添加了两个新的方法,所有的Connector都必须要实现:
NodeSelectionStrategy getNodeSelectionStrategy();
List<HostAddress> getPreferredNodes(List<HostAddress> sortedCandidates);NodeSelectionStrategy可能的值有三个:
- HARD_AFFINITY: Split必须分配给指定的节点(getPreferedNodes())
- SOFT_AFFINITY: Split“好”分配给指定的节点,如果不行也可以分配给其它的节点,但是性能会差一些。
- NO_PREFERENCE: Scheduler可以把Split分配给任意节点而不影响性能。
为了让Presto缓存机制可以工作,我们要使用SOFT_AFFINITY, 这样 Hive Connector 会通过下面的逻辑来计算 Prefered Nodes:
// HiveSplit.java
if (getNodeSelectionStrategy() == SOFT_AFFINITY) {
// Use + 1 as secondary hash for now, would always get a different position from the first hash.
int size = sortedCandidates.size();
int mod = path.hashCode() % size;
int position = mod < 0 ? mod + size : mod;
return ImmutableList.of(
sortedCandidates.get(position),
sortedCandidates.get((position + 1) % size));
}我们可以看到这里使用了 hash + mod 的方式使得同一个文件的Preferred Nodes 始终是一样的。
社区近准备在做一些改进,目前的算法每次要先对所有的Nodes做一个排序, 时间复杂度O(NlogN), 每次给一个path计算一个位置(hash)的时间复杂度是O(1), 总的时间复杂度是O(NlogN); 而社区准备用一致性hash进行替代,因为如果使用一致性hash算法,每次构造一致性hash的时间复杂度是O(N), 为一个path计算一个位置的时间复杂度是O(1), 总的时间复杂度是O(N)。https://github.com/prestodb/presto/pull/14692
而下面是Presto如何调度这些Split的逻辑:
// choose the preferred node first as long as they're not busy
if (preferredNodeCount.isPresent() && i < preferredNodeCount.getAsInt() && splitCount < maxSplitCount) {
if (i == 0) {
nodeSelectionStats.incrementPrimaryPreferredNodeSelectedCount();
}
else {
nodeSelectionStats.incrementNonPrimaryPreferredNodeSelectedCount();
}
return Optional.of(new InternalNodeInfo(node, true));
}
// fallback to choosing the least busy nodes
if (splitCount < min && splitCount < maxSplitCount) {
chosenNode = node;
min = splitCount;
}
return Optional.of(new InternalNodeInfo(chosenNode, false));可以看出Presto会优先选择Prefered Nodes, 而如果Prefered Nodes 已经很忙的,那么会退化到选择空闲的节点,这时候这个文件就是不可缓存的,不会走缓存相关的逻辑。
那么我们如何定义一个节点是否繁忙呢? Presto的定义逻辑是这样的:
// SimpleNodeSelector.java
int splitCount = splitCountProvider.apply(node); // splitCountProvider == assignmentStats::getTotalSplitCount
splitCount < maxSplitCount // maxSplitCount = maxSplitsPerNode只要节点上的节点数小于 maxSplitPerNode 我们就认为它是不“繁忙”的。
同时我们也注意一下InternalNodeInfo的构造函数:
public InternalNodeInfo(InternalNode internalNode, boolean cacheable)
{
this.internalNode = requireNonNull(internalNode, "internalNode is null");
this.cacheable = cacheable;
}第二参数 cachable 的含义是被分配到当前这个节点的这个Split是否是可以被缓存的: 也就是上面说的,如果是被分配给了 Perfered Nodes 就是可被缓存的,否则则不是,这么做主要也是为了提高缓存命中率,否则缓存空间可能会被后续不会被命中的文件占据。
现在我们已经给每个Split都打上了一个 cachable 的标签,那么这个信息是如何被一步步的在整个Presto引擎内部传递, 直到缓存相关的逻辑代码的地方呢? 下面是大体的调用栈:
NodeScheduler (InternalNodeInfo#cacheable)
-> PageSourceProvider (SplitContext#cacheable)
-> HivePageSourceProvider (HiveFileContext#cacheable)
-> HiveBatchPageSourceFactory (HiveFileContext#cacheable)
-> ParquetPageSourceFactory (HiveFileContext#cacheable)
-> hdfsEnvironment.getFileSystem(user, path, configuration).openFile(path, hiveFileContext)后在 AlluxioCachingFileSystem 里面, Presto会使用通过 HiveFileContext 传递过来的缓存与否的信息判断是否走缓存逻辑:
if (hiveFileContext.isCacheable()) {
return cachingFileSystem.openFile(path, hiveFileContext);
}
return dataTier.openFile(path, hiveFileContext);如果可以被缓存,走缓存文件系统;否则直接走底层的文件系统。
总结
Presto的缓存机制是一个非常有用的特性,一方面它可以提高重复性的查询的性能;另外一方面它可以降低计算引擎对于底层Blob Storage的带宽需求。虽然目前Presto缓存机制只支持Hive Connector,但是让Presto缓存机制之前其它的Connector也会是一个非常有趣的方向。
