【深度】ArteryBase事务日志(2)--从关机中恢复
@(arterybase)
概述
我们对数据库的关机、重启往往习以为常,甚至认为启动数据库和打开一个word文档差不多。实际上,在数据库启动的过程中,需要做很多事情,包括守护进程的初始化、建立辅助进程等很多复杂的工作。 本文尝试分析数据库如何利用事务日志实现从关机中恢复数据库全局状态、实现数据一致性。
术语
数据库关闭时涉及事务日志简单描述
数据库实例正常关闭时,数据库服务器会创建关机检查点并将检查点信息记录到xlog日志文件中并写回磁盘,将缓存中的数据写回磁盘。 如果数据库未正常关闭,xlog日志中将没有该次关机检查点,会存在已经提交的事务没有保存到磁盘的情况。
数据库启动时的事务日志处理概述
数据库启动时,首先启动守护进程,守护进程创建:startup process进程;该进程通过读取控制文件,找到后一个checkpoint(检查点)在xlog文件中的位置,根据位置信息在xlog中读取到检查点信息,然后判断:
如果检查点为关机检查点,说明数据正确写回磁盘,startup process进程使命完成,startup process进程关闭。
如果非正常关闭数据库,则后一个检查点不是关机检查点: (1)此时就需要对检查点以后的xlog日志重做(redo),使数据和事务日志保持一致,从而保证了数据库的持久性要求,即对数据库所作的更改,事务一旦提交生效。startup process进程关闭。 (2)守护进程检测到startup process退出后,判断其是否为正确退出,如果为是,数据库启动完成;否则,数据库无法启动,关闭所有数据库进程。
startup process重要步骤分析
重要步骤有7步,具体为:
1、启动进程读取控制文件$PGDATA/global/pg_control
/* 读取控制文件 global/pg_control*/
ReadControlFile();
源码及调用堆栈:
┌──xlog.c──────────────────────────────────┐
│5891 * Read control file and check XLOG status look │
│5892 * │
│5893 * Note: in most control paths, *ControlFile is a │
│5894 * not do ReadControlFile() here, but might as │
│5895 */ │
>│5896 ReadControlFile(); │
│5897 │
│5898 if (ControlFile->state < DB_SHUTDOWNED || │
│5899 ControlFile->state > DB_IN_PRODUCTION || │
│5900 !XRecOffIsValid(ControlFile->checkPoint)) │
│5901 ereport(FATAL, │
│5902 (errmsg("control file cont│
│5903 │
└────────────────────────────────────────┘
multi-thre Thread 0x7ffff In: StartupXLOG Line: 5896 PC: 0x52652d
#0 StartupXLOG () at xlog.c:5896
#1 0x000000000076e394 in StartupProcessMain () at startup.c:215
#2 0x000000000053af6f in AuxiliaryProcessMain (argc=2, argv=0x7fffffffdf70)
at bootstrap.c:418
#3 0x000000000076d557 in StartChildProcess (type=StartupProcess)
at postmaster.c:5203
#4 0x00000000007683b3 in PostmasterMain (argc=1, argv=0xe50fa0)
bootstrap.c:418
#5 0x00000000006c018a in main (argc=1, argv=0xe50fa0) at main.c:228
2、启动进程从xlog日志中得到检查点信息,检查点数据结构包括很多内容,包括当前数据库的时间线ThisTimeLineID值,检查点的数据结构为:
typedef struct CheckPoint
{
XLogRecPtr redo; /* next RecPtr available when we began to
* create CheckPoint (i.e. REDO start point) */
TimeLineID ThisTimeLineID; /* current TLI */
TimeLineID PrevTimeLineID; /* previous TLI, if this record begins a new
* timeline (equals ThisTimeLineID otherwise) */
bool fullPageWrites; /* current full_page_writes */
uint32 nextXidEpoch; /* higher-order bits of nextXid */
TransactionId nextXid; /* next free XID */
Oid nextOid; /* next free OID */
MultiXactId nextMulti; /* next free MultiXactId */
MultiXactOffset nextMultiOffset; /* next free MultiXact offset */
TransactionId oldestXid; /* cluster-wide minimum datfrozenxid */
Oid oldestXidDB; /* database with minimum datfrozenxid */
MultiXactId oldestMulti; /* cluster-wide minimum datminmxid */
Oid oldestMultiDB; /* database with minimum datminmxid */
pg_time_t time; /* time stamp of checkpoint */
TransactionId oldestCommitTsXid; /* oldest Xid with valid commit
* timestamp */
TransactionId newestCommitTsXid; /* newest Xid with valid commit
* timestamp */
TransactionId oldestActiveXid;
} CheckPoint;
得到检查点信息的处理过程为:
/* xlog.c */
void
StartupXLOG(void)
{
...
/* 从控制文件中得到检查点的位置 */
checkPointLoc = ControlFile->checkPoint;
...
/* 从xlog中,根据检查点位置读取检查点记录 */
record = ReadCheckpointRecord(xlogreader, checkPointLoc, 1, true);
...
/* 得到检查点信息 */
memcpy(&checkPoint, XLogRecGetData(xlogreader), sizeof(CheckPoint));
...
}
3、将从检查点得到的信息写入共享内存的相应变量中,包括XLogCtl、ShmemVariableCache等
/* xlog.c */
void
StartupXLOG(void)
{
...
/* 初始化共享内存变量 */
ShmemVariableCache->nextXid = checkPoint.nextXid;
ShmemVariableCache->nextOid = checkPoint.nextOid;
ShmemVariableCache->oidCount = ;
MultiXactSetNextMXact(checkPoint.nextMulti, checkPoint.nextMultiOffset);
SetTransactionIdLimit(checkPoint.oldestXid, checkPoint.oldestXidDB);
SetMultiXactIdLimit(checkPoint.oldestMulti, checkPoint.oldestMultiDB);
SetCommitTsLimit(checkPoint.oldestCommitTsXid,
checkPoint.newestCommitTsXid);
XLogCtl->ckptXidEpoch = checkPoint.nextXidEpoch;
XLogCtl->ckptXid = checkPoint.nextXid;
/* 将ThisTimeLineID保存到共享内存中 */
XLogCtl->ThisTimeLineID = ThisTimeLineID;
ShmemVariableCache->nextXid = checkPoint.nextXid;
ShmemVariableCache->nextOid = checkPoint.nextOid;
...
}
P.S. 全局变量XLogCtl等信息在守护进程postmaster启动时已加入到共享内存中,源码及调用堆栈如下图所示:
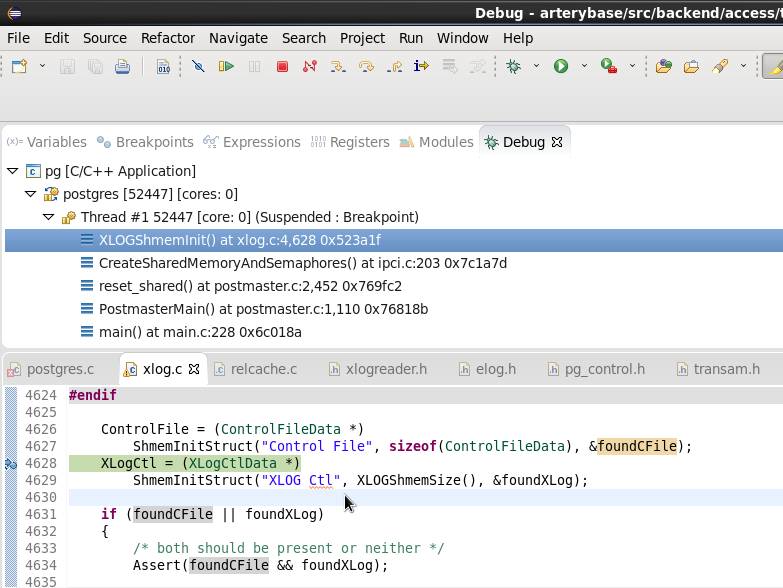
至此,数据库已经恢复到了检查点位置。
4、利用xlog日志重做(redo)检查点以后的事务
制作不正常关闭数据库的场景的方法:psql 登录执行DDL、DML操作,成功后马上用kill -9 命令把postmaster守护进程杀掉。
/*
xlog.c
*/
void startxlog()
{
...
/*
当控制文件的状态不是关机时,需要恢复
*/
if (ControlFile->state != DB_SHUTDOWNED)
InRecovery = true;
...
/* 对xlog中记录了,但是不一定刷回磁盘的事务,根据xlog日志记录的信息进行重做 */
if (InRecovery)
{
//找到需要重做的条记录。如果检查点记录的redo位置小于检查点自身的位置,取值小的开始重做。(这种情况发生在需要在线备份的数据库中)
if (checkPoint.redo < RecPtr)
{
/* 根据检查点中的redo标识,得到条record记录 */
record = ReadRecord(xlogreader, checkPoint.redo, PANIC, false);
}
else
{
/* 读取 CheckPoint记录后面的条记录即可 */
record = ReadRecord(xlogreader, InvalidXLogRecPtr, LOG, false);
}
do
{
/* 调用xlog记录对应的重做函数 */
RmgrTable[record->xl_rmid].rm_redo(xlogreader);
/* 下一条重做函数 */
record = ReadRecord(xlogreader, InvalidXLogRecPtr, LOG, false);
}while (record != NULL);
}
根据ID和函数映射表(类似面向对象的多态调用),调用相应的方法执行某条xlog记录,可以看到不同类型的xlog记录,redo方法各不相同。
PG_RMGR(RM_XLOG_ID, "XLOG", xlog_redo, xlog_desc, xlog_identify, NULL, NULL)
PG_RMGR(RM_XACT_ID, "Transaction", xact_redo, xact_desc, xact_identify, NULL, NULL)
PG_RMGR(RM_SMGR_ID, "Storage", smgr_redo, smgr_desc, smgr_identify, NULL, NULL)
PG_RMGR(RM_CLOG_ID, "CLOG", clog_redo, clog_desc, clog_identify, NULL, NULL)
...
PG_RMGR(RM_HEAP_ID, "Heap", heap_redo, heap_desc, heap_identify, NULL, NULL)
PG_RMGR(RM_BTREE_ID, "Btree", btree_redo, btree_desc, btree_identify, NULL, NULL)
PG_RMGR(RM_HASH_ID, "Hash", hash_redo, hash_desc, hash_identify, NULL, NULL)
PG_RMGR(RM_GIN_ID, "Gin", gin_redo, gin_desc, gin_identify, gin_xlog_startup, gin_xlog_cleanup)
...
5、redo方法的具体执行 以表数据修改涉及的heap_redo为例。由于xlog记录是按照元组粒度记录的,并且记录的是该元组要在哪个位置上变化,因此,即使数据已经存在,也不会出现数据重复的问题(只是覆盖该位置上的数据)。
void
heap_redo(XLogReaderState *record)
{
uint8 info = XLogRecGetInfo(record) & ~XLR_INFO_MASK;
switch (info & XLOG_HEAP_OPMASK)
{
case XLOG_HEAP_INSERT:
heap_xlog_insert(record);
break;
case XLOG_HEAP_DELETE:
heap_xlog_delete(record);
break;
case XLOG_HEAP_UPDATE:
heap_xlog_update(record, false);
break;
case XLOG_HEAP_HOT_UPDATE:
heap_xlog_update(record, true);
break;
case XLOG_HEAP_CONFIRM:
heap_xlog_confirm(record);
break;
case XLOG_HEAP_LOCK:
heap_xlog_lock(record);
break;
case XLOG_HEAP_INPLACE:
heap_xlog_inplace(record);
break;
default:
elog(PANIC, "heap_redo: unknown op code %u", info);
}
}
6、redo后,创建检查点
...
/*进行了恢复 */
if (InRecovery)
{
/* 后台辅助进程bgwrite进程已经启动,由后台进程创建检查点,否则startup 进程创建检查点 */
if (bgwriterLaunched)
{
...
RequestCheckpoint(CHECKPOINT_END_OF_RECOVERY |
CHECKPOINT_IMMEDIATE |
CHECKPOINT_WAIT);
}
else
CreateCheckPoint(CHECKPOINT_END_OF_RECOVERY | CHECKPOINT_IMMEDIATE);
}
...
7、startup process完成使命,结束进程。守护进程捕捉到startup process正常结束,设置数据库为运行状态。
/* startup.c
startup process退出 */
void
StartupProcessMain(void)
{
...
/* 正常退出*/
proc_exit();
}
/*
* postmaster.c
* 捕获到进程退出信号
*/
static void
reaper(SIGNAL_ARGS)
{
//检测子进程的退出
while ((pid = waitpid(-1, &exitstatus, WNOHANG)) > )
{
if (pid == StartupPID)
{
...
//先进行非常复杂的退出状态的判断,判断通过后,将数据库状态设置为运行中
pmState = PM_RUN;
...
/* 输出数据库已经准备接受连接,代表数据库成功启动 */
ereport(LOG,
(errmsg("database system is ready to accept connections")));
...
}
...
}
...
}
总结
通过以上的分析过程,我们可以看到事务日志的重要性:没有事务日志,数据库就无法启动。因此,数据库需要不断的记录事务日志。下一篇我们介绍事务日志膨胀原因及解决方法,希望能够从实战角度解决事务日志膨胀的问题。
来自:https://mp.weixin.qq.com/s/3nuPLEbWvq7PvopWKa9LKQ
