【源码研究】ArteryBase事务日志(1)--事务日志概述
@(arterybase)
源起
前段时间,有同事问我:pg_xlog目录下文件太多,能不能删除,这些文件做什么用的,工作原理是什么。因此,想跟大家介绍一下事务日志,一是让进一步介绍数据库原理,二是希望大家认识到事务日志文件的重要性,避免误操作导致不可挽回的损失。
事务日志的作用和地位
事务日志在关系型数据库中,处于极为重要的地位。
和每次提交都将数据写回磁盘相比,通过事务日志机制,可以提升数据库性能。
当数据库正常关闭后重新启动,通过事务日志,可以将数据库状态恢复到关机前,使数据库看起来就像从没有关闭过一样。
当数据库不正常关闭,如断电、进程crash,通过事务日志,可以保证数据库的持久性要求。
术语
事务日志 事务日志主要包括两部分,xlog(事务操作日志)和clog(事务提交日志)
元组(tuple) 元组是关系数据库中的基本概念,关系是一张表,表中的每行(即数据库中的每条记录)就是一个元组,每列就是一个属性。 在二维表里,元组也称为记录。不只是表,索引的一行也称为一个元组。
xlog记录 对数据库的操作,事务日志管理系统会将数据库的变化整理、封装为一条一条的记录,并写入到xlog文件中。这一条一条的记录,称为xlog记录。
脏页 磁盘的顺序写速率远大于随机写。数据文件是随机写,xlog记录是顺序写,为了在满足持久性要求的基础上,提高数据库整体性能,事务提交后只将xlog记录写回磁盘,而数据文件只作“脏页”标记,以后再写回磁盘。
检查点 检查点是一个事务日志中的时点,在该时点,所有已提交事务对应的数据缓存都将被写入对应的文件中。也就是说,在该检查点,所有已经提交的事务都写入到了磁盘。(但并不意味只有检查点时刻缓存才写回磁盘。)
页/块 磁盘上保存物理记录的单位。数据库系统中,是内存和磁盘交互的小单元,即:即使一个页只修改了一个bit、byte,也需要将整个页写回磁盘。在abase数据库中,默认的页/块大小为8KB。
段 在abase中,有些大小固定的文件,会将固定数量的多个页拼成一个文件作为一个段,可以避免频繁申请只有页大小的文件带来的频繁的和操作系统交互。
postmaster守护进程、后台进程、辅助进程 abase数据库为多进程架构,数据库启动时首先启动的进程为守护进程,其负责创建其他进程、守护及管理其他进程、并监听新的数据库连接请求。 后台进程相对于client来说的,每一个连接到abase库的连接,都对应abase的一个进程,这些进程负责和client交互,称为后台进程。 辅助进程是做一些辅助性、单一功能的工作,如:记录运行日志、记录事务日志、统计信息、检查点信息进程。
事务日志记录过程分析
事务日志的xlog记录了数据库操作的过程,clog记录了事务运行的结果。只要是能引起数据库内数据改变的操作,都记录事务日志,包括:DDL、DML(不含select)、DCL语句等。 下面以一个update语句为例,介绍事务日志的记录过程。 1、首先建表,插入5条数据。
create table mytable(col1 int primary key, col2 text);
create index idx_mytable_col2 on mytable(col2);
insert into mytable values(1, 'test');
insert into mytable values(2, 'test');
insert into mytable values(3, '3');
insert into mytable values(4, '4');
insert into mytable values(5, '5');
2、启动程序调试,将GDB调试工具连接到psql对应的后台进程上。具体方法参见:【源码研究】ABase子进程调试方法总结
3、更新col2值为test的所有的行,将值改为test1,涉及两条数据的更新。
update mytable set col2 ='test1' where col2 = 'test';
4、跟踪调试进程进入事务日志执行环节。
提示:sql语句需要经历查询分析(词法分析、语法分析)、查询优化、查询执行等步骤方可执行。本文仅介绍”查询执行”步骤中涉及事务日志的内容。
断点设置到backend/executor/execMain.c,第337行,进入查询执行模块的执行环节:
if (!ScanDirectionIsNoMovement(direction))
ExecutePlan(estate,
queryDesc->planstate,
operation,
sendTuples,
count,
direction,
dest);
经过跟踪源码发现,在 backend/executor/nodeModifyTable.c的源码,涉及了表内数据、触发器、索引等元素的修改,而各元素的修改都需要记录事务日志:
/* BEFORE ROW UPDATE 触发器*/
slot = ExecBRUpdateTriggers(estate, epqstate, resultRelInfo,
tupleid, oldtuple, slot);
/* INSTEAD OF ROW UPDATE 触发器*/
slot = ExecIRUpdateTriggers(estate, resultRelInfo,
oldtuple, slot);
/* 表内元组更新 */
result = heap_update(resultRelationDesc, tupleid, tuple,
estate->es_output_cid,
estate->es_crosscheck_snapshot,
true /* wait for commit */ ,
&hufd, &lockmode);
/* 更新索引 */
recheckIndexes = ExecInsertIndexTuples(slot, &(tuple->t_self),
estate, false, NULL, NIL);
/* AFTER ROW UPDATE 触发器 */
ExecARUpdateTriggers(estate, resultRelInfo, tupleid, oldtuple, tuple,
recheckIndexes);
涉及事务日志管理的源码为 backend/access/transam/xloginsert.c。 在该文件的xloginsert函数加断点,调用堆栈如下:

从函数名可以看出,执行表内元组更新时,需要记录xlog日志。 我们根据调用堆栈查找有用的信息:
每个元组的更新都需要经历以上的调用过程,说明xlog日志对于更新多条数据的sql语句,不是记录sql语句,而是记录每个元组的变化。
for (;;)
{
......
/* 得到某元组 */
tupleid = (ItemPointer) DatumGetPointer(datum);
......
/* 更新某元组 */
slot = ExecUpdate(tupleid, oldtuple, slot, planSlot,
&node->mt_epqstate, estate, node->canSetTag);
ExecUpdate函数会调用xloginsert函数,组装相应的xlog日志。
数据buffer只需标记为脏页即可,无需立即写回磁盘。
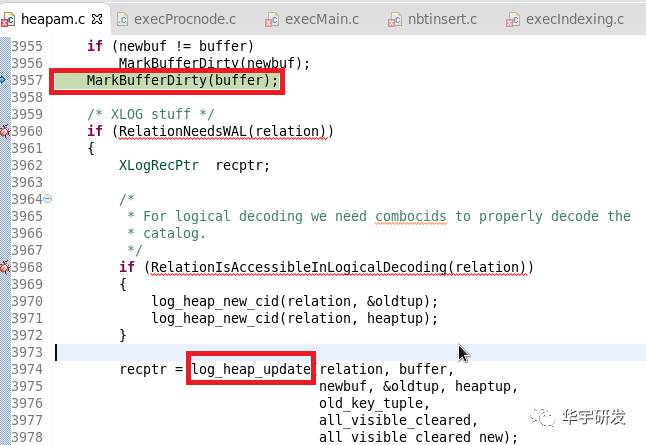
update语句执行完所有的执行动作后,会启动提交事务的动作。
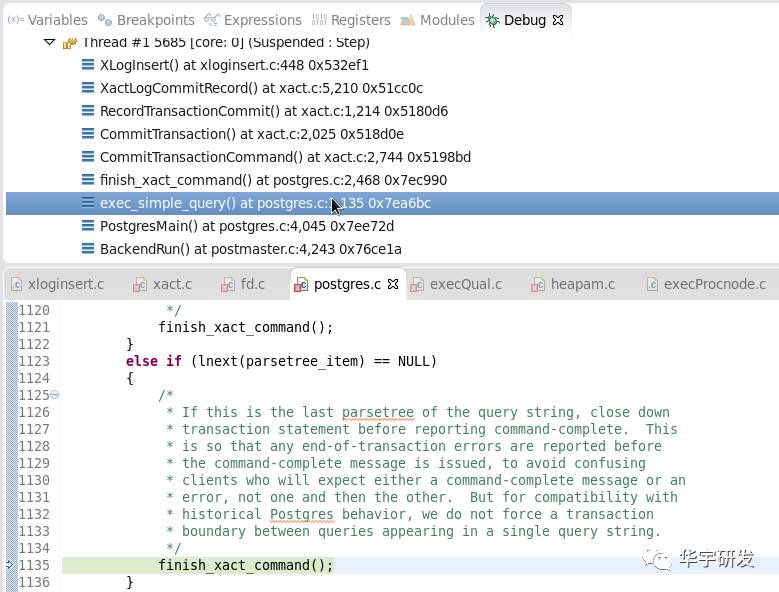
commit事务时,会将xlog日志调用
xlogflush->pg_fdatasync将xlog数据立即写回磁盘。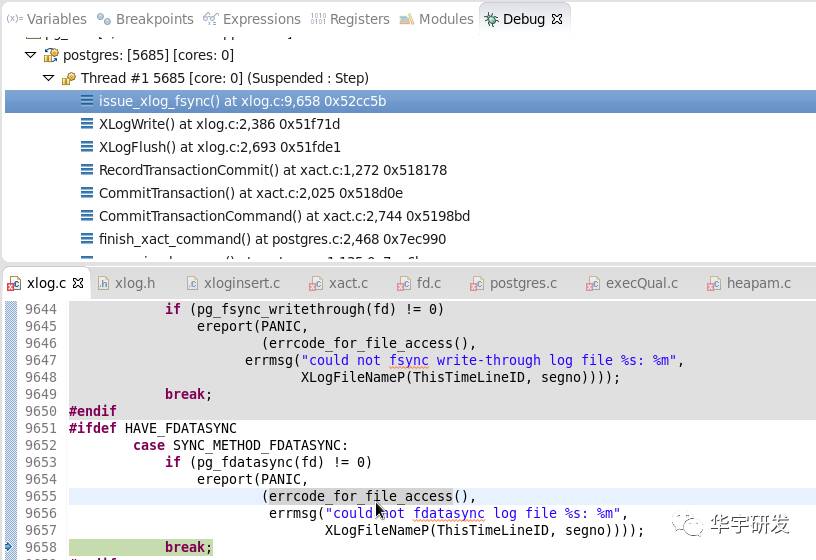
关于事务操作日志文件
事务操作日志提交后写回磁盘,那么,事务操作日志文件在磁盘上是如何组织的?
从文件夹中查看
进入$PGDATA,有pg_xlog文件夹,该文件夹保存的就是事务操作日志信息。进入该文件夹,发现有多个文件名长度为24位,大小为16MB的文件。
从源码层面解读
xlog文件命名处理逻辑
当无事务操作日志或某个事务操作日志文件已满,无法继续保存后续的事务操作日志时,就会申请新的文件,并给新文件命名,命名方法如下:
/* xlog.c
static void
XLogWrite(XLogwrtRqst WriteRqst, bool flexible)
line 2210-2225
说明:当前的xlog文件大小记录不下该事务的所有日志 */
if (!XLByteInPrevSeg(LogwrtResult.Write, openLogSegNo))
{
...
/* 创建新文件 */
openLogFile = XLogFileInit(openLogSegNo, &use_existent, true);
...
}
xlogwrite方法调用XLogFileInit方法,在该方法中生成新的xlog文件的文件名,即:在pg_xlog目录下,24位的文件名,如:00000001000001990000001F,命名规则为8位时间线 + 8位段号整除16M + 8位段号模16M,源码如下:
/* xlog.c
xlog文件初始化 */
int
XLogFileInit(XLogSegNo logsegno, bool *use_existent, bool use_lock)
{
...
/* XLogFilePath方法为宏定义,利用ThisTimeLineID(时间线)、logsegno(段号),8位时间线 + 8位段号整除16M + 8位段号模16M,如下:
snprintf(path, 1024, "pg_xlog" "/%08X%08X%08X", ThisTimeLineID, \
(uint32) ((logsegno) / (((uint64) 0x100000000) / (16 * 1024 * 1024))), \
(uint32) ((logsegno) % (((uint64) 0x100000000) / (16 * 1024 * 1024))))
*/
XLogFilePath(path, ThisTimeLineID, logsegno);
...
}
生成文件名各参数值由来
上文中的logSegNo的由来:根据事务日志的位置endptr计算而来。计算方法为:
static void
PreallocXlogFiles(XLogRecPtr endptr)
{
...
/* XLByteToPrevSeg宏定义根据endptr整除16M得到logSegNo,然后将logSegNo传入XLogFileInit,来初始化xlog文件。
_logSegNo = ((endptr) - 1) / ((uint32) (16 * 1024 * 1024)); */
XLByteToPrevSeg(endptr, _logSegNo);
lf = XLogFileInit(_logSegNo, &use_existent, true);
...
}
举个例子,假设当前xlog文件为000000010000000000000000,当endptr大于16 * 1024 * 1024,说明该当前xlog文件放不下所有内容,此时,计算endptr / ((uint32) (16 * 1024 * 1024)) 值将为1。将_logSegNo =1传入XLogFileInit方法,得到xlog文件名的第二部分为00000000,第三部分为00000001。
生成文件名各参数值由来--ThisTimeLineID
xlog文件的部分为时间线,该值取自全局变量ThisTimeLineID。该值在数据库向外提供服务前,已经在共享内存中初始化完成(如果未进行过数据恢复,该值为1)。当创建新的连接进程时,从共享内存中得到ThisTimeLineID值。
共享内存中ThisTimeLineID值的获得 该值在数据库启动过程中完成的,具体可见《【源码研究】ArteryBase事务日志(2)--从关机中恢复》。 ThisTimeLineID的值随着数据库每一次从归档中恢复(不是从关机中恢复)而递增。
xlog.c line. 7042
if (ArchiveRecoveryRequested)
ThisTimeLineID = findNewestTimeLine(recoveryTargetTLI) + 1;
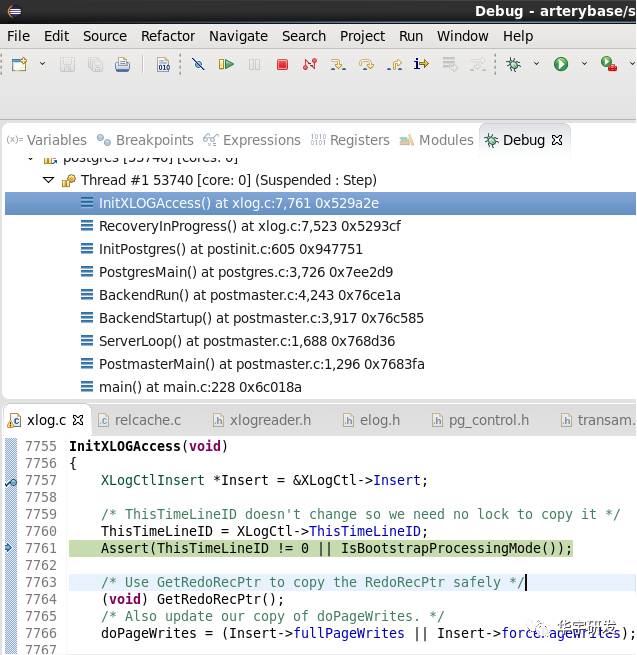
后台进程ThisTimeLineID值的获得 当创建新的连接,新进程初始化过程中设置ThisTimeLineID值。
void
InitXLOGAccess(void)
{
...
/* 获得ThisTimeLineID */
ThisTimeLineID = XLogCtl->ThisTimeLineID;
调用堆栈如下:
关于事务提交日志文件
从磁盘文件来看
事务提交日志在$PGDATA/pg_clog目录下,以4位流水号0000/0001等命名。
[thunisoft@master pg_clog]$ cd $PGDATA/pg_clog
[thunisoft@master pg_clog]$ ll
总用量 1220
-rwx------ 1 thunisoft thunisoft 262144 6月 7 02:36 0000
-rw------- 1 thunisoft thunisoft 262144 6月 24 02:35 0001
-rw------- 1 thunisoft thunisoft 262144 7月 7 07:33 0002
-rw------- 1 thunisoft thunisoft 262144 8月 15 07:30 0003
-rw------- 1 thunisoft thunisoft 188416 10月 12 05:43 0004
从源码层面解读
文件命名规则
通过对检查点进程进行跟踪来查看文件命名规则:进行检查点检查时将事务提交日志写回到磁盘,如果当前的事务日志提交文件无法容纳更多的提交记录时,会创建新的clog文件,通过该过程来查看文件命名方式。
SlruFileName函数为宏定义,定义内容为:
#define SlruFileName(ctl, path, seg) \
snprintf(path, MAXPGPATH, "%s/%04X", (ctl)->Dir, seg)
文件名为seg变量以16进制格式输出作为文件名。
#define SLRU_PAGES_PER_SEGMENT 32
pageno = shared->page_number[slotno]
int segno = pageno / SLRU_PAGES_PER_SEGMENT;
文件大小
前文segno(段号)/32(每段大的页数)。 abase以8KB为一个block(页、块),32*8=256KB,因此每个clog(事务提交日志)文件大256KB,小8KB。
一个clog文件记录的大事务数
这个问题可以转为一个事务提交情况需要的记录空间。 查看源码发现事务日志中需要记录的信息只有4种,使用2个bit即可。这样算来,1个256KB的clog文件多可以存放25610244=1百万个事务。
#define TRANSACTION_STATUS_IN_PROGRESS 0x00
#define TRANSACTION_STATUS_COMMITTED 0x01
#define TRANSACTION_STATUS_ABORTED 0x02
#define TRANSACTION_STATUS_SUB_COMMITTED 0x03
事务记录日志与具体的某事务的对应关系
因为事务xid是序列递增的,因此,可以将事务xid和clog中的文件位置对应起来:xlog的值换算为clog文件名(段号)-页号-页内偏移量,关键代码如下:
#define CLOG_BITS_PER_XACT 2
#define CLOG_XACTS_PER_BYTE 4
#define BLCKSZ 8192
#define CLOG_XACTS_PER_PAGE (BLCKSZ * CLOG_XACTS_PER_BYTE)
#define CLOG_XACT_BITMASK ((1 << CLOG_BITS_PER_XACT) - 1)
#define TransactionIdToPage(xid) ((xid) / (TransactionId) CLOG_XACTS_PER_PAGE)
#define TransactionIdToPgIndex(xid) ((xid) % (TransactionId) CLOG_XACTS_PER_PAGE)
#define TransactionIdToByte(xid) (TransactionIdToPgIndex(xid) / CLOG_XACTS_PER_BYTE)
#define TransactionIdToBIndex(xid) ((xid) % (TransactionId) CLOG_XACTS_PER_BYTE)
/* xid / (8192 * 4) */
int pageno = TransactionIdToPage(subxids[]);
/* 换算逻辑,slotno由页号计算而来,slotno和页号相当于磁盘页和内存的对应关系。 */
static void
TransactionIdSetStatusBit(TransactionId xid, XidStatus status, XLogRecPtr lsn, int slotno)
{
//页内字节偏移量
int byteno = TransactionIdToByte(xid);
//字节内位偏移量
int bshift = TransactionIdToBIndex(xid) * CLOG_BITS_PER_XACT;
char *byteptr;
char byteval;
char curval;
//找到共享内存中的对应字节
byteptr = ClogCtl->shared->page_buffer[slotno] + byteno;
//将状态值设置到对应的位
byteval = *byteptr;
byteval &= ~(((1 << CLOG_BITS_PER_XACT) - 1) << bshift);
byteval |= (status << bshift);
*byteptr = byteval;
来自:https://mp.weixin.qq.com/s/Rgappg0NdnR-Jdz5YwXBHw
