人工智能
近些年来,人工智能在各类媒体大肆宣传报道下又大火了起来。以大众的眼光来看,人工智能看似已经无所不能了,自动驾驶、智能机器人、人脸识别、语音翻译以及下围棋玩游戏等等,这些都不在话下。
正所谓外行看热闹内行看门道,实际上,目前的人工智能所用到的技术主要是一些机器学习算法,属于弱人工智能。虽然它能实现很多神奇的应用,但它的局限性也很大,只有在清楚了解人工智能的机制原理后才不至于被媒体夸大的报道牵着走。这篇文章我们准备深入理解人工智能如何自己玩游戏。
机器学习
总的来说,机器学习是人工智能的一个分支,是实现人工智能的一种途径。机器学习理论主要研究的是一些能让机器自动学习的算法,它能从数据样本中自动学习到规律,然后通过学习到的规律对未知数据进行预测。
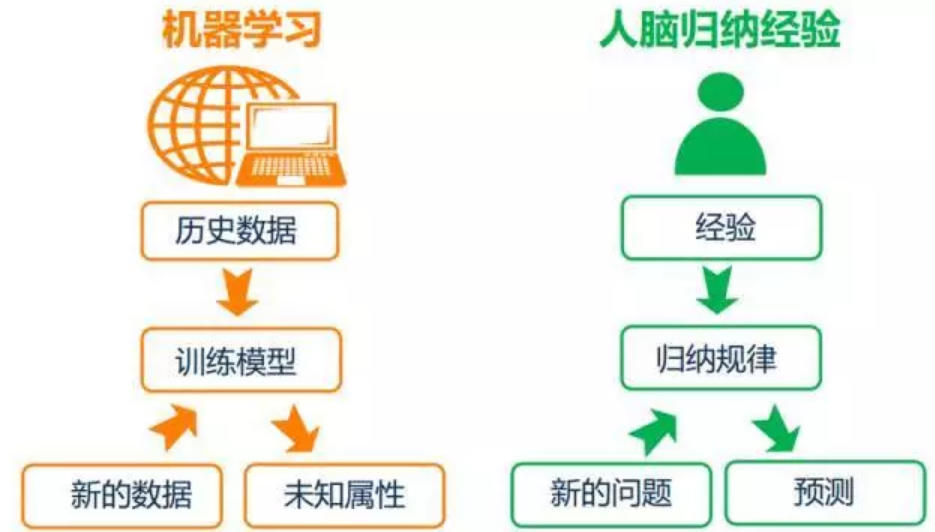
机器学习大致可以分为四类:
- 监督学习,监督学习是利用标记了的样本进行学习。
- 无监督学习,无监督学习则是使用未标记的样本进行学习。
- 半监督学习,数据样本中只有少量带标记的样本,多数样本都未标记,利用这些样本进行学习。
- 强化学习,是一种很不同的学习方式,它没有规则的训练样本和标签,主要通过奖励和惩罚达到学习的目的。
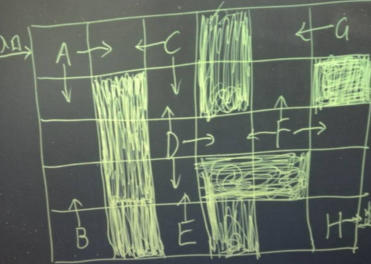
一个小游戏
有个小游戏,如下图,进入入口后初始位置为A,阴影部分表示大炕,踩进去就没命了得重来,操作可以上下左右,终走到H位置就算胜利。假如不知道哪些是大坑的情况下,让你来玩这个游戏,你会怎么玩?你应该有很多方法来完成这个游戏的。但如果是机器呢?怎样才能让机器自己学会玩这个游戏呢?答案就是强化学习!
强化学习
《强大脑》曾经有个挑战项目叫蜂巢迷宫,挑战者不断尝试不断试错。强化学习做法也类似,它主要包含三个概念:状态、动作和回报。同样是以迷宫为例,智能体所在的位置即是状态,从某个位置向某方向走一步则为动作,比如可以向左向右或向上向下,每走一步会产生回报,比如撞到墙就是负回报,好的动作则会带来正回报。而且不仅要关注当前的回报,还要关注长期的回报,通过不断试错学习到一个长期回报的动作序列。
智能体从环境中学习行为策略,也就是如何在环境中采取一些列行为,才能使得奖励信号函数的值大,即获得的累积回报大。强化学习通过环境提供的信号对产生的动作的好坏做一种评价,它必须要靠自身经历进行学习。在习得模型后智能体就知道在什么状态下该采取什么行为,学习从环境状态到动作的映射,该映射称为策略。
如下图,一个智能体通过与环境交互并以一定的策略改变环境,智能体可以从环境中得到状态,然后执行一个动作,接着得到一个即时回报,后转移到下一个状态。整个过程就可以总结为根据当前观察状态值找到一个优的动作使得回报多。
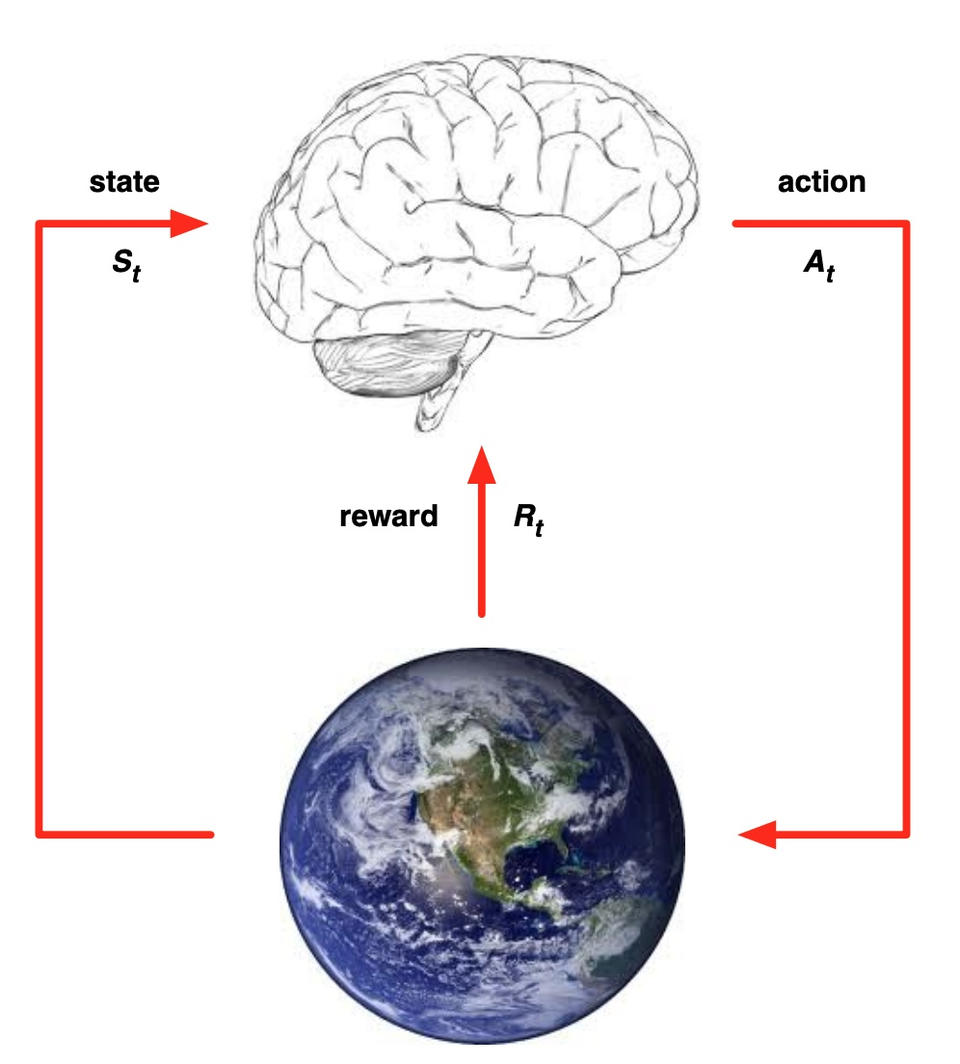
马尔科夫决策过程
在理解强化学习之前,我们先了解我们要解决什么样的问题。其实强化学习过程就是优化马尔科夫决策过程,它由一个数学模型组成,该模型在代理的控制下对随机结果进行决策。
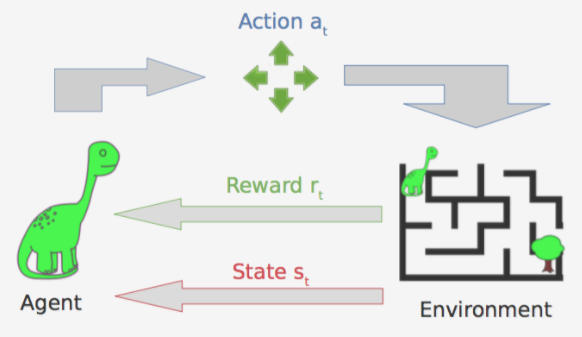
代理可以执行某些动作,例如上下左右移动,这些动作可能会得到一个回报,回报可以是正数也可以是负数,它会导致总分数变动。同时动作可以改变环境并导致一个新的状态,然后代理可以执行另外一个动作。状态、动作和回报的集合、转换规则等,构成了马尔科夫决策过程。
决策相关元素
在整个马尔科夫决策过程中,涉及到以下五个重要的元素。
- 状态集合,所有可能状态。
- 动作集合,所有动作,它能使某个状态转换为另一状态。
- 状态转移概率,特定的状态下执行不同动作的概率分布。
- 回报函数,从一个状态到另一个状态所得到的回报。
- 折扣因子,用于决定未来回报的重要性。
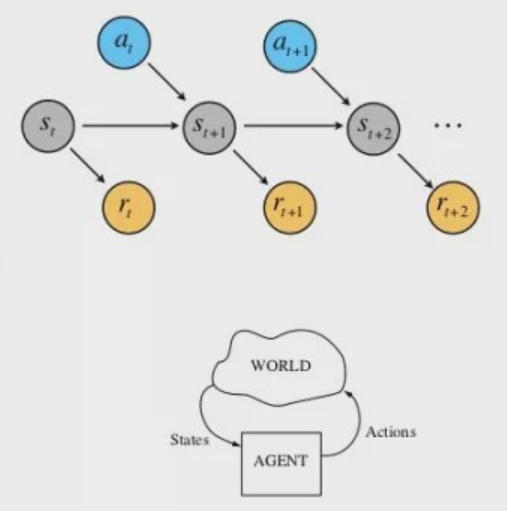
强化学习训练主要就是计算各个状态下不同动作的回报,并非瞬间完成的,而是要经过大量尝试。下一个状态取决于当前状态和动作,并且状态不依赖于先前的状态,没有记忆,符合马尔可夫性。
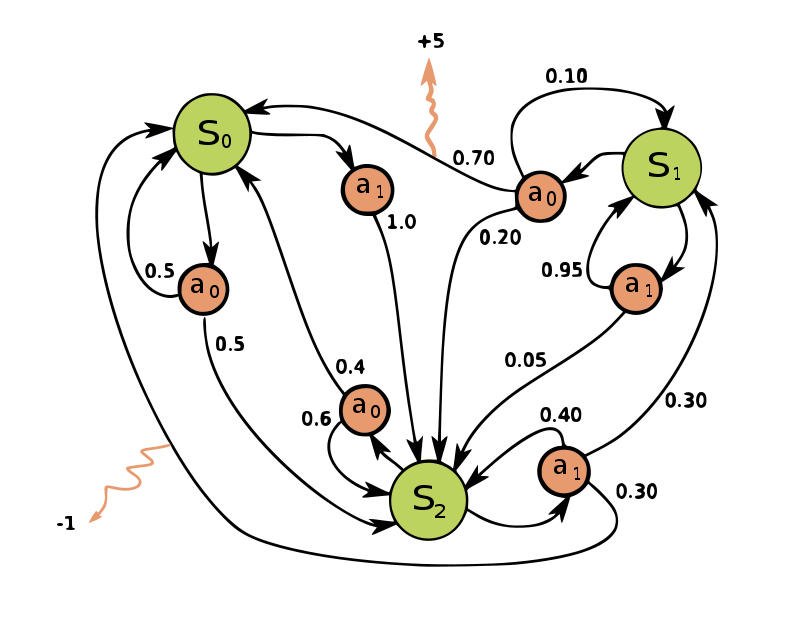
强化学习是智能体与环境之间的迭代交互,需要考虑几点:
- 处于某种状态,决策者将在该状态下选择一个动作;
- 能随机进入一个新状态并给决策者相应的回报作为响应;
- 状态转移函数选择的动作将影响新状态的选择;
强化学习的特点
- 它是试错学习,因为它没有像监督学习一样的直接指导信息,所以它只能不断去跟环境交互不断试错来获取佳策略。
- 它的回报具有延迟性,因为它往往只能在后一个状态才能给出指导信息,这个问题也让回报的分配更加困难,即在得到正回报或负回报后怎么分配给前面的状态。
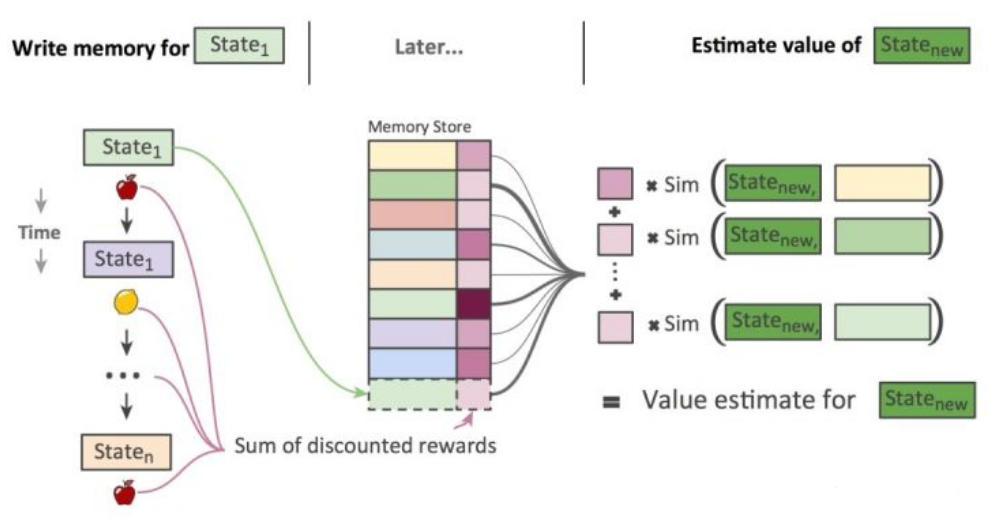
学习模型
经过不断试错后,终通过强化学习习得一个模型,该模型能够学习到各个状态下各个动作的质量,有了这个就能完成这个小游戏了。
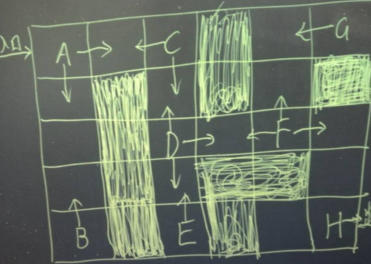
学习过程的大致思路为:入口进去,A点有两个方向,刚开始没有回报,随机选一个方向。如果为下,则一直往下,到达B后发现没路,得到一个负100回报,结束。下次又来到B上面一格,更新自己的回报。不断更新到后在A处时,往下的回报为-50,那就选择往右。到达D后同样先随机,然后将格子的回报值更新好。因为要看长远点,所以需要看未来n个时刻的回报期望,当然越远的回报值会打折越多。n个时刻综合起来D向右的回报大点,于是往右,到达F。去G的路上的格子经过迭代也都回报值变小,到H的回报值都较大,直到出口。
总结
所以,人工智能玩游戏的机制原理就是强化学习,机器会通过不断尝试不断试错去总结一个拥有长期回报的策略,通过这个策略就能完成游戏。其实现在在很多领域和应用都是通过强化学习来实现的,比如飞行器的飞行控制、控制机器人的行走、学习怎么玩游戏、学习怎么理财投资等等。

github
-------------推荐阅读------------
我的开源项目汇总(机器&深度学习、NLP、网络IO、AIML、mysql协议、chatbot)
跟我交流,向我提问:

欢迎关注:人工智能、读书与感想、聊聊数学、分布式、机器学习、深度学习、自然语言处理、算法与数据结构、Java深度、Tomcat内核等相关文章

