上海旬思科技有限公司专注于工业大数据平台实时数据采集、设备远程监测及预测性维护、机器协同互联、远程实时控制等多个工业领域。背靠上海临港新片区针对工业互联网、智能制造领域的产业扶持,打造国内工业互联网行业先进产品和技术的先锋企业。
旬思工业互联平台(TServer)是面向工业企业建立大数据平台的产品解决方案,提供数据采集、解析、展示、报警、统计、查询、分析以及远程运维通道管理等功能,内置实时数据库引擎,融合传统SCADA软件和工业互联网架构技术,适用于工业互联网行业的赋能创新。
项目背景和技术难点
湖北某特钢公司的电力能源介质的计量,是通过TBox工控网关采集多功能电表来实现的。按照《关于湖北电网2020-2022年输配电价和销售电价有关事项的通知》,需要完善并实现“峰谷平尖”电能量费率计量和能源报表。TBox工控网关基于前期项目实施和实际应用需求提供了完整的技术方案,包含从电表采集电能数据并写入TDengine时序数据库,再经过ETL工具处理后转存到Oracle数据库,从而满足企业一期电能量数据报表对实时数据采集和存储的要求。
本项目主要接入的能源介质有:电力、焦炉煤气、高炉煤气、转炉煤气、压缩空气、天然气、氧气、氮气、氩气、蒸汽、净水、软水、除盐水和生活水等,项目一期首先要求采集电能量数据,其中需要接入的电表多达874块,电力能源数据已超20000点,每天产生的数据量在2800万条以上;项目二期如果再接入非电数据,还会有几千个流量设备的接入,整个系统数据点也将远超50000点,每天产生的数据量预估在1亿条左右。在设备通讯数据采集方面,我们一直处于行业领先水平;但对于大数据量的存储,选择什么样的数据库,是否也能满足二期大数据量的接入能力,给我们带来了极大的挑战。

本项目特点:
开发周期短:用户要求系统一个月上线;
稳定性要求高:工业应用的特点,系统无人化运维; 单机性能要求:在用户提供的一台16核32G内存服务器上,需要完成所有工作,包含数据上传、处理和转存等服务; 系统兼容性:同时要考虑满足二期50000+点的数据接入能力。
选择 TDengine的理由
为了解决大数据量带来的数据存储难点,以及满足系统性能要求,我们在数据库选型方面,做了充分的调研:
MySQL:传统关系型数据库,开源免费,安装使用简单,维护成本低,很少宕机,支持多操作系统。
InfluxDB:时序数据库,可以高性能地查询与存储时序型数据,被广泛应用于存储系统的监控数据、IoT行业的实时数据等场景;集群功能没有开源。
TDengine:国产时序数据库,国产开源,针对工业互联网场景做了大量优化,同时还支持滑动窗口,流式计算。开源了集群版本。
分析项目需求不难发现,时序数据库更适合此类工业大数据应用。而在同等数据集和硬件环境下,涛思官方的测试结果显示,TDengine的写入速度远高于InfluxDB。同时TDengine支持多种数据接口,包含C/C++,Java,Python,Go和RESTful等。由于我们数据解析部分使用Go语言编写,所以终采用了Go Connector接口方式进行时序库读写。
应用 TDengine 的场景、业务架构
本项目场景的能源管理类数据除时序特征外,还具有其他多种明显特征:
数据结构简单,写多读少;
数据极少需要更新或删除;
流量平稳,根据设备数量和采集频次,可预测;
数据保留期限为10年;
数据的查询分析是基于时间段和空间区域;
除存储、查询操作外,还需要各种统计和实时计算操作; 数据量巨大,一天采集的数据可能超过1亿条。
根据上述数据特征,结合TDengine给的建议,以及本项目数据特点和使用场景,我们做了以下优化设计:
包含模拟量,数字量,报警,系统日志等类型数据,同类型使用一个超级表集合;
单个数据点对应单个表存储;
批量数据写入,大化SQL字符串拼接,提高数据写入效率;
Go多协程并发写入,进一步提高写入效率。
库结构设计:保留update功能,方便后期对坏数据做二次处理。
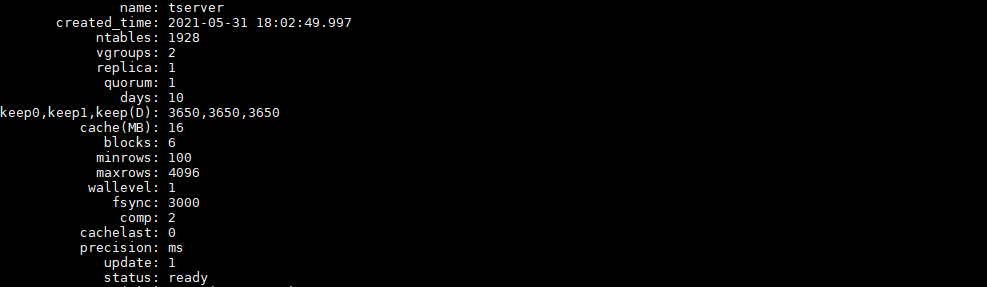
普通表一览:基于超级表自动生产普通点表。
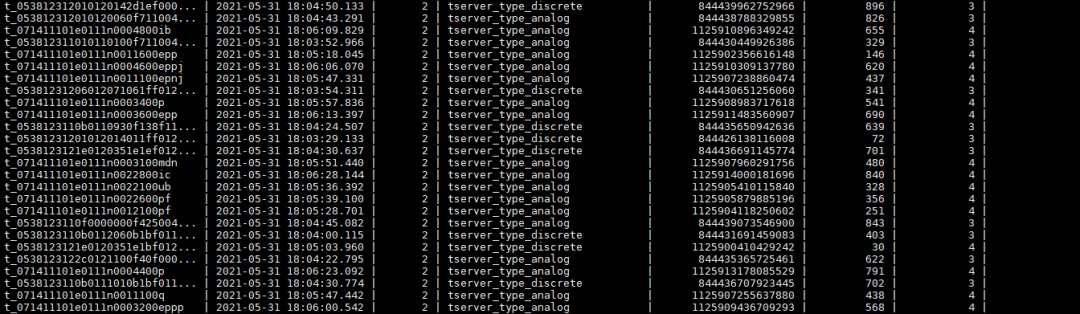
电力能源数据一览:数据上传平台后解析并显示。
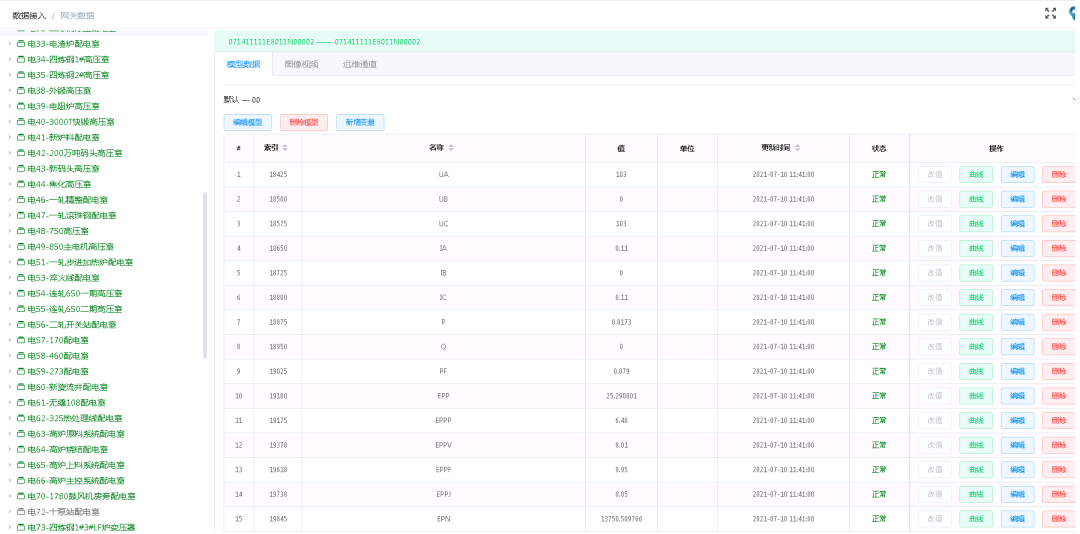
电力能源数据滑动查询:根据查询时间长度自适应选择滑动窗口大小。

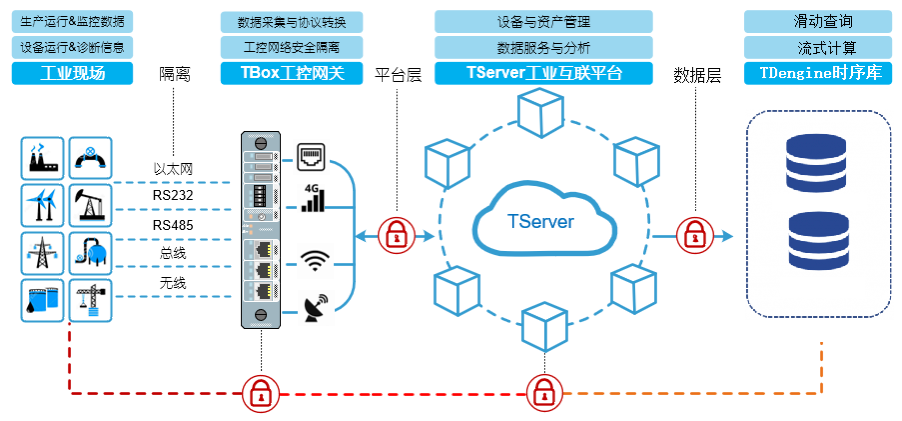
下图是本项目完整业务架构图,TBox工控网关南向采集现场电力能源数据,北向实时上传数据到TServer工业互联平台;TServer接收到数据后,通过解析识别,分类组包高并发写入TDengine时序库。
前期调研,TDengine优势再体现
在这里我们首先提两个工业实时数据库。一个是Wonderware的高性能实时关系型数据库InSQL,它集成了微软公司的MS SQL Server并对其进行了扩展,具有高效数据压缩和数据存储等实时数据库功能,它比常规关系型数据库的数据采集速度、存储量高数百倍。InSQL扩展了SQL语句,使其具有了时间特性。
InSQL的运行性能与所用的硬件系统有关,单机可以在1秒内完成6万个点的取数或存储(峰值)。这个速度与数据存贮方式无关,采用的周期性存储(以固定的多少毫秒存储一次)或增量存储(数据的变化超过设定百分比时存一次)。InSQL可以每秒存储3万点(均值)或每100毫秒存2000点数据。要提高数据采集速度,主要障碍是大多数数据源(PLC或DCS)提供数据的速度赶不上InSQL取数的速度。InSQL的小分辨率为3.3毫秒。
另一个是OSI的PI数据库,每个PI的高端产品服务器中可以处理每秒钟15万点的数据。在客户端软件ProcessBook上,可以在秒级时间内从2年或3年历史中取到1000点数据。在OSI的WEB网站上有一个电子表格可以帮助你详细计算所需的配置。
TDengine是涛思数据面对高速增长的物联网大数据市场和技术挑战推出的创新性的大数据处理产品,在时序空间大数据处理上,有着自己独到的优势。TDengine单核每秒能处理至少2万次请求,插入数百万个数据点,读出一千万以上数据点,比现有通用数据库快十倍以上,也远远超出了InSQL、PI这两个工业实时数据库的读写能力。
使用TDengine过程中,几乎没有遇到什么大问题。一些小bug也可以通过版本升级解决。这里要对涛思数据的物联网大数据微信交流群,以及非常热心的涛思工程师陈玉同学,在我们一期系统上线后遇到的配置错误导致服务启动失败的积极快速响应表示感谢。
未来规划
本项目一期电力能源数据的采集早已上线运行3个多月,用户也非常认可这套系统。我们在给用户培训过程中,也强力推荐了国产的TDengine数据库,相信未来这些用户也将成为TDengine的忠实粉丝。
我们正在准备项目二期非电能数据的采集,这次变量会成倍增长,同时也会面临新的挑战,比如分布式存储,热冗余备份等作为大数据量接入和数据安全备份的必要保障。经过一期成功经验的积累,我们相信二期新系统也会很顺利的交付运行。后续在石油管道,冶金智能制造等更多场景中,也在尝试使用TDengine时序库作为我们的存储方案。
对于TDengine,我们也有一些期待升级改进的地方:
推出Windows平台的Server端; 更多的SQL语句支持,支持更丰富的复杂计算; 更稳定运行,异常不重启服务。
来源 https://www.modb.pro/db/168864
