场景介绍
中科惠软承建的A城市“智慧环保”物联网应用项目需要采集各类感知设备产生的监测数据和监控设备各种运行状态,监测数据包括空气质量、水环境质量、渣土场和渣土车监测、施工工地扬尘监测等实时监测数据。并且需要把每时每刻监控的数据记录存储下来,用于生态环境大数据分析和城市环境质量预测预报分析计算。
项目每天采集各类监测数据2亿余条,如果使用公司原架构,可以勉强将每天的数据存储下来,但如果需要快速查询“某天下午两点,A路段有多少辆渣土车通过”这样条件的多纬度分组聚合查询,那么采用传统的数据库就无法实现快速查询需求。
考虑到各类感知监测设备会时刻产生大量秒级和分钟级监测数据存储和实时计算,关于海量时间序列数据存储,经过多个产品之间的性能和稳定性方面对比,终,采用了TDengine产品实现海量的生态环境监测数据进行实时存储、计算和大数据分析。
时序数据库选型
现今智慧环保领域使用海量的监测数据进行大数据分析,发现深层次的环境问题,从而帮助污染源企业节能减排,增加效益。我公司选择了InfluxDB和TDengine进行对比。
由于InfluxDB和TDengine集群版本都需要收费,终选择了单实例进行对比测试,开始准备两台配置参数一致的测试服务器进行多方面的应用场景、稳定性以及性能测试。
以上性能测试结果为测试环境结果,若与官方测试数据有偏差,敬请谅解。上述性能测试结果仅供参考。
InfluxDB需要借助kafka、MQTT等消息队列中间件实现批量写入,从而提升数据的写入性能。综合智能环保项目多方面应用场景测试,结合我公司一段时间的稳定性和性能方面测试,TDengine时序数据库相对比较适合我公司智慧环保领域产品发展战略,也考虑到后期智慧环保领域系统国产化需要,终选型了TDengine产品。
TDengine业务应用
数据流设计
整个数据采集延续了我公司之前的架构设计,从外部系统或终端监测设备采集数据沿用了我公司自研WisoftETL中间件产品。WisoftETL主要负责接收数据包和主动请求获取数据包两种方式,接收到原始数据后,根据定义的数据融合规则进行数据整合,将数据进行分类存储至数据中心各类数据。在存储时间序列数据时,充分利用TDengine中Avg、Count、Max、Min等聚合函数对一个或多个数据流进行实时聚合、统计以及计算等,并将计算出的衍生数据保存进 Tdengine新的数据表中,以便后续的操作。
部署及应用
生产环境中我们选择了三台服务进行分布式部署,如官方所说一致,TDengine部署特别的简单,在安装过程中,会提示当前安装的节点是否要加入已经存在的集群节点,输入集群节点IP地址即可加入该集群节点。
项目初期规划了2000多个空气监测站点、500个移动监测点以及4000多辆渣土车,充分利用TDengine的Stable多表聚合为每类监测设备创建超级表,为每个设备创建了子表。
--创建超级表
create table t_realtime_gps_partcar_his (gpstimestamp timestamp, devphone nchar(20), platenum nchar(20), longitude nchar(20), latitude nchar(20), senddatetime timestamp, carspeed nchar(20), isonline nchar(20), ) tags (tag1 nchar(20))
--创建子表
create table t_realtime_gps_40155712660 using t_realtime_gps_partcar_his tags ('40155712660');create table t_realtime_gps_40155712661 using t_realtime_gps_partcar_his tags ('40155712661');
为了满足少部分监测设备会定期的增加或者更换设备,由于部分设备会存在定期更换或增加监测设备数据,我们在架构设计时还引用了TDengine根据数据自动创建子表。
--超级表写入数据时,如果子表不存在,则自动根据超级表自动创建子表
insert into zyml.t_realtime_gps_40155712669 using zyml.t_realtime_gps_partcar_his tags ('40155712669') values (gpstimestamp, devphone, platenum, longitude, latitude, senddatetime, carspeed , isonline) ('2019-07-25 04:55:05.457752', '40155712669', '23477', '117.04634', '36.72716', '2019-07-25 04:54:57.0', '0', '0');数据流式计算
1. 数据资产实时分析
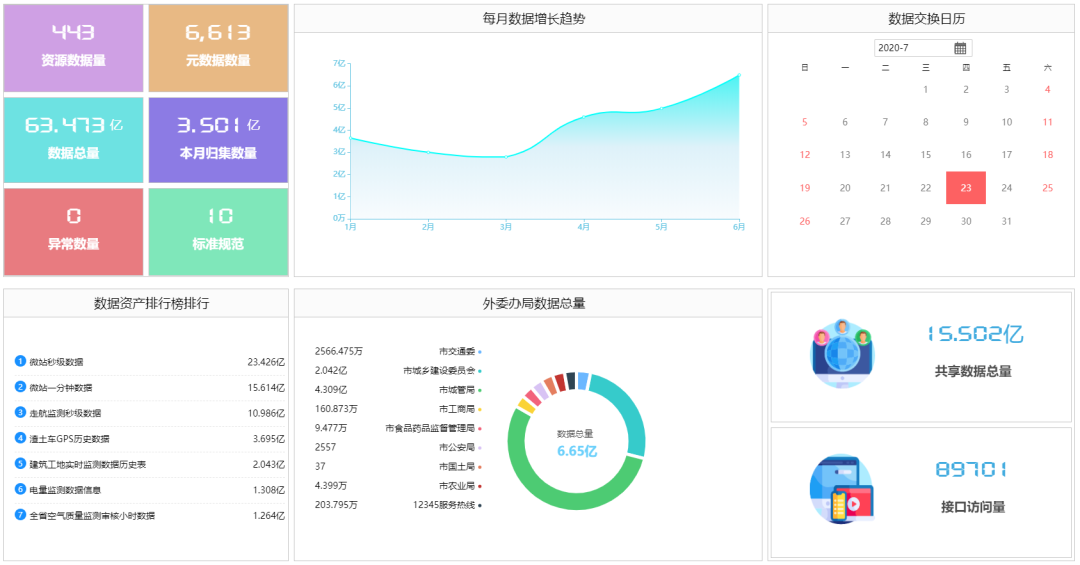
2. 实时报警流式计算
通过采集污染源企业废气、废水和能耗监测数据,对每分钟的监测数据进行实时计算每个污染物每个小时的平均值、大值、小值、排放量累计值。我们主要使用TDengine定义自动滑动计算实现小时监测数据计算,并将实时计算结果数据存储新的pmcaemhourdata表中,可供其他业务平台重复利用。
create table pmcaemhourdata as select avg (codcraudit),max (codcraudit),min (codcraudit),sum(codcrpfl),avg(codcrstand) from pmcaemminuteata interval (60m) sliding(60m)
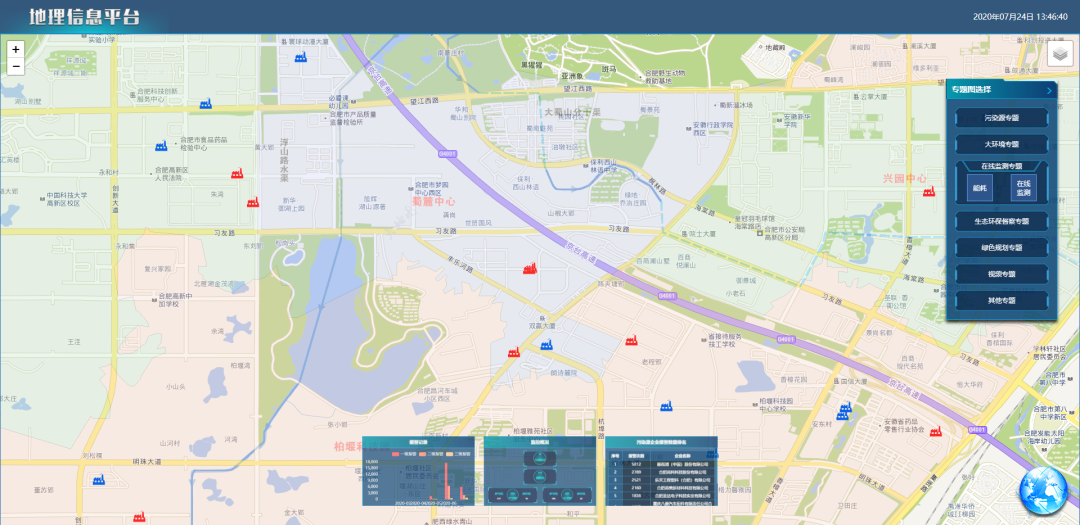
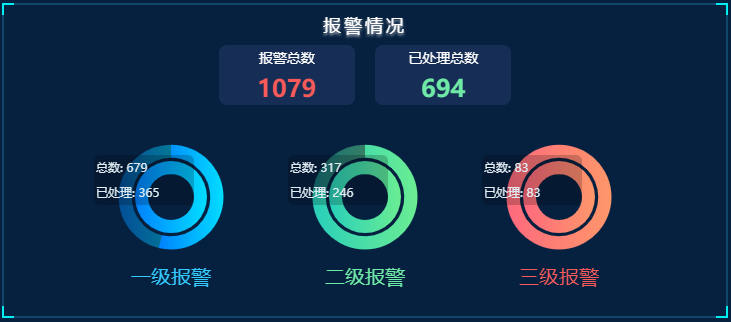
数据存储
A市智慧环保物联网应用项目由于资源紧张,信息中心在项目前期只能提供廉价的机械硬盘形式的物理存储服务器,后期将采购高性能的SSD固态硬盘用于扩展数据存储。项目团队鉴于实际情况,在项目建设过程中充分利用TDengine存储结构的优势,对每张生态环境数据表(如站点监测秒级数据表、废水废气监测秒级数据表)维护索引,保存每个数据块在文件中的偏移量,起始时间、数据点数、压缩算法等信息。
每个数据文件设置为保存一周时间的数据。这样一来一个表的数据会分布在多个数据文件中。查询时,根据给定的时间段,TDengine将计算出查找的数据会在哪个数据文件,然后进行读取,这样大幅减少了硬盘操作次数。多个数据文件的设计还有利于数据同步、数据恢复、数据自动删除操作,更有利于数据按照新旧程度在不同物理介质上存储。
例如:历史的生态环境数据存放在大容量但慢速的机械硬盘上,而新的数据则存储在高性能的SSD固态硬盘上。通过TDengine这样的存储设计,TDengine能够将硬盘的随机读取几乎降为零,从而大幅提升环境监测数据的写入和查询效率,让TDengine即便在很廉价的存储设备上也能有着超强的性能。
总结
经过了一段时间的生产环境应用,对TDengine各项指标的表现非常满意,现已完全满足我公司智慧环保项目海量时间序列监测数据存储和计算。但希望后期版本可以支持对历史数据修改(实际用户会对分钟级、小时级监测数据进行修正),以及支持Schema动态调整或无需定义的支持。
来源 https://www.modb.pro/db/168899
