来自NSDI 2019《Exploiting Commutativity For Practical Fast Replication 》的 idea,主要工作是对数据多副本一致性复制协议latency的优化,觉得有点意思,在这里分享给大家,*压压惊*,毕竟近江湖腥风血雨,不太平。
1. Introduce
为了保证分布式系统数据的可靠性和可用性,通常数据会保存多个副本,多个副本就必定有数据一致性的问题,而关键就是如何实现副本数据的复制,当前主流的解决方案就是(1)基于强Leader的数据一致性复制协议,例如raft或者multi-paxos,它们都是基于RSM的Leader-Follower复制模型,如下图[2]:

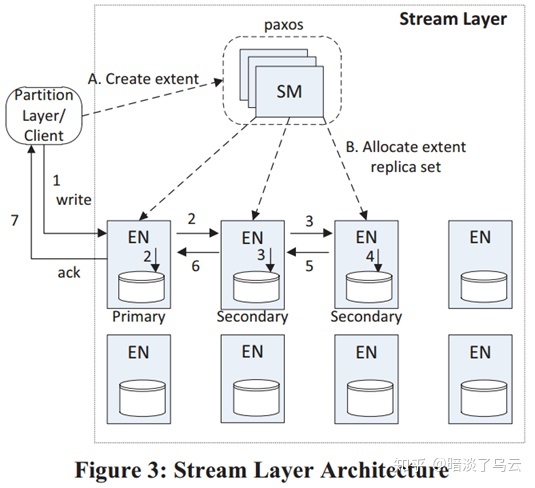
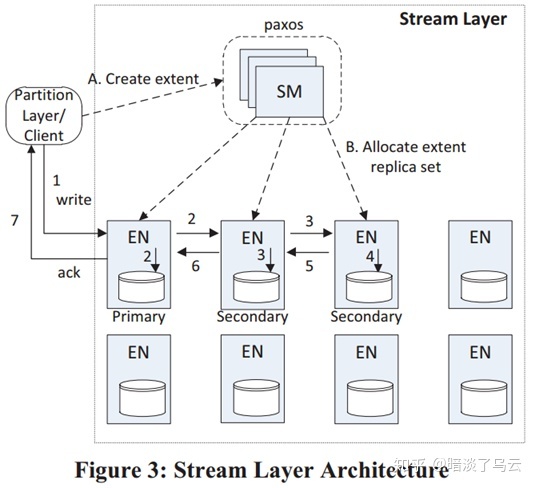
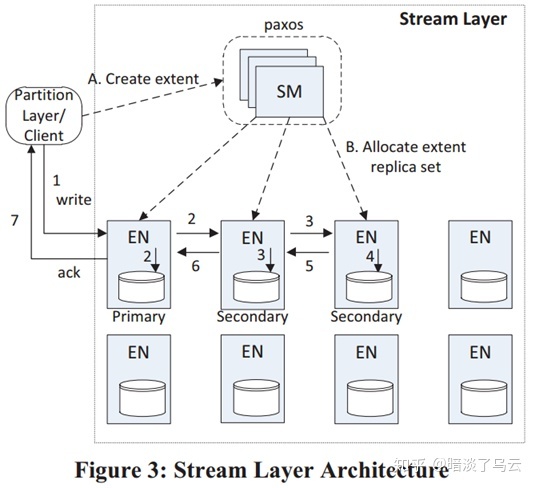
一个request从client端到Leader,Leader再发送给Follower,等到大多数返回,就可以返回client端,网络上的延迟在2RTT。还有一些基于(2)链式复制,例如window azure storage[3]的Stream Layer,则采用如下图的链式复制模式,client端的数据先到Primary,然后在发给secondary 1,secondary 1落盘同时再发送给secondary 2,然后secondary 2落盘返回secondary 1成功,secondary 1自己落盘成功且secondary 2返回成功,那么就返回Primary,后由Primary返回client,实际上这是一个带有pipeline复制优化的链式复制,其网络的延迟>2rtt,<3rtt。(更多的讨论和总结可以参考文献[2])

一个是2rtt,一个是2个多rtt,那么有没有什么复制模型,能1rtt搞定,并且能够满足可靠性,可用性和一致性呢?今天就给大家分享的NSDI 2019《Exploiting Commutativity For Practical Fast Replication 》在这方面的探索,这篇文章来自斯塔福大学 RAMCloud group and Platform Lab,他们提出了一种Consistent Unordered Replication Protocol (CURP) 的方案,可以实现在大多数的请求能够在1rtt网络延迟中完成。
2. CURP Protocol
2.1. Idea
对于Consistent replication protocols重要无非两点:
- Consistent Ordering: all replicas should appear to execute operations in the same order
- Durability: once completed, an operation must survive crashes
传统的一致性复制协议(例如raft/multi-paxos等)都会满足以上两点,而往往满足以上两点,意味着性能会遇到一些问题,所以前有multi-paxos基于类似pipeline复制的乱序commit,但是并不能乱序apply,所以后来又有了Parallel Raft[4]通过让raft协议感知具体应用而实现乱序Apply,其实都是想在第1点上做些突破。因为持久性并没有任何妥协的余地,而乱序可以在应用具体场景感知的情况下实现,CURP这次也不例外,其Exploiting Commutativity让Ordering可以延迟确定,所谓的Commutativity就是两个Op request之间没有依赖关系,例如操作不同的object,操作的不同key-value,那么这两个Op的顺序自然可以交换,也就是可以乱序,CURP就是利用这一点,在复制模型上做了一些设计,从而实现了1rtt的网络延迟。
2.2. Overview of CURP
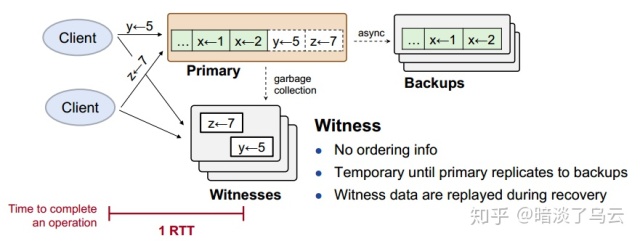
如上图所示,为CURP的整体结构,其主要由4部分组成:
- client:负责接收到一个op request,会发送给primary和witnesses,等到primary和witnesses都返回成功了,那么op request就成功了
- primary:也就是副本的leader,primary收到client的request,会立马返回执行结果,然后异步的复制给backups
- backups:其它副本,接收primary的数据复制
- witnesses:接收client的op request,如果此op和witness上已经保存的所有Op都满足
Commutativity特性,那么就持久化之后返回成功,否则返回reject;一旦client收到reject,就会给primary发送sync rpc,这个时候,primary会sync数据到backups,大多数backups返回之后,才会返回client端成功,如下图:
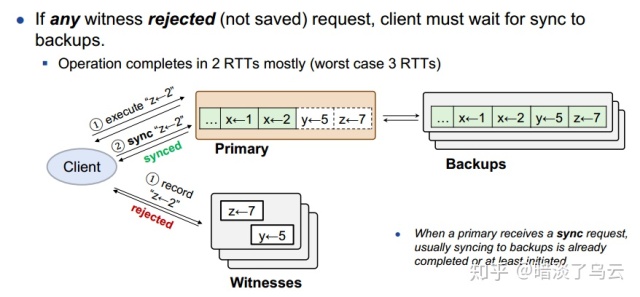
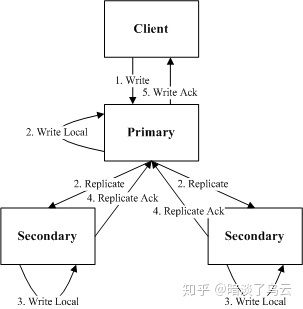
通过上面的描述,不难发现,如果一个op request和witness上的所有数据都是没有冲突可Commutativity,那么client端返回成功response仅仅需要1 rtt。
2.3. Crash Recovery
下面就分析一下,CURP如何做Crash Recovery,如下图,假设Leader挂了,那么其恢复步骤如下:
- 选出新的Leader,从backup中恢复数据,显然primary向backup复制数据是异步的,仅仅从backup恢复数据是不够的,所以需要进行第二步
- 从witness回放数据,也就是从witness上获取所有的数据,然后回放
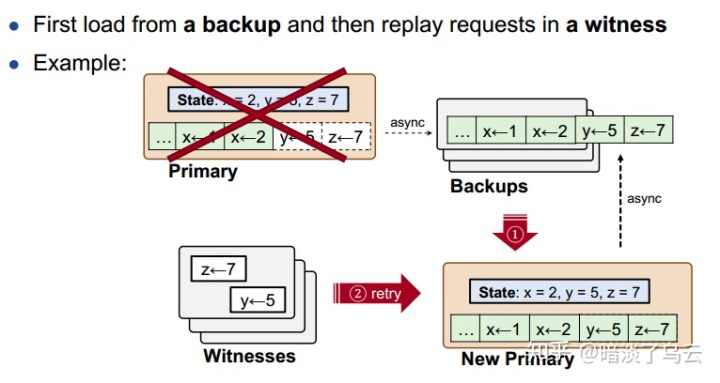
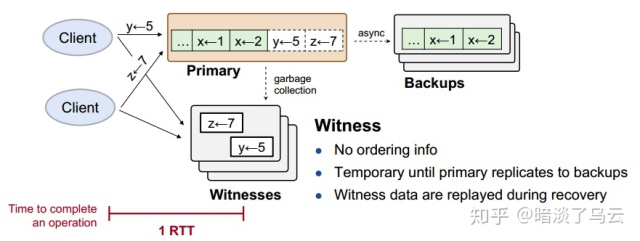
显然witness上面的数据并没有顺序,但是没有关系,因为我们之前存放在witness上面的数据就是没有任何冲突可Commutativity。是不是很巧妙。
这里实际上还需要解决一个问题,那就是线性化语义[5]:
linearizable semantics (each operation appears to execute instantaneously, exactly once, at some point between its invocation and its response)
也就是一个op request不能被重复执行,因为witness上replay的数据,可能在backups上面已经恢复过了,这个其实是实现lineariazble的一个共性问题,raft[5]论文和client交互的章节有描述,这里不在赘述。
这里实际上就是利用Commutativity,在满足持久性的同时,实现了Ordering defer。
2.4. Consistent Reads
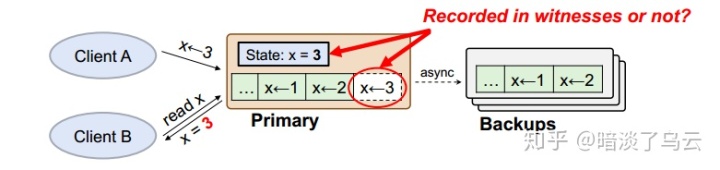
如上图所示,因为Primary复制数据给Backups是异步的,所以Primary上总是会有一些数据已经synced到了backups,一些unsynced到backups,那么这个时候来了一个read,Primary该如何处理呢?
为了保证一致性,如果op和unsynced的任何一个op有冲突不可Commutativity,那么Primary必须等到此Op已经synced到backups之后,才能返回,因为如果Primary返回了unsynced的Op,那么将有可能在Primary crash的时候出现不一致,例如,一个write x=4的op1 unsynced到backsup,来了一个read x的op2,如果op2直接返回x=2,此时Leader挂了,那么可能write x=4在backups和witness上面都没有,从而返回Not-yet-durable Data,显然这样就正确了。
3. Summary
CURP充分利用Commutativity实现了Order defer,实现了一些场景的latency降低,也算是一种全新的思路。限于时间,没有将论文中更多内容整理展示出来,例如,配置变更,从Follower read,witness gc等等,感兴趣的可以详细参考论文。
Notes
限于作者水平,难免有理解和描述上有疏漏或者错误的地方,欢迎共同交流;部分参考已经在正文和参考文献中列表注明,但仍有可能有疏漏的地方,有任何侵权或者不明确的地方,欢迎指出,必定及时更正或者删除;文章供于学习交流,转载注明出处
参考文献
[1]. Park S J, Ousterhout J. Exploiting Commutativity For Practical Fast Replication[C]//16th {USENIX} Symposium on Networked Systems Design and Implementation ({NSDI} 19). 2019: 47-64.
[2]. Replication Model. https://github.com/brpc/braft/blob/master/docs/cn/replication.md
[3]. Calder B, Wang J, Ogus A, et al. Windows Azure Storage: a highly available cloud storage service with strong consistency[C]//Proceedings of the Twenty-Third ACM Symposium on Operating Systems Principles. ACM, 2011: 143-157.
[4]. Cao W, Liu Z, Wang P, et al. PolarFS: an ultra-low latency and failure resilient distributed file system for shared storage cloud database[J]. Proceedings of the VLDB Endowment, 2018, 11(12): 1849-1862.
[5]. Ongaro D, Ousterhout J. In search of an understandable consensus algorithm[C]//2014 {USENIX} Annual Technical Conference ({USENIX}{ATC} 14). 2014: 305-319.
