使用flink做实时数仓的公司越来越多了,浪尖这边也是很早就开发了一个flink 全sql平台来实现实时数仓的功能。说到实时数仓,两个表的概念大家一定会知道的:事实表和维表。
在实时数仓中,事实表就是flink消费的kafka的topic数据流,而维表和离线数仓一样,就是mysql等外部存储的维表。
当flink 事实表需要 使用维表来进行染色的时候,就需要flink 与维表进行join,这是需要注意与外部系统的通信延迟不会影响流应用程序的整体工作。
直接访问外部数据库中的数据,例如在MapFunction中,通常意味着同步交互:向数据库发送请求,并且MapFunction等待直到收到响应。在许多情况下,这种等待占据了函数的绝大部分时间。
为了解决这个问题flink支持了异步IO的操作,与数据库的异步交互意味着单个并行task的实例可以同时处理许多请求并同时接收响应。这样,可以通过发送其他请求和接收响应来覆盖等待时间。至少,等待时间在多个请求上均摊。这会使得大多数情况下流量吞吐量更高。
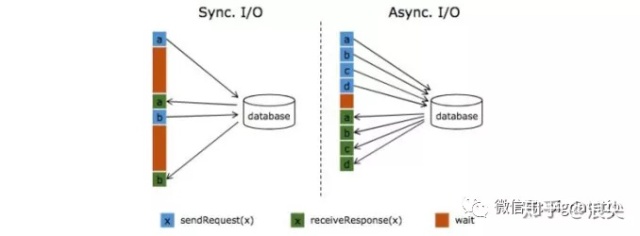
关于异步IO要关注的点,主要是:
- 有序IO的API。orderedWait请求的顺序和返回的顺序一致。
- 无序IO的API。unorderedWait,主要是请求元素的顺序与返回元素的顺序不保证一致。
问浪尖比较多的还有两个参数含义:
- Timeout。请求超时时间。
- Capacity。同时运行的大异步请求数。
企业中常用的维表存储慢的都是mysql,pg等数据库,也有为了提升速度使用redis的,浪尖这里主要给出一个基于redis的案例。使用的包主要是:
<dependency>
<groupId>io.vertx</groupId>
<artifactId>vertx-core</artifactId>
<version>3.5.2</version>
</dependency>
<dependency>
<groupId>io.vertx</groupId>
<artifactId>vertx-redis-client</artifactId>
<version>3.5.2.CR3</version>
</dependency>
完整的案例:
package org.datastream.AsyncIO;
import io.vertx.core.Vertx;
import io.vertx.core.VertxOptions;
import io.vertx.redis.RedisClient;
import io.vertx.redis.RedisOptions;
import net.sf.json.JSONObject;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.AsyncDataStream;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.async.ResultFuture;
import org.apache.flink.streaming.api.functions.async.RichAsyncFunction;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer010;
import org.datastream.watermark.KafkaEventSchema;
import java.util.Collections;
import java.util.List;
import java.util.Properties;
import java.util.concurrent.TimeUnit;
/*
关于异步IO原理的讲解可以参考浪尖的知乎~:
https://zhuanlan.zhihu.com/p/48686938
*/
public class AsyncIOSideTableJoinRedis {
public static void main(String[] args) throws Exception {
// set up the streaming execution environment
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 选择设置事件事件和处理事件
env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9093");
properties.setProperty("group.id", "AsyncIOSideTableJoinRedis");
FlinkKafkaConsumer010<JSONObject> kafkaConsumer010 = new FlinkKafkaConsumer010<>("jsontest",
new KafkaEventSchema(),
properties);
DataStreamSource<JSONObject> source = env
.addSource(kafkaConsumer010);
SampleAsyncFunction asyncFunction = new SampleAsyncFunction();
// add async operator to streaming job
DataStream<JSONObject> result;
if (true) {
result = AsyncDataStream.orderedWait(
source,
asyncFunction,
1000000L,
TimeUnit.MILLISECONDS,
20).setParallelism(1);
}
else {
result = AsyncDataStream.unorderedWait(
source,
asyncFunction,
10000,
TimeUnit.MILLISECONDS,
20).setParallelism(1);
}
result.print();
env.execute(AsyncIOSideTableJoinRedis.class.getCanonicalName());
}
private static class SampleAsyncFunction extends RichAsyncFunction<JSONObject, JSONObject> {
private transient RedisClient redisClient;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
RedisOptions config = new RedisOptions();
config.setHost("127.0.0.1");
config.setPort(6379);
VertxOptions vo = new VertxOptions();
vo.setEventLoopPoolSize(10);
vo.setWorkerPoolSize(20);
Vertx vertx = Vertx.vertx(vo);
redisClient = RedisClient.create(vertx, config);
}
@Override
public void close() throws Exception {
super.close();
if(redisClient!=null)
redisClient.close(null);
}
@Override
public void asyncInvoke(final JSONObject input, final ResultFuture<JSONObject> resultFuture) {
String fruit = input.getString("fruit");
// 获取hash-key值
// redisClient.hget(fruit,"hash-key",getRes->{
// });
// 直接通过key获取值,可以类比
redisClient.get(fruit,getRes->{
if(getRes.succeeded()){
String result = getRes.result();
if(result== null){
resultFuture.complete(null);
return;
}
else {
input.put("docs",result);
resultFuture.complete(Collections.singleton(input));
}
} else if(getRes.failed()){
resultFuture.complete(null);
return;
}
});
}
}
}