
近日,MIT 计算科学与人工智能实验室 CSAIL 宣布下架一个高引用的用于训练人工智能系统的数据集。因为该数据集带有一定偏见问题,其在训练时可能使用涉及种族主义、女性歧视和其他有问题的术语。
据悉,该训练数据集创建于 2008 年,包含 8000 万张图像。其中包括一个更小版本的图像集(Tiny Images),有 220 万张图片,可以从 CSAIL 网站上搜索和阅读。这个包括 220 万图像的可视化数据库,连同完整的可下载数据库,在周一从 CSAIL 网站上被移除。
该数据集主要用以产生更先进、的物体检测技术,能够教会机器学习模型自动识别和列出静态图像中描绘的人和物体。
本质上,它是一个巨大的照片集合,图片带有描述性的标签,所有这些标签都可以输入到神经网络中,教会它们将图片的模式与描述性标签联系起来。不过,该系统可能会对女性、黑人和亚洲人使用侮辱性语言。该数据库还包含女性隐私部位的特写照片,这些照片上标有“c”字。
应用程序、网站和其他依赖于使用 MIT 数据集训练的神经网络产品在分析照片和摄像机镜头时可能终会使用这些术语。
这个数据集与 ImageNet 训练集一起被用来作为计算机视觉算法的基准。不过,与知名度更高的 ImageNet 不同的是,在此之前,还没有人对这个图像数据集中有问题的内容进行仔细检查过。
硅谷隐私初创公司 UnifyID 的首席科学家 Vinay Prabhu 和爱尔兰都柏林大学的博士候选人 Abeba Birhane 仔细研究了 MIT 的数据库后发现,数千张图片的标签上带有对黑人和亚洲人的种族主义辱骂,以及用于描述女性的贬义词汇。
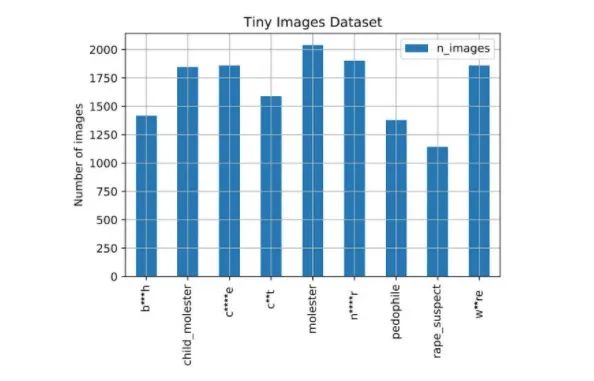
该图显示了MIT数据集中标有所选问题单词的图片数量。
他们在一篇提交给明年计算机视觉会议的论文中提到了一些细节,例如黑人和猴子的图片标有“n”字;用粗糙的术语标注解剖部分等。这类图像不必要将日常情景与侮辱性语言联系起来,并将偏见植入未来的人工智能模型中。

这是220万张图像数据集的可视化截图。这里展示了一些数据集的“妓女”标签示例,出于法律和伦理原因,我们对其进行了马赛克处理。这些照片包括一个女人,一个母亲抱着她的孩子和圣诞老人的头像照,色情女演员和一个穿比基尼的女人等……
CSAIL 的电子工程和计算机科学教授 Antonio Torralba 对问题数据集做出回应。他表示,实验室根本没有意识到数据集中存在这些冒犯性的图像和标签。“我们真诚地道歉,并将数据集下线,以删除违规图片和标签”。
在随后的一份声明中,CSAIL 表示道歉,并作出了下架涉事数据集的决定。
引起我们注意地是,Tiny Images 图像数据集包含一些贬义词分类和冒犯的图像。这是依赖于 WordNet 中的名词自动数据收集过程的结果。我们对此非常关注,并向可能受到影响的人们道歉。
由于数据集太大 (8000 万幅图像),而图像太小 (32 x 32 像素),人们很难从视觉上识别其内容。因此,人工检查,即使可行,也不能保证令人反感的图像被完全删除。因此,我们决定正式撤销数据集。它已脱机,并且不会重新联机。我们要求社区将来不要使用它,并删除可能已下载的数据集的任何现有副本。
CSAIL 实验室承认,他们在没有检查是否有攻击性图片或语言的情况下,从互联网上自动获取了这些图片。
Vinay Prabhu 和 Abeba Birhane 在研究论文中也提到,这些图像是从谷歌图像中被抓取来的,排列在 75000 多个类别中。
这个数据集包含 53464 个不同的名词,都是直接从 WordNet 拷贝过来的。普林斯顿大学将英语单词分类成相关集的数据库,然后这些系统就会自动从当时的互联网搜索引擎上下载相应名词的图片,并使用当时可用的过滤器来收集 8000 万张图片。
WordNet 是在 20 世纪 80 年代中期在普林斯顿大学的认知科学实验室中创建的,这个数据库基本上绘制了单词之间是如何关联的。不过,WordNet 中的一些名词中带有种族主义俚语和侮辱性词汇。
几十年后的今天,很多学者和开发人员将其作为方便的英语词汇仓库。构建巨大的数据集时,需要某种结构,在这种情况下,WordNet 提供了一种行之有效的方法,为计算机视觉研究人员分类和标签他们的图像。
伴随着 WordNet 的广泛使用,其包含的问题术语也困扰着现代机器学习。
作为一个单词列表,WordNet 本身可能没那么有害,不过当与图像和 AI 算法结合在一起时,它可能会产生令人不安的后果。正如 Abeba Birhane 所说:“WordNet 项目的目的是绘制出彼此接近的单词,但当你开始把图片和这些词联系起来时,你其实是在把一个真实的人的照片和那些有害的词语联系起来,这些词语会使人们的成见根深蒂固。”
ImageNet 也存在同样的问题,因为它也是使用 WordNet 进行注释的。
在这些巨大的数据集中,有问题的图像和标签所占的比例很小,很容易被当作异常现象而不予理会。然而,Vinay Prabhu 和 Abeba Birhane 认为,如果这些材料被用于训练现实世界中使用的机器学习模型,可能会造成真正的伤害。”缺乏对权威数据集的关键参与,会对女性、种族和少数民族以及处于社会边缘的弱势个体和社区造成不成比例的负面影响。”
这些群体在 AI 训练数据集中往往没有得到很好的表示。这也是人脸识别算法在识别女性和肤色较深的人时遇到困难的原因。今年早些时候,底特律的一名黑人因被面部识别软件误认为小偷嫌疑人,而被警察错误逮捕。
“人们不会考虑这些模型将如何应用,或者它可以用于什么。“他们只是想‘哦,这是我能做的很酷的事情’。但当你开始深入思考时,你就会发现所有这些潜在的目的,并看到这些危害是如何显现的”,Birhane 说。
像 ImageNet 这样的大型数据集和 8000 万张小图片也经常在未经人们明确同意的情况下,通过从 Flickr 或谷歌图片上抓取图片来收集。Facebook 就雇佣了一些“演员”,这些“演员”同意将自己的面孔用于一个数据集,该数据集是为了教软件检测电脑生成的伪造图像。
Prabhu 和 Birhane 认为,社交网络的方法是一个好主意。学术研究不太可能有资金支付训练数据。“我们承认,没有完美的解决方案来创建一个理想的数据集,但这并不意味着人们不应该尝试创建更好的数据集。
二人建议模糊数据集中的人脸识别,仔细筛选图像和标签以去除任何冒犯性的内容,甚至使用真实的合成数据来训练系统。
MIT 的行动表明,这场由美国黑人跪杀事件而引发的反种族歧视浪潮进一步蔓延到了学术界。
近日,反种族歧视的抗议在美国科技界愈演愈烈,多位科技圈大佬受到了波及。
6 月 29 日,图灵奖得主、Facebook 首席 AI 科学家 Yann Lecun 宣布,自己将退出推特。在做出这一决定之前,他在推特上已经经历了长达 2 周的“骂战”,这令他不堪其扰。“骂战”争执的焦点在于带有种族歧视倾向的 PULSE 算法引起争议,而 Yann Lecun 被指责为其辩护。
PULSE 算法由美国杜克大学科研团队提出。该算法能够将 16x16 像素的马赛克人脸图像,转换为 1024x1024 的高清图像,分辨率提升高达 64 倍。新生成的人脸,毛孔、皱纹甚至一缕头发等细节都清晰可见,足以以假乱真。本质上,该算法是运用了“对抗生成网络”(StyleGAN)工具,生成了看上去真实但实际上并不存在的人脸。
热度刚起来没多久,就有人发现了 PULSE 算法存在的巨大漏洞。有网友发现,输入模糊的奥巴马照片,输出时却变成了一张白人面孔,而同样输入其他黑人或亚裔人的模糊人脸图像,输出的无一例外都是白人头像。这招致了广泛的批评,ULSE 算法被指带有严重的种族歧视倾向。
争议四起之时,Yann LeCun 发了一条推特分析 PULSE 为什么会出现这样的偏见 — 因为训练数据集存在数据偏差。
没想到却意外“引火烧身”,Yann LeCun 的言论引起了不少科技界人士的不满,他们认为,Yann LeCun 对于“AI 的公平性”的 理解过于片面。
后来,Yann LeCun 连发 17 条推文解释自己的立场,但反对者并不买账。后只能无奈宣布退出推特。
Yann Lecun 之后,谷歌 AI Jeff Dean 紧接着成为了下一个卷入风波的大佬。
事情的起因很有意思。哥伦比亚大学的一位黑人女性研究员、PresGAN 作者 ,Adji B. Dieng 因为 DeepMind 举办的一场 GAN 普及课程中没有提及她的研究成果 PresGAN 而感到不满,她认为其成果之所以被无视,主要是因为她是一个黑人女性。而也是因为种族歧视在,尽管她的论文已经发表 9 个月了,但被他人引用的次数仅有 3 次。
Adji B. Dieng 在推特上发文诘问 DeepMind。有一个理性的网友 Gwern 在去看了 Adji B. Dieng 的论文后发现,其论文水平不怎么样,引用次数少也在情理之中。Adji B. Dieng 也不甘示弱,她反讥 Gwern 是一个“优生主义者”。
Adji B. Dieng 还意外发现,谷歌的 AI Jeff Dean 竟然关注了 Gwern,于是她开始喊话 Jeff Dean,“你也关注了这个人,但我相信你不知道他是一个优生主义者”。就这样,什么也没做的 Jeff Dean 被卷入到了舆论旋涡中。不少人质疑,Adji B. Dieng 这波操作有点强行“碰瓷”的意思。
从 Yann Lecun 推特、Jeff Dean 无辜 “躺枪” 再到 MIT 道歉,近期在科技界密集发生的舆论风波也在一定程度上表明,这场反种族歧视浪潮似乎有些变味了,变得有些混乱了。借用 Prabhu 和 Birhane 的一个判断结束此文,从事良好的科学研究和保持伦理标准并不相互排斥。
参考链接:
https://www.theregister.com/2020/07/01/mit_dataset_removed/
