版权申明:转载请注明出处。
文章来源:kylin从入门到实战:具体案例 - 大数据随笔
排版乱?请移步原文获得更好的阅读体验
前面两篇文章已经介绍了kylin的相关概念以及cube的一些原理,这篇文章将从一个实际的案例入手,介绍如何在kylin平台上创建一个多维分析项目。
1.创建project
进入kylin操作界面,如果没有project可以创建,kylin里面可以创建多个project,有效的把各种业务数据分析隔离开来。如图:
如下,填写project name,description可以不填
然后submit 提交,project创建成功。
2.添加数据源
点击DataSource选项卡->Load Hive Table
填写hive表名,前面加上库名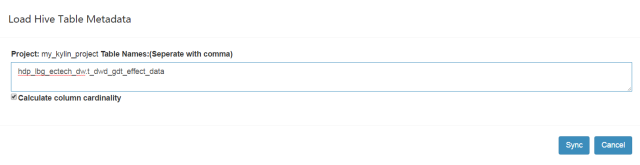
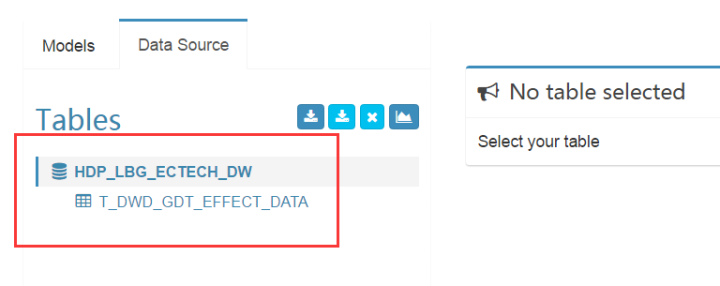
然后点击sync,导入数据源成功,可以看到如下信息:
添加model name然后 next
选择刚才添加到数据源中的事实表,如果有Lookup Table也可添加,然后next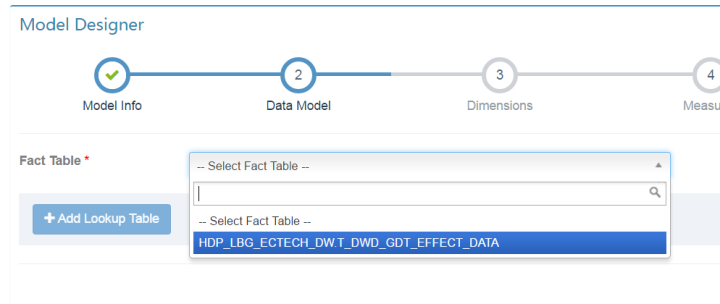
选择需要的维度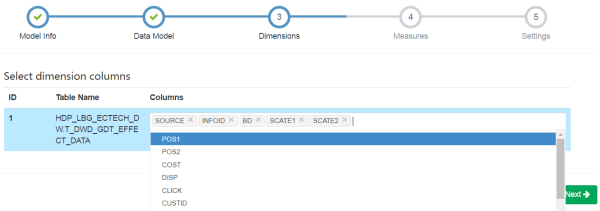
选择需要的指标
相关设置
partition date colume表示分区字段,选择hive表中按时间分区的字段。然后从date format中选择不同的时间格式。下面的filter可以添加where条件对数据源中的数据做过滤。
至此,model创建完成。
4.创建cube
下面进入关键环节创建cube。
类似于创建model,创建cube。选择之前创建好的model,并填入cube name。notification
email list是选填项,表示报警接收人邮件地址,多个邮件地址以逗号隔开。
然后next。选择dimession,有两种方式:一是手动添加dimession,二是使用自动生成,我们这里使用自动生成,然后勾选需要的字段。

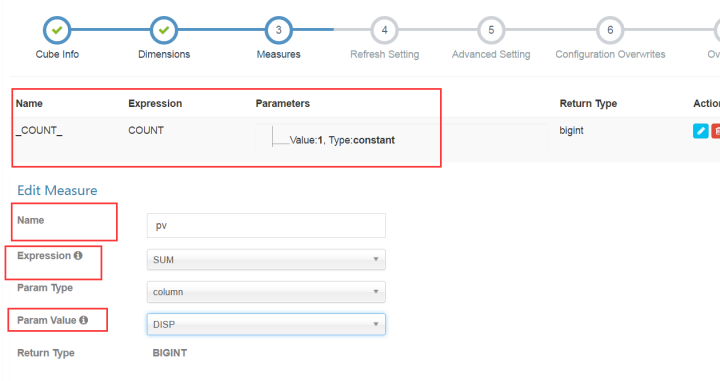
count(1)是系统默认自带的,不要删除。
点击+号添加需要的指标,需要填入名称,选择表达式。这里选择的是sum。我们要针对disp加和求pv,在param
value里面选择disp列。
需要注意的是kylin中hive表中每一列字段的类型要求比较严格。dimession字段需要为String,用来加和的指标字段须为bigint或者decimal
添加了所有需要的指标后,点击next
设置merge时间。Kylin每次build会生成一张hbase表,merge操作会把多天数据合并成一张新的hbase表。可加快查询。
设置partition Start Date,即数据源开始时间,默认为1970-01-01.点击Next.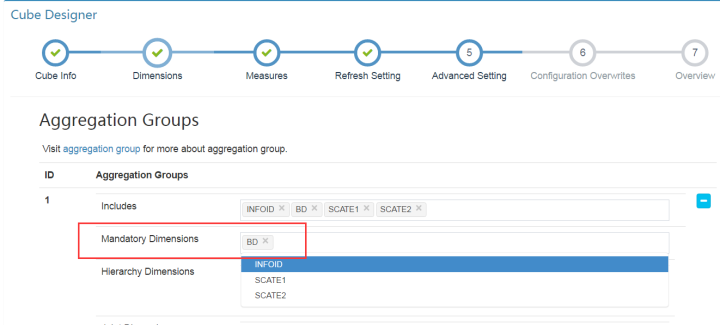
Mandatory Dimensions:每次查询均会使用的维度可添加在此。比如某些情况下的partition
column.
Hierarchy Dimensions:维度列中彼此间存在层级关系的列,比如“国家-省份-市-县”
Joint Dimensions:每次查询会同时使用或不使用的维度组合。
Aggregation Group:在不同的查询中,两组维度组合之间不会产生交叉,可选择此选项,比如所有的cube维度有 [ a,b,c,d,e,f ] 6个,每次查询中只会同时查与 [ a,b,c ] 相关的信息(比如[a],[a,c]等)而不会查询 [ d,e,f ],或者相反,则可选择此选项。
以上选择均可减少build过程中的数据量,是加快build与query速度的优化点之一。
接下来基本上就是next,然后保存,如果没有报错,则证明cube创建成功,如下图
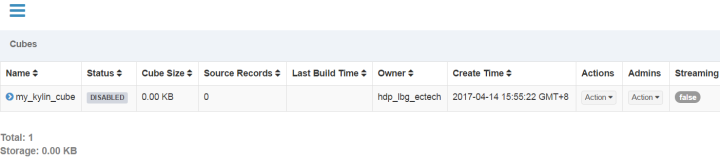
5.cube其他操作
常用的就是build操作,它会根据我们创建的cube进行数据的预计算。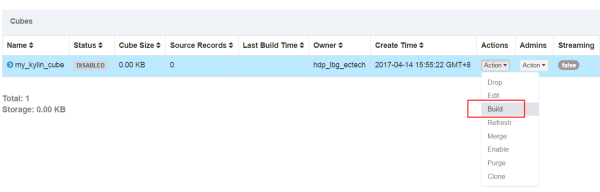
选择构建的终止时间,然后提交,之后可以在monitor中看到cube构建的状态。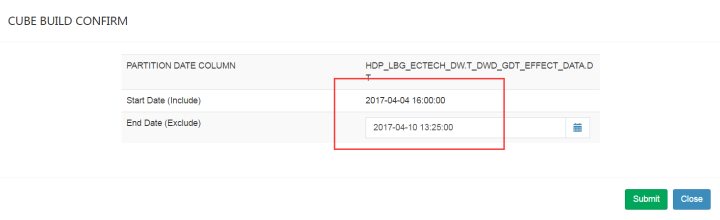
其他操作说明:
Drop:丢弃现有cube,条件:无Pending,
Running, Error 状态的job.
Edit:编辑现有cube,条件:cube需处于disable状态。
Refresh:重建某已有时间段数据,针对于已build时间段的源数据发生了改变的情况。
Merge:手动触发merge操作。
Enable:使拥有至少一个有效segment的cube从disable变为enable状态。
Purge:清空所有该cube的数据。
Clone:克隆一个新的cube,可设置新的名字,其他相关配置与原cube相同。
Disable:使一个处于ready状态的cube变为Disable状态,查询不会从disable的cube中获取数据。
6.查询操作
数据预计算完成后就可以进行查询了,查询过程中也可以验证cube创建的是否有问题。有两种查询方式:一种是通过kylin的web界面,一种是使用kylin提供的rest api。下面分别介绍。
(1)web查询。进入insight,输入sql语句,等待查询结果,和一般的数据库客户端类似。
(2)rest api。举例如下:
假如需要查询的sql语句为:“select sum(disp)
as pv from t_table group by td,bd”
kylin账户的账号密码为:“kylinid:passwd”,对其进行base64加密。secret=echo -n
“kylin_id:password” | base64
使用的project为:my_kylin_project
接口地址为:http://localhost:7070/kylin/api/query
则请求为:
curl -X POST -H "Authorization:Basic ${secret}" -H "Content-Type:application/json" -d '{ "sql" : "select sum(disp) as pv from t_table group by td,bd", "project" : "my_kylin_project" }' http://localhost:7070/kylin/api/query更多文章请关注微信公众号:bigdataer
